
a16z: Amnesia untuk AI, dapat terus belajar "menyembuhkan" itu
Terobosan adalah hal yang membuat model menjadi kuat ketika mereka dikerahkan dan dilatih: kompresi, abstraksi, pembelajaran。

Judul asli:
Original by Malika Aubakirova, Matt Bornstein, a16z crypto
Bahasa asli: TecFlow Deep Tide
Dalam Memento Christopher Nolan, aktor terkemuka, Leonard Shelby, hidup dalam keadaan rusak. Kerusakan otak menyebabkan dia menderita penundaan dan kehilangan memori baru. Setiap beberapa menit, dunianya kembali, terjebak dalam abadi "pada saat ini" - mengingat apa yang baru saja terjadi dan bertanya-tanya apa yang akan terjadi. Untuk bertahan hidup, ia telah menulis dan difilmkan tubuhnya untuk menggantikan fungsi memori bahwa otak tidak dapat melakukan。
Model bahasa besar hidup di zaman abadi yang sama. Setelah pelatihan, massa pengetahuan dibekukan dalam parameter, dan model tidak menciptakan kenangan baru dan tidak memperbarui parameter mereka dalam cahaya pengalaman baru. Untuk mengisi kesenjangan ini, kami menaruhnya di scaffolds: riwayat obrolan sebagai handprint jangka pendek, sistem pengambilan sebagai notebook eksternal, petunjuk sistem sebagai tato. Tapi model itu sendiri tidak pernah benar-benar internalisasi informasi baru ini。
SEJUMLAH PENELITI MENGANGGAP HAL INI TIDAK CUKUP. PEMBELAJARAN CONTEXT (ICL) MEMECAHKAN MASALAH JIKA JAWABAN (ATAU FRAGMEN DARI JAWABAN) SUDAH ADA DI BEBERAPA BAGIAN DUNIA. TAPI ADA ALASAN YANG BAIK MENGAPA MODEL MEMBUTUHKAN CARA UNTUK MEMASUKKAN PENGETAHUAN BARU DAN PENGALAMAN LANGSUNG DALAM PARAMETER SETELAH PENYEBARAN, UNTUK MASALAH-MASALAH YANG PERLU BENAR-BENAR DITEMUKAN (MISALNYA SERTIFIKAT MATEMATIKA BARU), UNTUK SKENARIO KONFRONTASIONAL (MISALNYA TINDAKAN KEAMANAN), ATAU UNTUK PENGETAHUAN YANG TERLALU HALUS UNTUK DIUNGKAPKAN DALAM BAHASA。
pembelajaran konteks bersifat sementara. pembelajaran nyata membutuhkan kompresi. sampai kita membiarkan model untuk terus kompres, itu mungkin terjebak dalam momen abadi memory debris. sebaliknya, jika kita dapat melatih model untuk mempelajari struktur memori mereka sendiri, daripada mengandalkan alat-alat pengubahan eksternal, kita dapat membuka dimensi skala yang sama sekali baru。
Bidang ini disebutBelajar terus-menerus(Terus belajar) Konsep ini tidak baru (lihat dokumen McCloskey dan Cohen 1989), tapi kami menganggapnya salah satu petunjuk penelitian paling penting di bidang AI saat ini. Pertumbuhan eksplosif kapasitas pemodelan selama dua sampai tiga tahun terakhir telah membuat kesenjangan antara model dikenal dan dikenal semakin jelas. Tujuan dari artikel ini adalah untuk berbagi apa yang telah kita pelajari dari peneliti terbaik di lapangan, untuk membantu mengklarifikasi jalan pembelajaran yang berbeda dan untuk berkontribusi dalam pengembangan topik ini dalam ekologi kewirausahaan。
Catatan: Bentuk artikel ini diuntungkan dari pertukaran intensif dengan sekelompok peneliti yang sangat baik, mahasiswa doktor dan wirausahawan yang secara murah hati berbagi pekerjaan dan wawasan mereka dalam bidang pembelajaran terus menerus. Dari dasar teoritis hingga realitas rekayasa pembelajaran post- penyebaran, wawasan mereka telah membuat artikel lebih padat daripada yang kita tulis sendiri. Terima kasih atas waktu dan pikiran kalian
Mari kita mulai dengan konteks
Sebelum mempertahankan pembelajaran tingkat-tingkat-tinggi (misalnya belajar model pembaruan), perlu untuk mengakui fakta bahwa pembelajaran konteks berhasil. Dan ada argumen kuat bahwa itu akan terus menang。
Inti dari Transformer adalah prosektor token berikutnya berdasarkan kondisi urutan. Berikan urutan yang tepat, Anda mendapatkan perilaku luar biasa kaya, dan Anda tidak perlu menyentuh berat badan. Itulah sebabnya manajemen konteks, tips, instruksi fine- tuning dan beberapa contoh contoh contoh begitu kuat. Smart encapsulasi adalah dalam parameter statis, dan kemampuan untuk menunjukkan perubahan secara dramatis saat Anda makan ke jendela。
Artikel yang baru-baru ini mendalam oleh Cursor mengenai pemrograman otonom skala adalah contoh yang baik: bobot model sudah tetap, dan apa yang membuat sistem berjalan adalah tata letak yang baik dari konteks - apa yang harus dimasukkan, kapan untuk meringkas, bagaimana mempertahankan konsistensi dalam beberapa jam operasi otonom。
OpenClaw adalah contoh yang baik. Ini tidak meledak karena hak istimewa model khusus (yang tersedia untuk semua di bagian bawah), tetapi karena mengubah konteks dan alat ke dalam kondisi kerja dengan efisiensi yang besar: pelacakan apa yang Anda lakukan, struktur perantara, memutuskan kapan untuk memperkenalkan kembali, dan mempertahankan memori abadi dari pekerjaan sebelumnya. OpenClaw mengangkat "desain shell" dari kecerdasan untuk disiplin independen。
Ketika mendorong proyek pertama kali muncul, banyak peneliti skeptis tentang fakta bahwa "iklan saja" bisa menjadi antarmuka yang tepat. Sepertinya jack. Namun, ini adalah produk asli dari arsitektur Transformer, tidak memerlukan pelatihan ulang dan secara otomatis ditingkatkan sebagai kemajuan model. Model semakin kuat, petunjuk semakin kuat. Antarmuka "sederhana tapi primitif" sering menang karena terhubung langsung ke sistem bawah, bukan ke sana. Sejauh ini, LLM lintasan persis itu。
Model spasial state: Steroid versi konteks
MODEL PEMBELAJARAN KONTEKS BERADA DI BAWAH PENINGKATAN TEKANAN SEBAGAI ARUS UTAMA BERGERAK DARI LLM ASLI KE PEREDARAN CERDAS. DI MASA LALU, CUKUP JARANG BAGI JENDELA KONTEKS UNTUK DIISI PENUH. HAL INI BIASANYA TERJADI KETIKA LLM DIMINTA UNTUK MELAKUKAN BARIS PANJANG DARI TUGAS-TUGAS DISKRIT, DAN LAPISAN APLIKASI DAPAT MEMOTONG DAN MENGKOMPRES RIWAYAT PERCAKAPAN SECARA LEBIH LANGSUNG。
Tapi untuk tubuh yang cerdas, sebuah misi mungkin makan bagian besar dari konteks yang selalu tersedia. Setiap langkah siklus cerdas tergantung pada konteks di mana urutan pertama dilewati. Dan mereka sering gagal 20 sampai 100 langkah kemudian, karena garisnya rusak: konteksnya penuh, konsistensi menurun, dan tidak dapat dikendalikan。
Akibatnya, laboratorium AI utama sekarang memberikan sumber daya yang signifikan (yaitu operasi pelatihan skala besar) untuk mengembangkan model untuk jendela konteks yang sangat panjang. Ini adalah jalur alami, karena didasarkan pada metode yang sudah efektif (belajar dalam konteks) dan sejalan dengan kecenderungan umum industri untuk beralih ke penalaran. Struktur yang paling umum adalah lapisan memori tetap, yaitu sebuah model spasial (SSM) dan varian perhatian linear (setelahnya disebut sebagai SSM), dimasukkan di antara perhatian umum. SSM menyediakan kurva skala mendasar yang lebih baik dalam konteks。
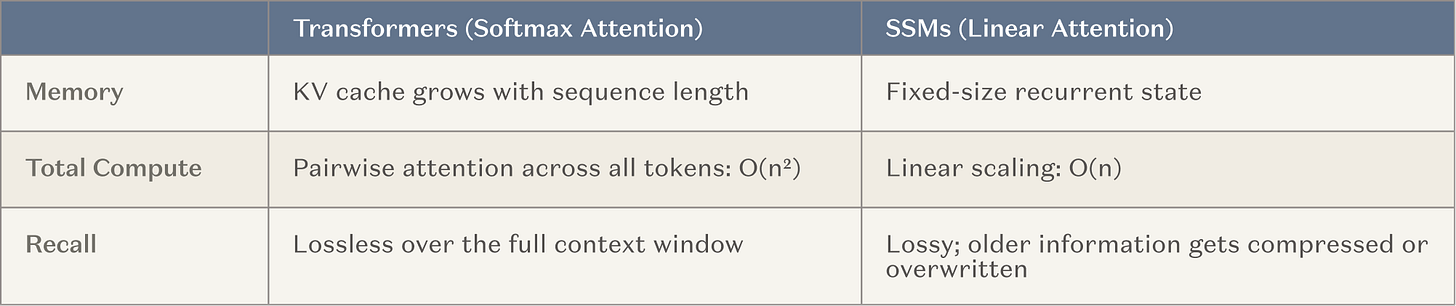
Gambar: SSM dibandingkan skala mekanisme perhatian tradisional
Tujuannya adalah untuk membantu orang cerdas meningkatkan jumlah langkah konsisten hingga beberapa perintah, dari sekitar 20 sampai 20.000, tanpa kehilangan keterampilan dan pengetahuan yang luas yang disediakan oleh Transformer tradisional. Jika berhasil, ini adalah terobosan besar bagi musuh lama。
Anda bahkan dapat melihat ini sebagai bentuk pembelajaran berkelanjutan: Meskipun bobot model tidak diperbarui, lapisan memori eksternal diperkenalkan bahwa hampir tidak diperlukan pengganti。
Jadi metode parametric non-ini adalah nyata dan kuat. Setiap penilaian pembelajaran terus menerus harus dimulai di sini. Pertanyaannya bukan apakah sistem konteks saat ini bekerja, tapi berhasil. Pertanyaannya adalah, apakah kita sudah melihat langit-langitnya, dan bisakah pendekatan baru menuntun kita lebih jauh。
Apa yang hilang dalam konteks
"AGI DAN PRA-DILATIH HAL-HAL TERJADI BAHWA, DALAM ARTI, MEREKA BERLEBIHAN... MANUSIA TIDAK AGI. YA, MANUSIA MEMANG MEMILIKI DASAR KETERAMPILAN, TETAPI MEREKA TIDAK MEMILIKI BANYAK PENGETAHUAN. KITA MENGANDALKAN PEMBELAJARAN TERUS MENERUS。
Jika saya membuat super pintar 15 tahun-anak tua, dia tahu apa-apa. Seorang mahasiswa yang baik, ingin belajar. Anda dapat mengatakan, menjadi programmer, menjadi dokter. Penyebaran itu sendiri melibatkan semacam pembelajaran, pengujian dan kesalahan. Ini adalah proses, tidak membuang produk selesai keluar. Ilya Sutskie
Bayangkan sebuah sistem dengan ruang penyimpanan tak terbatas. Setiap lemari arsip terbesar di dunia terindeks dengan baik dan dapat diakses. Dia bisa menemukan apa saja. Apakah itu belajar
Tidak ada. Ini tidak pernah dipaksa untuk melakukan kompresi。
Ini adalah inti dari argumen kita, yang mengutip sebuah titik yang dibuat sebelumnya oleh Ilya Sutskaver: LLM pada dasarnya adalah algoritma terkompresi. Dalam pelatihan, mereka memampatkan Internet ke parameter. Kompresi itu merusak, dan kerusakan seperti itulah yang membuatnya kuat. Kompresi memaksa model untuk mencari struktur, generalisasi dan konstruksi tanda yang dapat bergerak di seluruh konteks. Model dari sampel yang didukung dengan keras dari semua pelatihan bukanlah model pola bawah. Kompresi adalah belajar sendiri。
IRONISNYA, MEKANISME YANG MEMUNGKINKAN LLM MENJADI BEGITU KUAT SELAMA PELATIHAN (MENGKOMPRES DATA MENTAH MENJADI MANIFESTASI COMPACT, TRANSFERABLE) ADALAH JUSTRU APA YANG KITA MENOLAK UNTUK MEMBIARKAN MEREKA MELANJUTKAN SETELAH PENYEBARAN. KAMI MENGHENTIKAN KOMPRESI PADA SAAT ITU DAN MENGGANTINYA DENGAN MEMORI EKSTERNAL。
tentu saja, sebagian besar casing tubuh cerdas kompres konteks dalam beberapa cara. tapi bukankah pelajaran pahit yang model sendiri harus belajar untuk menekan, langsung dan pada skala besar
Yu Sun berbagi contoh perdebatan ini: matematika. Lihatlah teori Fermat. Selama bertahun-tahun, tidak ada ahli matematika yang membuktikannya, bukan karena mereka tidak memiliki literatur yang tepat, tetapi karena solusi sangat baru. Ada terlalu banyak jarak konseptual antara pengetahuan matematika dan jawaban akhir。
Andrew Wiles, ketika ia akhirnya mengambilnya di tahun 1990-an, menghabiskan tujuh tahun bekerja dalam isolasi, harus menemukan teknologi baru untuk mencapai jawabannya. Sertifikasi Nya bergantung pada jembatan sukses untuk dua cabang matematika yang berbeda: kurva elips dan bentuk model. Sementara Ken Ribet sebelumnya telah membuktikan bahwa hubungan ini secara otomatis dapat memecahkan Teori Fermatian, tidak ada yang memiliki alat teoritis untuk benar-benar membangun jembatan sebelum Wiles. Grigori Perelman bisa melakukan hal yang sama dengan bukti dugaan Pongarai。
Masalah inti adalah:Apakah contoh-contoh ini bukti bahwa LLM kurang sesuatu, beberapa kemampuan untuk memperbarui priori dan benar-benar berpikir kreatif? Atau cerita ini membuktikan sebaliknya -- semua pengetahuan manusia adalah data yang dapat dilatih dan direstrukturisasi, Wiles dan Perelman, tapi menunjukkan apa yang bisa dilakukan LLM dalam skala yang lebih besar
Pertanyaannya adalah empiris dan jawabannya tidak pasti. Tapi kita tahu bahwa ada banyak kategori isu di mana pembelajaran di bawah ini akan gagal hari ini, dan pembelajaran tingkat pareter mungkin berguna. Misalnya:

Gambar: Kegagalan belajar konteks, kemungkinan kategori masalah untuk pembelajaran parameter
Lebih penting lagi, pembelajaran konteks hanya dapat ditangani dengan apa yang dapat diekspresikan dalam bahasa, sementara bobot dapat mengkodekan konsep yang tidak dapat disampaikan dengan kata-kata. Beberapa model terlalu tinggi, terlalu tak terlihat, terlalu dalam untuk dibentuk. Sebagai contoh, dalam scan medis, tekstur visual yang membedakan nama samaran yang baik dari tekstur visual tumor, atau sedikit fluktuasi dalam audio yang mendefinisikan irama unik dari orang yang berbicara, tidak mudah rusak menjadi kosa kata yang tepat。
Bahasa hanya bisa mirip dengan mereka. Tidak lagi sebuah petunjuk dapat menyampaikan hal-hal ini; pengetahuan seperti ini hanya dapat bertahan dalam beratnya. Mereka hidup di ruang belajar tanda-tanda, bukan kata-kata. Terlepas dari pertumbuhan jendela konteks, selalu ada beberapa pengetahuan yang tidak dapat dijelaskan dalam teks dan yang hanya dapat dilakukan oleh parameter。
Hal ini dapat menjelaskan mengapa jelas "robot ingat Anda" fungsi (seperti memori ChatGPT) sering membuat pengguna tidak nyaman daripada terkejut. Pengguna benar-benar ingin tidak "ingat" tapi "kekuatan". Sebuah model yang telah menginternalisasi pola perilaku Anda dapat dipindahkan ke adegan baru; model yang hanya mengingat sejarah Anda tidak bisa. Perbedaan antara "ini adalah apa yang Anda tulis terakhir kali Anda menjawab email ini" (kata kerja berulang) dan "Saya sudah mengerti cara berpikir Anda cukup untuk memprediksi apa yang Anda butuhkan" adalah kesenjangan antara pencarian dan pembelajaran。
Pengantar ke pembelajaran terus-menerus
Ada banyak jalan untuk terus belajar. Garis pemisah bukan "tidak ada memori" tapi:Dimana kompresi terjadiJalur ini didistribusikan sepanjang spektrum, berkisar dari pencarian yang tidak dikompresi, pembekuan berat untuk kompresi internal penuh (pembelajaran berat badan, model menjadi lebih cerdas), dengan area penting (modul)。
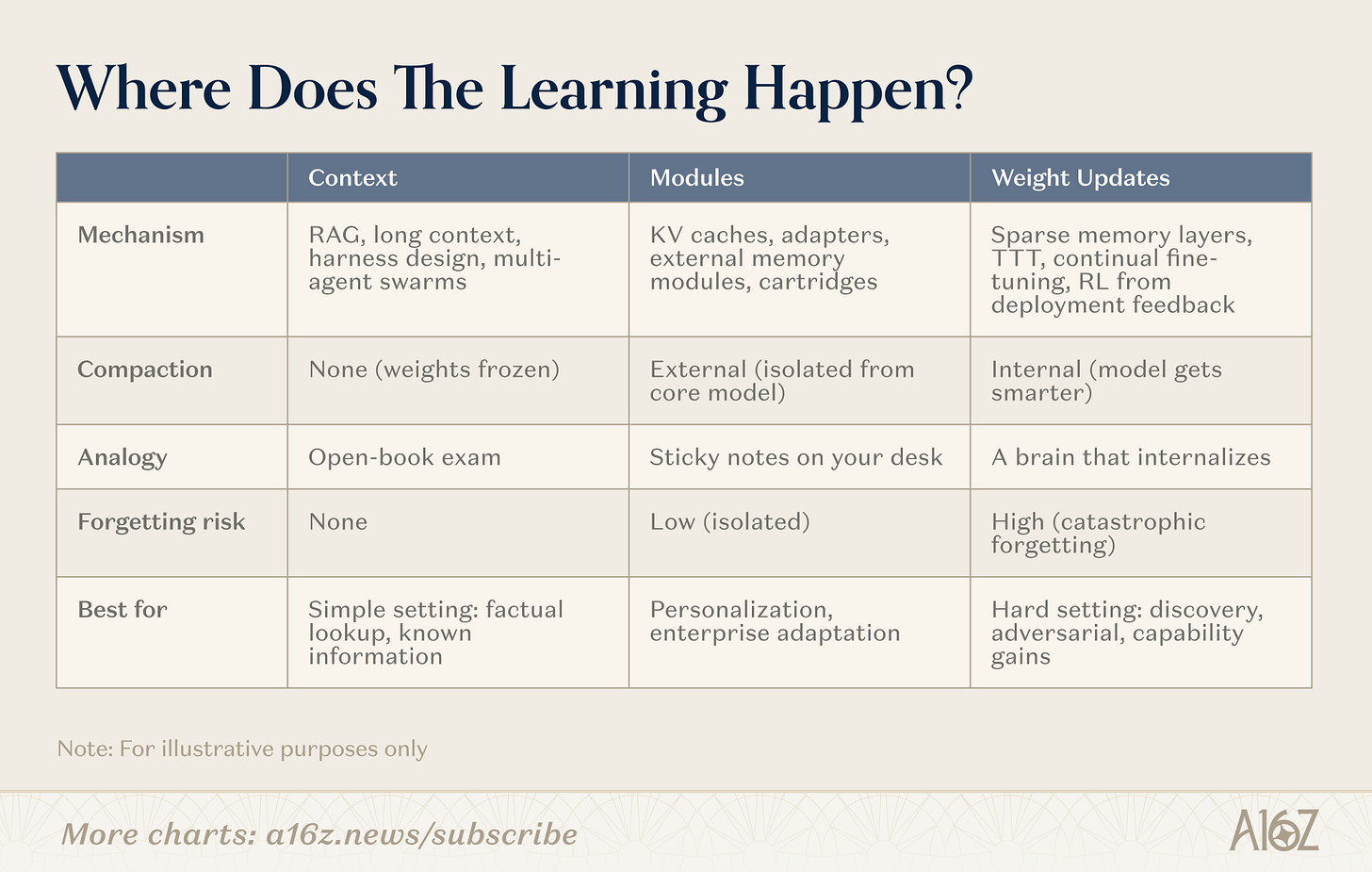
Gambar: Tiga jalur untuk pembelajaran terus menerus - konteks, modul, bobot
Konteks
Pada akhir konteks ini, tim membangun tabung pencarian lebih cerdas, casing tubuh pintar dan organisasi petunjuk. Ini adalah kategori yang paling matang: infrastruktur divalidasi dan jalur penyebaran jelas. Batas adalah kedalaman: panjang konteks。
Sebuah arah baru yang layak dicatat: Struktur Multi- Intelektual sebagai strategi skala untuk konteks itu sendiri. Jika satu model terbatas pada jendela token 128K, satu set terkoordinasi tubuh cerdas - masing-masing dengan konteksnya sendiri, sepotong tunggal terfokus pada masalah, dan hasil komunikasi masing-masing - dapat perkiraan seluruh memori kerja tak terbatas. Setiap tubuh cerdas melakukan pembelajaran konteks di jendelanya sendiri; sistem berkumpul. Contoh terbaru dari proyek autorearch Karpathy dan peramban web Cursor adalah kasus awal. Ini adalah pendekatan murni parametric (tidak mengubah bobot), tapi secara signifikan meningkatkan langit-langit bahwa sistem konteks dapat mencapai。
Modul
Dalam ruang modular, tim membangun modul pengetahuan tertanam (cache KV dikompresi, lapisan adaptor, penyimpanan memori eksternal) untuk profesional model umum tanpa pelatihan ulang. Sebuah model 8B dengan modul yang sesuai dapat cocok dengan kinerja 109B model pada tugas target, dengan menempati memori hanya sebagai pecahan. Daya tariknya adalah cocok dengan infrastruktur Transformer yang ada。
Malam
pada akhir pembaharuan berat, para peneliti mencari pembelajaran tingkat tengah yang benar: memperbarui hanya lapisan memori tipis dari segmen parameter yang relevan, mengoptimalkan siklus pembelajaran yang ditingkatkan model dari umpan balik, dan pelatihan dalam pengujian berat kompresi dalam konteks penalaran. ini adalah yang paling dalam dan paling sulit untuk disebarkan, tetapi mereka memungkinkan model untuk sepenuhnya menginternalisasi informasi atau keterampilan baru。
Ada banyak mekanisme spesifik untuk memperbarui parameter. Beberapa arah penelitian diberikan:
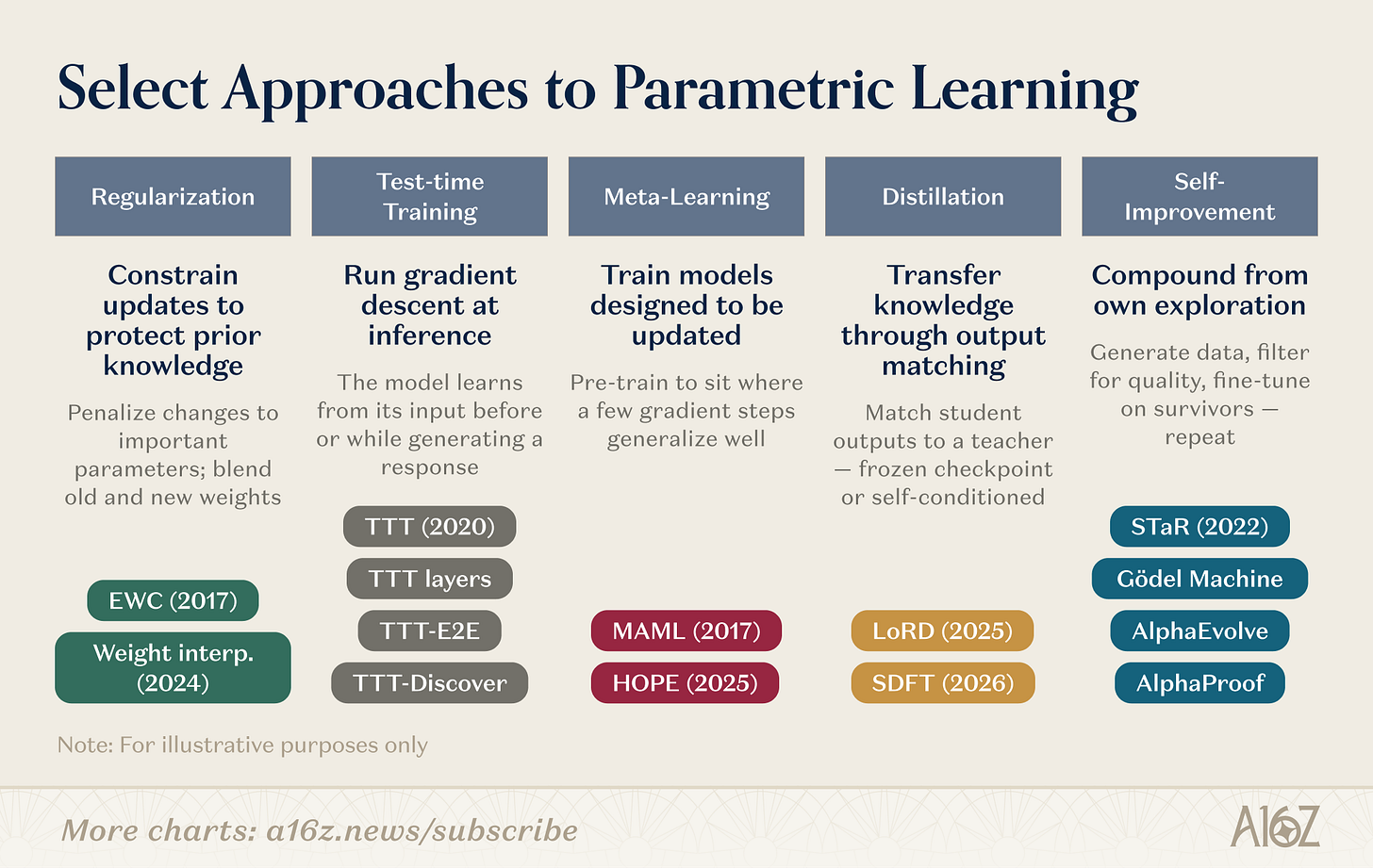
Gambar: Ringkasan arah penelitian untuk pembelajaran berat
Studi berbobot menutupi beberapa rute paralel。Regularisasi dan pendekatan spasial berbobotYang tertua: EWC (Kirkpatrick et al., 2017) menghukum parameter yang berubah berdasarkan pentingnya parameter ke tugas sebelumnya; interposisi berat (Kozal et al., 2024) menggabungkan konfigurasi berat lama dan baru dalam ruang parameter, tapi keduanya rentan pada skala besar。
Pelatihan selama pengujianDibuat oleh Sun et al. (2020), dan kemudian dikembangkan ke bahasa asli arsitektur (TTT-E2E, TTT-Discover), ide ini berbeda: untuk membuat gradien pada data tes dan mengkompres informasi baru ke parameter saat ini diperlukan。
Yuan belajarPertanyaannya adalah, bisakah kita melatih model untuk belajar belajar? Dari inisialisasi dari beberapa parameter sample- ramah dari MAML (Finn et al., 2017) ke pembelajaran tertanam Behrouz et al. (Nested Learning, 2025), yang terstruktur model menjadi masalah optimisasi lapisan, berlari cepat dan melambat-up modul pada berbagai skala waktu, terinspirasi oleh konsolidasi memori biologis。
DistilasiPengetahuan tentang tugas sebelumnya dijaga oleh model siswa yang cocok dengan pos pemeriksaan guru beku. LoRD (Liu et al., 2025) memungkinkan penyulingan beroperasi secara efisien ke titik di mana dapat dipertahankan dengan memotong model dan memainkan kembali zona penyangga secara bersamaan. Shenfeld et al. 2026) membalik sumber, menggunakan keluaran model 's sendiri di bawah kondisi ahli sebagai sinyal pelatihan, melewati memori bencana dari finetuning urutan。
Perbaikan rekursif diriIni beroperasi pada baris yang sama: STAR (Zelikman et al., 2022) panduan penalaran dari rantai penalaran yang dibuat sendiri; AlphaEvolve (DeepMind, 2025) menemukan optimisasi alitmik yang belum ditingkatkan selama beberapa dekade, Silver dan Sutton "era pengalaman" (2025) mendefinisikan belajar tentang tubuh cerdas sebagai aliran pengalaman yang terus menerus yang tidak pernah berhenti。
Arah penelitian ini berkumpul. TTT-Discover memiliki pelatihan tes terpadu dan penjelajahan yang didorong RL-. HOPE embed siklus belajar lambat dalam satu struktur. SDFT mengubah distilasi menjadi operasi dasar untuk perbaikan diri. Batas antara kolom kabur. Generasi berikutnya dari sistem belajar terus menerus cenderung untuk menggabungkan strategi: regularisasi untuk menstabilkan, meta- belajar untuk mempercepat, dan peningkatan diri untuk keuntungan senyawa. Sejumlah pemula bertaruh pada tingkat yang berbeda dari gudang teknologi ini。
Belajar terus-menerus kewirausahaan
Akhir non- parameter dari spektrum yang paling terkenal. Perusahaan shell (Letta, mem0 dan Bawah sadar) membangun lapisan dan scaffolds untuk mengelola isi jendela konteks. Penyimpanan eksternal dan infrastruktur RAG (misalnya Pinecone, xmemory) menyediakan tulang punggung pencarian. Data ada dan tantangannya adalah untuk menempatkan irisan yang tepat di depan model pada waktu yang tepat. Ketika jendela konteks mengembang, begitu pula ruang desain perusahaan-perusahaan ini, terutama di bagian luar kerak, gelombang start- up baru muncul untuk mengelola semakin kompleks strategi konteks。
Parameter lebih awal dan lebih banyak dolar. Perusahaan di sini mencoba beberapa versi dari "deposisi compression" untuk menginternalisasi informasi baru dalam berat badan. Jalan dapat dibagi menjadi beberapa taruhan yang berbeda, tentang apa model harus belajar setelah mereka diterbitkan。
Kompresi sebagian: Anda dapat belajar tanpa pelatihan ulang。Beberapa tim membangun modul pengetahuan tertanam (dikompresi cache KV, lapisan adaptor, penyimpanan memori eksternal) untuk profesional model umum tanpa memindahkan beban inti. Argumen umum adalah bahwa Anda dapat memperoleh kompresi berarti (bukan hanya pengambilan), ketika menjaga keseimbangan dari penandaan dalam batas yang dapat diatur, karena pembelajaran dipisahkan, tidak tersebar di parameter. Model 8B disertai dengan modul yang cocok untuk mencocokkan kinerja model yang lebih besar dalam misi target. Keuntungan adalah portabilitas: modul dapat ditancapkan dengan struktur Transformer yang telah ada, yang dapat diperdagangkan secara independen atau diperbarui, dan biaya percobaan jauh lebih rendah daripada biaya pelatihan intensif。
RL DAN SIKLUS UMPAN BALIK: BELAJAR DARI SINYAL。Lainnya bertaruh bahwa sinyal yang paling berlimpah dari pembelajaran post- penyebaran sudah ada dalam siklus penyebaran itu sendiri - sinyal untuk koreksi pengguna, misi sukses atau gagal, dari hasil dunia nyata. Ide intinya adalah model harus memperlakukan setiap interaksi sebagai sinyal pelatihan potensial, bukan hanya permintaan penalaran. Hal ini sangat mirip dengan cara manusia berkembang di tempat kerja: bekerja, mendapat umpan balik, menginternalisasi apa yang bekerja. Tantangan rekayasa adalah untuk menerjemahkan tipis, bising dan kadang-kadang reaksi konfrontasional menjadi pembaruan stabil beban, tanpa bencana terlupakan. Tapi model yang benar-benar belajar dari penyebaran dapat menghasilkan nilai senyawa dengan cara yang sistem di bawah tidak dapat melakukannya。
Belajar dari sinyal yang tepat。Sebuah taruhan yang terkait tapi diferensiasi adalah bahwa botol tidak belajar algoritma, tetapi melatih data dan sistem perifer. Tim-tim ini fokus pada penyaringan, menghasilkan atau mensintesis data yang benar untuk mendorong pemutakhiran terus menerus: Hal ini diperkirakan bahwa model dengan kualitas tinggi dan terstruktur baik sinyal pembelajaran dapat diperbaiki dengan lebih baik dengan gradien yang jauh lebih kecil. Ini adalah koneksi alami dengan perusahaan loop feedback, tapi pertanyaan hulu menekankan: apakah model dapat belajar adalah satu hal, apa yang harus mereka pelajari dan sampai sejauh mana。
Arsitektur baru: belajar kompetensi dari bawah。Taruhan yang paling radikal adalah arsitektur Transformer itu sendiri adalah bottleneck dan pembelajaran yang terus-menerus membutuhkan istilah komputasi yang berbeda: sebuah struktur dengan kontinum dinamika waktu dan dalam mekanisme memori. Argumen di sini adalah struktur: jika Anda ingin sistem pembelajaran yang terus menerus, Anda harus memasukkan mekanisme pembelajaran ke dalam infrastruktur bawah。

Gambar: Awal Bisnis untuk pembelajaran berkelanjutan
semua laboratorium utama juga aktif dalam kategori ini. beberapa menjelajahi pengelolaan konteks dan pemikiran yang lebih baik, beberapa bereksperimen dengan modul memori eksternal atau tidur-waktu tabung komputasi, dan beberapa perusahaan yang tidak terlihat mengejar struktur baru. daerah ini cukup awal untuk melihat bahwa tidak ada metode yang telah dimenangkan dan, mengingat luasnya kasus, seharusnya tidak ada pemenang tunggal。
Mengapa pembaharuan sederhana gagal
Memutakhirkan parameter model di lingkungan produksi bisa memicu serangkaian model gagal yang saat ini belum terselesaikan dalam skala besar。

Gambar: Mode pemutakhiran berat sederhana gagal
masalah teknis didokumentasikan dengan baik. terlupakan bencana berarti bahwa model yang cukup sensitif untuk belajar dari data baru menghancurkan manifestasi stabilitas yang ada dan plastisitas. dekomposisi waktu berarti bahwa set bobot yang sama dikompresi oleh aturan konstan dan keadaan variabel, dan bahwa satu update akan merusak yang lain. integrasi logis gagal karena pemutakhiran fakta tidak menyebar ke inferensi yang perubahan terbatas pada urutan token, bukan konsep semantik. pembelajaran masih tidak mungkin: tidak ada operasi de minimis, jadi tidak ada program pemindahan bedah yang tepat untuk pengetahuan palsu atau beracun。
Kategori kedua masalah menerima kurang perhatian. Pemisahan pelatihan dan penyebaran saat ini tidak hanya sebuah fasilitas teknik; ini adalah perbatasan keamanan, audit dan pemerintahan. Buka batas ini, dan banyak hal yang salah pada saat yang sama. Perataan keamanan mungkin tidak terduga terdegradasi: bahkan sebuah fine- tuning sempit dari data jinak dapat menyebabkan gangguan meluas。
Pemutakhiran terus menerus telah menciptakan wajah ofensif keracunan data - lambat, tahan lama infus tips, tetapi hidup pada berat badan. Auditbility runtuh karena model yang terus diperbarui adalah target mobile yang tidak dapat digunakan untuk kendali versi, pengujian regresi atau satu-off otentikasi. Ketika pengguna berinteraksi ke dalam parameter, resiko privasi meningkat dan informasi sensitif adalah baking ke dalam bentuk, membuat lebih sulit untuk menyaring daripada mengambil informasi dalam konteks。
Ini adalah masalah keterbukaan, bukan kemustahilan mendasar. Addressing mereka, seperti menangani tantangan arsitektur inti, adalah bagian dari yang sedang berlangsung belajar agenda penelitian。
Dari fragmen memori ke memori nyata
Tragedi Leonard dalam Memory Fragments bukan berarti dia tidak bisa beroperasi - dia banyak akal dan bahkan brilian dalam skenario apapun. Tragedinya adalah bahwa ia tidak akan pernah pulih. Setiap pengalaman telah tinggal di luar - catatan yang diambil, tato, tulisan tangan orang lain. Dia bisa mencari, tapi dia tidak bisa menekan pengetahuan baru。
Ketika Leonard berjalan melalui labirin ini, garis antara kebenaran dan keyakinan mulai kabur. Penyakitnya bukan hanya menyangkal ingatannyaItu memaksanya untuk membangun kembali maknanyaBiarkan dia menjadi detektif dan teller tidak dapat diandalkan dari ceritanya sendiri。
AI HARI INI BERJALAN DI BAWAH KENDALA YANG SAMA. KAMI MEMBANGUN SISTEM PENGAMBILAN YANG SANGAT KUAT: JENDELA KONTEKS YANG LEBIH PANJANG, CASING LEBIH CERDAS, TERKOORDINASI BANYAK KELOMPOK INTELIJEN, DAN MEREKA BEKERJA. NAMUN, PENCARIAN TIDAK JUMLAH UNTUK BELAJAR. SEBUAH SISTEM YANG DAPAT MENGUNGKAP FAKTA TIDAK DIPAKSA UNTUK MENCARI STRUKTUR. ITU TIDAK DIPAKSA UNTUK DIGENERALISASI. BIARKAN BEGITU BANYAK PELATIHAN MENJADI BEGITU SERIUS DIKOMPRESI - MENGUBAH DATA MENTAH MENJADI MEKANISME PERWAKILAN TRANSFERSATIF - TEPAT APA YANG KITA MEMATIKAN PADA SAAT PENYEBARAN。
Jalur ke depan sepertinya tidak akan menjadi terobosan tunggal, melainkan sistem berlapis. Pembelajaran konteks akan terus menjadi garis pertahanan pertama: itu asli, disahkan dan terus meningkat. Mekanisme modular dapat mengatasi dasar tengah personalisasi dan spesialisasi di lapangan。
Tapi bagi mereka yang benar-benar sulit - pengetahuan tersembunyi yang menemukan, beradaptasi, tidak dapat diungkapkan dengan kata-kata - kita mungkin perlu membiarkan model terus menekan pengalaman ke parameter setelah pelatihan. Ini berarti kemajuan dalam arsitektur tipis, meta- belajar tujuan dan siklus perbaikan diri. Ini juga memerlukan redefinisi dari apa yang dimaksud model: bukan satu set beban tetap, tetapi sistem evolusi yang mencakup memori, algoritma terbaru, dan kemampuan abstrak dari pengalaman sendiri。
Lemari pengajuan tumbuh. Tapi kabinet yang lebih besar adalah lemari arsip. Terobosan adalah hal yang membuat model menjadi kuat ketika mereka dikerahkan dan dilatih: kompresi, abstraksi, pembelajaran. Kita berdiri di titik balik dari model kehilangan ingatan menjadi model dengan sedikit pengalaman. Jika tidak, kita akan terjebak dalam Hilang Ingatan kita。
Tautan Asli
