
保存可能から解決可能:BitrootがAIデータ値レイヤーを再作成する方法
一方、Bitroot は、EVM を Pipeline BFT と並列化し、その一方で、データ、モデル、アルゴリズム、エージェントのアプリケーションを分散トレーニング、推論ネットワーク、信頼性の執行、AI アセット管理を通じてクリアなネットワークに接続します。 このネットワークでは、ストレージは独立したモジュールではなく、モデルが再エマージ可能かどうか、計算が閉じられ、コントリビューターが利益を持続できるかどうかを正確に判断するインフラではありません。

ソース:ビットルート
ストレージはコストセンターではなく、Bitroot AI Stackの付加価値流通システムです
多くのチームは、ストレージの層が年の最初の半分にもっと慎重に選ばれたべきであることに気付いた。 データが失われず、サービスが止まりませんでしたが、問題は別の方法で現れました。アーカイブ内のトレーニングデータがゆっくりと取得され、ホットスポットのベクトル検索のテールはミリ秒から秒まで揺れていましたが、再プレイしなければならないときにモデルが使用していたトレーニングデータのバージョンは誰に伝えませんでした。 この時点では、拡張がなくなり、さらに3つの難しくなる質問があります。データが常に利用可能であることを証明できる人は、バージョンに責任を持ち、長期費用を支払うことになります。
中央クラウドからチェーンの下のネットワークにファイルを移動させるストレージを理解すると、NFTメタデータ時代に蓄積されます。 操作がAIのトレーニング言語、モデル重量、ベクトルインデックスに拡張されると、このアプローチはすぐに失敗します。
ほとんどのチームは、これまで最高の物流コストであるためにストレージと見なされています。これは、最も評価され、最も簡単に選択できる場所です。AIチェーンでは、実際にデータを持っているか、誰が進むのかを決定する価値分布層です。 この記事は1つの質問だけに答えます: パブリックチェーンとのAI統合のコンテキストでは、検証可能な管理可能で持続可能な分散ストレージプログラムの構築方法。 3つのドミナントのパラダイムの能力境界線は下落し、AIデータの特定の難しさが説明され、最終的に5層のアーキテクチャとエントリの相続的なしきい値。 審査は、主に公式のプロトコル文書に基づいており、可能な範囲で検証可能な情報に基づいています。
Bitrootの場合、ストレージのより正確な位置は、AIスタックの価値分布ベースです。 一方、Bitroot は、EVM を Pipeline BFT と並列化し、その一方で、データ、モデル、アルゴリズム、エージェントのアプリケーションを分散トレーニング、推論ネットワーク、信頼性の執行、AI アセット管理を通じてクリアなネットワークに接続します。 このネットワークでは、ストレージは独立したモジュールではなく、モデルが再エマージ可能かどうか、計算が閉じられ、コントリビューターが利益を持続できるかどうかを正確に判断するインフラではありません。

チェーンアップ・センタリング AIでは動作しません
過去数年間、ストレージの問題は、しばしば1つまたはもう1つに減少しました。完全なチェーンまたは一元化。 どちらの道路もAIシーンで不便です。
完全なチェーン圧力は特定です。 トレーニングデータ、モデルウェイト、ログの推論、ベクターインデックスは、一般的に高音量と高周波アップデートであり、スライスしてチェーンしても、嘔吐の天井とコストカーブの両方にクラッシュします。 完全な集中化は高速で実行されますが、検証、トレーサビリティ、データ sovereignty およびクロスサブジェクトのコラボレーションの信頼性ベースは、脆弱であり、複数のアカウントが分割され、権利が関与すると維持できません。
コストアイテムから生産ファクターまで、AIがストレージを変更しました。 データバージョンの管理は、反復モデルのイニシアチブを取るかどうかを決定します。データが利用可能であることが実証され、コンピューティングの優先順位に直接影響を与える可能性があるかどうか、およびデータを自動化する能力は、チームが長期的な環境インセンティブを作成することができるかどうかの問題です。 リザーブはもはや物流システムではなく、価値配分システムではありません。
そのため、資格のあるストレージ構造は、一度に4つの質問に答えなければなりません。 データが現実的で望ましいかどうかにかかわらず、データがモデルのバージョンにトレーサブルであるかどうか、コンピテンシーと利点が管理可能であり、システムが時間の経過とともにコストとパフォーマンスのバランスをとるかどうか。

ビットルートのエントリーポイント:AIデータを「保存可能」から「読み込み可能」に移動させる
Bitrootが埋め込まれる必要があるところです。 AIシーンの高性能Parrallel EVMパブリックリンクとして、Bitrootのストレージ物語は「データが配置されている場所」で止まらないはずですが、むしろ「データが実証されているのか、彼らがどのように呼び出されるのか」と答えます。 トレーニング資料、モデルウェイト、ベクターインデックス、および推論ログは、より大きなオブジェクトに適した分散ストレージレイヤーに残すことができますが、Hashiのコミットメント、バージョンの関係、権限戦略、コールレコード、および収益イベントは、Bitrootの統一されたチェーン証拠を必要とします。
この観点から、Bitrootのハイ・インプットとロー・デリブレーション・イベントは、DeFi取引だけでなく、AI Stackでのニュアンスと高頻度のガバナンス・イベントも提供しています。 データセットの更新は、モデルバージョンが登録され、AIエージェントの呼び出しが解決され、検索結果が仲裁され、ストレージノードの可用性が継続的にチャレンジされ、報酬が受けられます。 下のチェーンがこれらのイベントを乗り越えることができれば、AIデータアセットは一元化されたデータベースにロックされず、チェーンの下には比類しないブラックボックスに変えられます。

3つのドミナントパラダイム、どれもシーンを単独で貫通することができます
分散ストレージの競争は、最も先進的ではありませんが、データ構造において最も適切です。
コンテンツ検索ネットワークは、それがデータであるか否かを解決し、誰もそれをオンラインで保証しません。 IPFS の公式文書によると、CID はコンテンツの HASHI アイデンティティに基づいており、場所に依存しません。同じコンテンツは同じコード設定で同じ CID を生成し、CID はコンテンツがバイトを変更する限り変更されます。 この機能は、完全性検証、重み付け、クロスシステム参照のために自然にでき、データ検証の底容量です。 しかし、コンテンツの場所は経済的に持続可能なものではなく、CIDはアイデンティティの質問に答え、それがライン上に残っていることを保証しない。 多くのチームがステップを踏む最初のピットは、技術的に、CID、そして操作上、ユーザビリティへのコミットメントはありません。
市場のネットワークの貯蔵は時間次元の可用性を買う経済的なメカニズムの使用です。 Filecoinのドキュメントによると、ネットワークは、保存約束のメカニズムを生成し、プルーフ・オブ・レプリケーションとプルーフ・オブ・スペースタイムによる継続的な認証を行います。 PoRepは、この一意のコピーが初期の封筒に実際にあったことを証明し、PoStは繰り返しフォローアップサイクルにあったことを証明しました。 WindowsPostは、通常、証明書サイクルを24時間体制で整理し、複数の30分の証拠ウィンドウに切断し、リポジトリが有効な証拠をウィンドウに提出しない場合は、格納容量の担保の要塞と削減をトリガーします。 このシステムでは、ユーザビリティは、契約後の約束ではなく、継続的なテストです。 この契約、監査可能なモデルは、中長期のアーカイブ、バックアップ、データ市場に適していますが、それは高い周波数オンラインクエリを直接圧力とテール遅延の経験の下に置く自然な低遅延のオンラインサービスではなく、実証済みの長期倉庫のようなものです。
恒久的なストレージネットワークは、歴史のワンオフ支払いで、別のルートを取ります。 Arweave Agreement と Yellow Book 情報によると、アップロードコストの部分は、長期にわたるストレージのインセンティブをカバーし、その後の継続慣行に依存するのではなく、課金モデルで長期のサステイナビリティを置きます。 歴史的アーカイブ、重要な文書、著作権素材、および非取り外し可能なレコードに適しています。 ショートボードもクリアです: パーマンテンシーは、自動的に高遅延と低遅延の量ではなく、実際には、キャッシュ、ゲートウェイ、またはほぼラインのインデックスレイヤーを折り畳む必要があり、ユーザーの側にリアルタイムのエクスペリエンスを満足させます。
これらの3つの基本パラダイムに加えて、エンジニアリングの2つの一般的な組み合わせは、計量価値があります。 一つは、データの可用性レイヤーとオブジェクトストレージと、より標準化されたデータの普及とクロス合成と複雑なインタフェースガバナンスのコストでの可用性の証明の混合物です。 一方、クラウドプラスの合成、低遅延、より良い災害耐性ですが、コストガバナンスと協調的な管理が到達するのは困難です。
いずれにしても、全てのシーンを食べるための合意は機能しません。 効果的な方法は、データタイプによってグループ化される: 持続性、検索時間とコンプライアンスを削除し、機能レイヤーを別々に一致させ、チェーンアンカーおよびガバナンスレイヤーによって均一な方法で組織されることです。
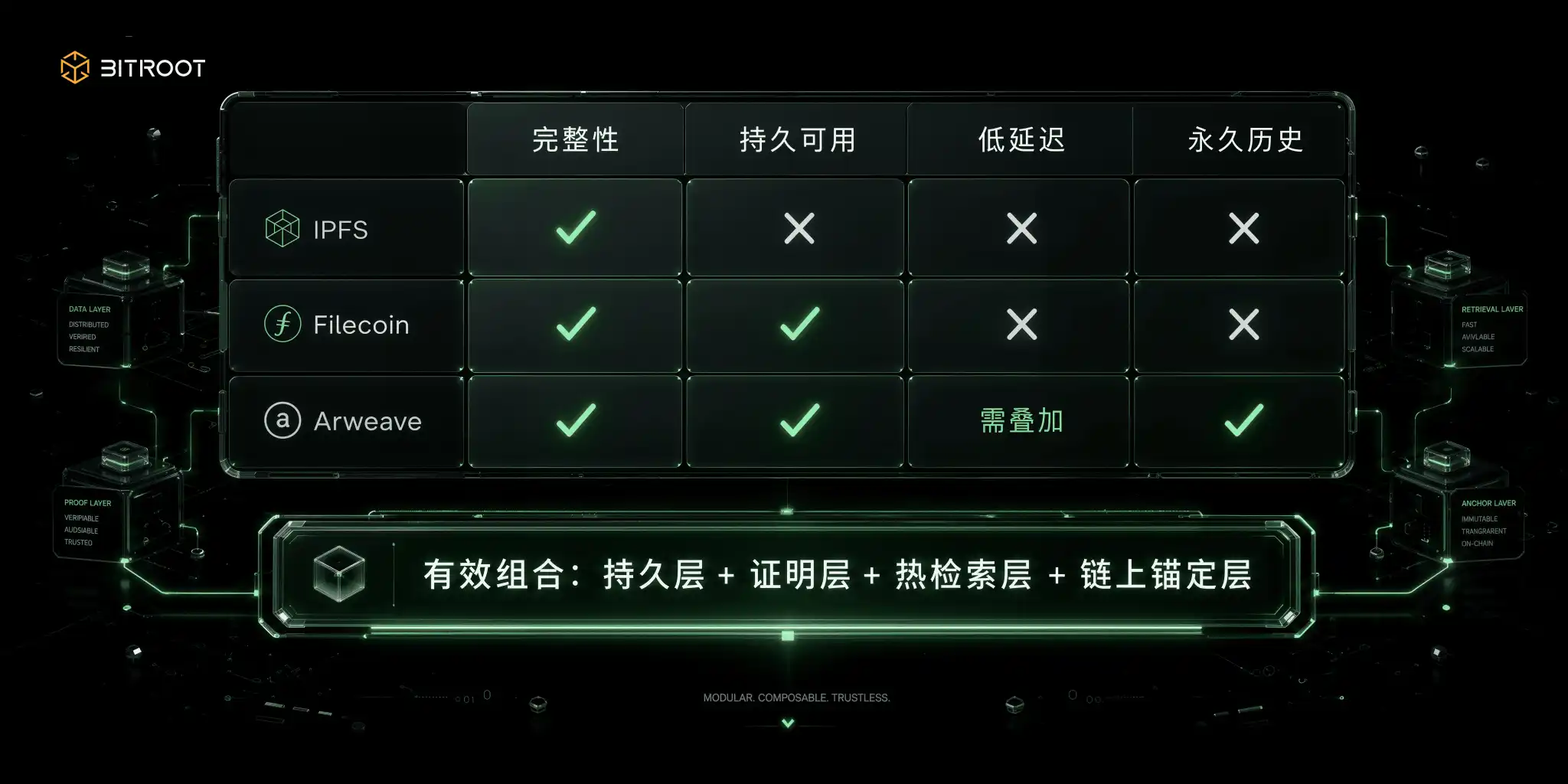
Bitroot ' スペースの選択肢は、この組み合わせロジックに基づいている必要があります: IPFS、Filecoin、Arweave、またはオブジェクトと互いに交換するのではなく、さまざまな責任の層に配置します。 コンテンツアドレスは、データアイデンティティと完全性のために使用され、ストレージ証明書は、長期の可用性のために使用され、永続レイヤーは、主要な履歴と文書に使用されます、熱的検索層はAIアプリケーションの経験に使用され、上部のBitrootチェーンは、バージョンの固定、権限ポリシー、呼び出しの決済および紛争解決を均一に運ぶために使用されます。 言い換えれば、Bitrootは、すべてのデータの物理的なリポジトリである必要はありませんが、AIデータフローの信頼できるアカウントではありません。
AIストレージの難しさ、ファイルではなく、生産リンクの実行
AI設定では、ストレージオブジェクトは、トレーニングデータ、モデルウェイト、ベクトルインデックス、推論ログの4つのカテゴリに分けられます。 ライフ サイクル、対象の 4 つのカテゴリのアクセスと値密度のモードは完全に異なります。, 管理する戦略のセットと, 短期貯蓄, 制御不能なガバナンスの長期期間。
トレーニングデータの問題は、バージョンの容量とドリフトにはありません。 多くのチームは、TB グレードのストレージコストでデータの問題を訓練し、より問題が漂流しているもの: クリーニングルール、サンプル選択のしきい値または校正の変更、モデル動作の変更、およびバインドデータやモデルのバージョンなしで、オフライン評価が検証するのは困難です。 MLFlow の s モデルおよびデータ追跡の練習に従って、訓練操作およびデータ版の結合は実験のreplicationのための前提条件です。 この原則はチェーンで有効です。元のデータは完全にチェーンする必要はありませんが、約束、鍵の要約とソースの指紋を解放する必要があります。 少なくとも3つのマーカーは、プロジェクト、データバージョン、トレーニング操作、モデルバージョン、および1つなしで、ライン上の問題は、証拠から推測します。
モデルの重みの問題は、彼らがダウンロードできるかどうかではなく、境界を呼び出します。 モデルは、通常、グレースケール、プライマリ使用、ロールバックおよび解読のいくつかの状態を通過し、登録と認可の標準化されたシステムなしで生産に入り、オンラインコールは、未使用可能なブラックボックスです。 成熟したモデルの登録センターは、血行、バージョンエイリアス、署名制約、監査ラベルを記録します。 チェーンシステムでは、モデルバージョンは単なる文書ではなく、橋ではなく、権限戦略、進捗状況の分布、責任の境界線とともに結ばれるべきである。
ベクトルのインデックス化の難しさは、熱と冷層の一貫性を1か所に集中します。 ベクトル検索、低遅延、低コストの対比があります。 サーモスフィアは、オンラインの応答とコールドレイヤーが長期のコストを含有するオブジェクトストレージに依存していることを確認するために、メモリまたは高性能のインデックスサービスに依存しています。 統一されたメタデータと同期戦略がなければ、2つのレイヤーはすぐに分割され、同じクエリの問題は、異なるノードでセマンティック結果を返します。 そのため、ベクターシステムは2つのことをサポートする必要があり、インデックスの構成プロセスを追跡でき、サーモスコープのインデックスバージョンは、検索を検証できる横のテキストが正確にあるコールドマスターデータと一致させることができます。
プライバシー、監査、コンプライアンスを確立する推論のログを確立することは困難です。 セキュリティ監査資料とプライバシーリスクのソースの両方です。完全かつ明示的な保持は、コンプライアンスリスク、完全に不確実性、事故の巻き戻し能力の喪失を示しています。 実現可能なアプローチは、超固定、分散型コンテンツストレージの3つの層です。 橋 ' s は、チェーンとアクセスを上回るコミットメントは、非リムーバブルおよび再生可能な階層を達成するために、監査許可の対象となります。
BitrootのAI Stackでは、これらの4つのカテゴリは、固定およびソースの登録のための訓練データ、アセットの登録と呼び出しに対する承認モデルの重み付け、熱と冷間構造と一貫性のベクトルインデックス化、嫌なストレージと監査の約束のためのログを推論することができます。 同じ方法でチェーンする必要はありませんが、Bitrootで統一されたアセットID、バージョンスペクトラム、コールイベントを作成する必要があります。 これにより、データアセット、モデルアセット、エージェントアプリケーション間で再利用可能な商用クローズされた円を形成することができます。

しかし、それは一番下線です。 一番下線です
ユーザビリティの証明のないストレージのコミットメントは、本質的に生産環境のコミットメントと等価です。 配布ストレージは、AI検索シーンが配置されると、整合性、ユーザビリティ、実行、監査性、および、AI検索シーンが配置されると、一緒に検索するのがより困難である3つの方法で生産を伴います。
完全性は、コンテンツの場所とMerkleの約束によって証明されます。 コンテンツの場所は、データの指紋が安定して、マークルは部分的に検証できるように約束します。 プロジェクトのポイントは、オブジェクトのサブセットをフルに読み込まなくても証明できるということです。 大規模なモデルの重み、大きい言語およびマルチメディアのデータのために、これは直接検証の費用を決定します。
問題のメカニズムおよびサンプル検証によって可用性が証明されます。 Filecoinの練習は、ユーザビリティがSLAを経口していないことを示しましたが、抽象化された一般的な構造体が受動点チェック、アクティブ検査、および障害ペナルティのセットである定期的な課題のチェーン上で実証されています。ノードは、所定のウィンドウの課題に反応しなければなりません。そうしないと、ペナルティがトリガーされるか、重量が減少します。 データの可用性の観点から、同じ考え方が進んでいます。 Celesti の s のデータ可用性のサンプル設計によると、データは kxk から 2kx2k の行列に展開され、複数の車輪のランダムサンプリングと確率で蓄積する光ノードは、データ全体をダウンロードすることなく、ユーザビリティの高い確率の信頼性を構築します。 これは、AIシナリオが移行するためのインスピレーションです。ダウンロードすることで、すべての可用性が十分に検証されず、統計的な確認は、大規模なシステムでより現実的です。
チェーンアンカーとインシデントマークの対象となります。 ストレージシステムに関する最も難しいことは行動です。誰が戦略を変え、誰がマイグレーションをトリガーするのか、機密モデルを使用するのかをアップロードします。 これらの行為がイベントの単一のストリームに関与しない場合は、紛争がある場所に戻ります。 チェーンのすべての詳細を配置するよりもむしろ、ガバナンスは、紛争時に証拠の最小化、決定的、検証可能なコレクションを保持しています。
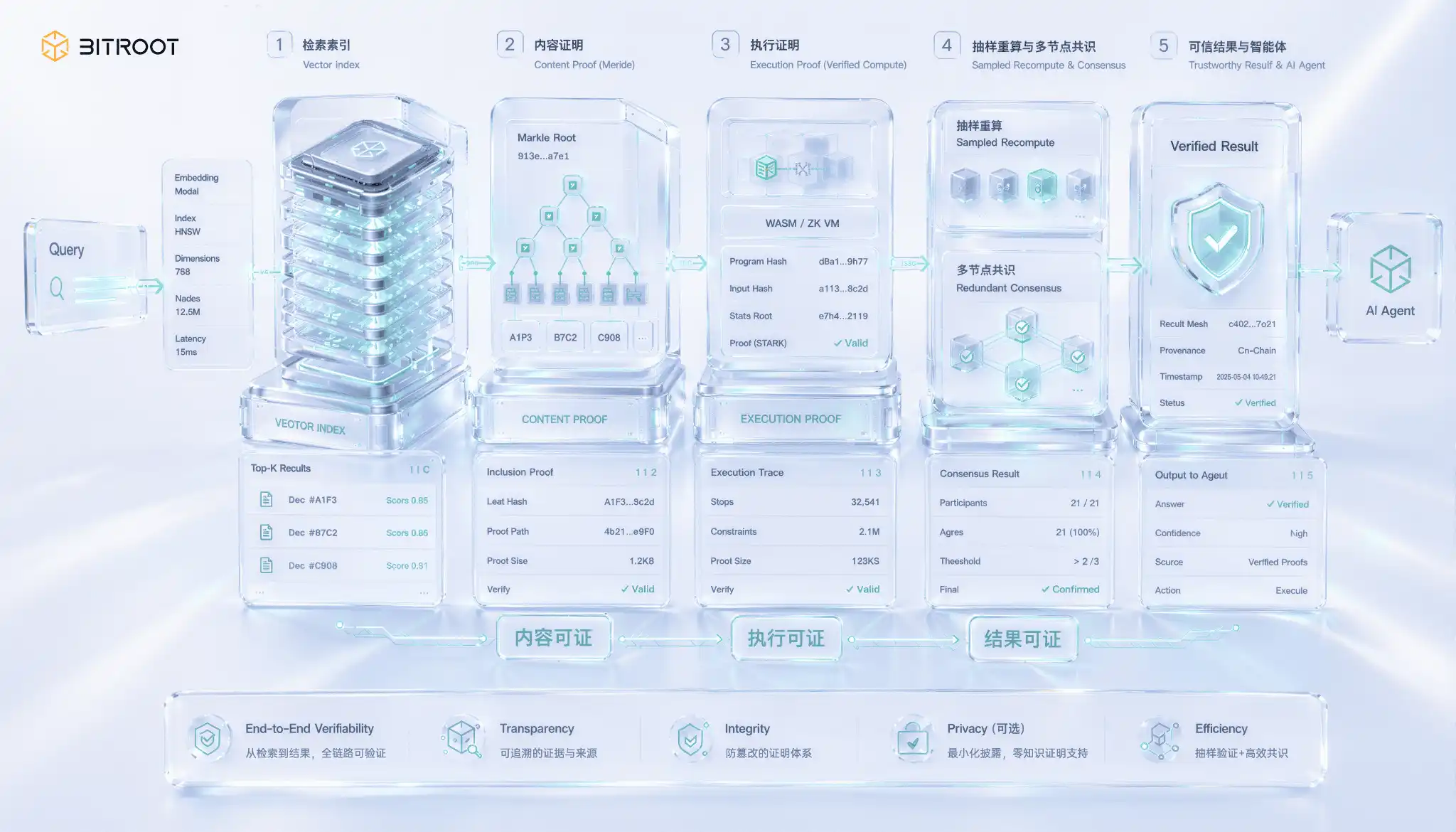
検索証明書はAIシーンのユニークで最も困難な1つであり、問題は簡単に無視されたギャップで発生します。結果を返すことは正しい結果を返すのと同じではありません。 ベクトル検索ノードは、最新のインデックスを取ったり、最も近い隣接者をスキッピングしたり、一見リーズナブルなトップクの1つに戻り、単独で戻り値を見ることはできません。 自発的に出力された出力は、自発的に改善されず、エラーは報告されませんが、品質とモデルのパフォーマンスを静かに取り戻すだけです。 結果が決済、承認、またはチェーンの意思決定に使用する場合、このギャップは品質から信頼へとエスカレートします。
検索可能でないと、実際には変更の3層保証です。 最初のレベルは、Return のベクトルが、インデックスの約束されたバージョンに属しているという証拠です。インデックスのデータ構造を確立することで、Merkle をルートにチェーンし、結果をカプセル化証明書で返すことで、ノードがデータで製造または改ざんされていないことを確認します。 第2の階層は、クエリが約束されたバージョンではなく、個別に修正されたインデックスで実行していた証明書の実行でした。これにより、クエリプロセスが検証可能な計算に含まれている必要があります。 3番目のレベルは、結果とともに、返されたトップクは、最も近い隣人の欠如ではなく、与えられた測定で最新の状態であることを証明するのが最も困難です。これは、最近の近隣検索の推進の本質的に証明されています。
厳密な結果は、最も近い隣接する高次元の観点での生産の規模はまだ問題の最前線にあり、ゼロの証拠のようなパスワードが進歩している間、高次元ベクトル計算のコストは、大規模なオンライン使用のために実証されているから遠くです。 実用的なエンジニアリングソリューションは、ステップバイステップではなく、ボトムアップです。まず、インデックスバージョンをコミットし、トレーサビリティを確保するためにそれらをチェーンするためのパラメーターを構築します。その後、クエリのサンプルを再計算し、プロラタベースで検索を信頼できるコピーに再実行し、記事バイ粒子の証拠ではなく、統計的な自信と結果を比較します。複数の独立したノードを過負荷にできるようにし、結果のコンセンサスに到達し、単一のポイントを不正行為のコストを上げるために、または再計算された場合にのみ再構成します。 ラインは、ユーザビリティの証明書でサンプルを優先するという考え方で手を動かしています。大規模なシステムでは、統計確認と紛争のエスカレーションは、記事によって厳密に実証されるよりも、より容易に利用できる傾向があります。
Bitrootの場合、検証可能な検索は独立したストレージ機能ではありませんが、信頼できるAIAgent実行の一部です。 外部の知識ベースに依存している場合, 意思決定のためのモデル重量やベクトルインデックス, システムは少なくとも3つのことを答えなければなりません: データのバージョンを読み、モデルのバージョンを呼び出し、登録されたインデックスバージョンから結果を返します。 Bitrootは、この証拠を検証可能なイベントのチェーンに圧縮することができます。Agentは「スマートに見える」から「リトアクティブ、論争、ソルベンシー」に移動することができます。

選択の問題:選択ではなく、グループ化
問題が間違っていたため、多くのプログラムのレビューが失敗しました。 正しい処方は、契約を使用するかどうかではありませんが、当社のデータミックスとは、ターゲットインジケータが何であるか、制約が何であるかです。 4つの動きが続くのがおすすめです。
データ資産は最初にカウントされます。 ステータスデータ、オブジェクトデータ、検索データ、監査データを少なくとも区別し、在庫テンプレートを固定フィールドにし、最低8つのフィールドを構成します。データタイプ、増加量、ピーク結合分布、読み書き比率、保持サイクル、コンプライアンスレベル、ターゲット時間延長、コストキャップ。 フィールドが統一されると、クロスチーム選択通信がはるかに高速になります。
サービスレベルのターゲットの定義 P95/P99 時間の延長、回復時間 RRO、回復ポイント RPO、可用性ターゲット、単一 TB の費用の帽子は死にるために書かれています、そうでなければすべての後続の議論のための定規がありません。
次に、機能マップを作成します。 永続的ストレージのカテゴリ、ユーザビリティの循環的証拠、検索およびガバナンスへのアクセスの低遅延は、単一のレイヤーではなく、異なる技術層に示されます。
移行閾値の確定 どのようなデータは、トランジションの集中化、指標がマイグレーションをトリガーし、集中的な置換が完了したときにどのようなデータを可能にします。 1つの実用的なアプローチは、ダブルのしきい値を設定することです。単一のTBは、2つの連続した統計サイクルのオーバーバゲット、またはP95、2週連続のオーバーターゲット、構造的な移行レビューを自動的にトリガーすることです。 しきい値のないガバナンスがなく、移行期間が永続的になります。
着陸プログラム:リビング、望ましい、管理可能な閉鎖と5層構造
アーキテクチャの値は、大きさの順番ではなく、検証可能なループの形ではありません。 以前のフレームワークに基づいて、プログラムはレイヤー、オブジェクトストレージレイヤー、インデックス検索レイヤー、サービス可能性証明書レイヤー、キーアクセスレイヤーを固定する5つのレイヤーに凝縮されます。 目的は、デフォルト容量、高いパフォーマンスを構成、およびガバナンスに強制可能なプロセスに検証できるようにすることです。
Bitrootでは、これらの5つのレイヤーはAI Stackストレージ・ガバナンス・モジュールとしてさらに理解することができます。Parallel EVMは、高周波固定機能とクリア機能を提供し、Pipeline BFTは、低遅延の確実性、分散ストレージネットワークを大きなオブジェクトや履歴データ、インデックス検索レイヤーサービスAIエージェントとアプリケーションコール、可用性証明書レイヤーは、ノードサービスの品質をクレジットおよび報酬に変換し、キーアクセスレイヤーは、ユーザー sovereignty、プライバシー保護、モデルの商用化をリンクします。
チェーンアンカーは、データコミットメント、バージョン指紋、許可戦略の概要、決済イベントの最小限の状態に保持されます。 大きいオブジェクトは、その存在と正しいバージョンを証明するためにチェーンされていない。 チェーンの確率を維持し、大きな文書でストールをドラッグすることはできません。
Bitrootのフレームワークでは、チェーンアンカーは単なる「橋の記録」ではありませんが、AIアセットの登録、権限ガバナンス、進捗および紛争決定の配分に関する一般的なエントリポイントです。 データセット、モデルウェイト、ベクトルインデックス、推論ログはすべて、チェーンの下に最も適切な方法で保存することができますが、バージョンのコミットメント、権限のあるステータス、コールレコード、および進行状況は、ビットルートチェーンを入力する必要があります。 そのため、チェーンストレージは負荷を運ぶ責任があり、ビットルートは信頼を運ぶ責任があります。
オブジェクト記憶層は、デコーダリングとコピーの混合戦略を使用して、実際のデータを運びます。高値、低周波アクセスされたオブジェクトは、エラーと中値、高頻度視覚化されたオブジェクトは検索効率の対象となります。 この戦略は静的な構成ではなく、熱やビジネスクラスのダイナミクスを訪問するように調整されます。
インデックス検索レイヤーは、メタデータとベクトルのインデックスを統一したカタログに組み込まれ、サーモフィアはオンライン検索に接続され、コールドレイヤーはアーカイブされ再構築されます。 ソースバージョンとビルドパラメータを登録するには、インデックスのドリフトはトレースできません。
可用性レイヤーの証明書内のノード動作の定量化。 課題に対応する成功率、応答時間枠とリハビリテーションの成功率は、信頼性、評価、インセンティブ配分の面で評価され、報酬容量と可用性を回避します。
主要なアクセス管理および承諾。 高感度データは、キーと時間ベースの認証で分類され、ログを監査リリースで保存し、モデルの呼び出しは再発する可能性があります。 許可操作自体は、設定のドリフトを防ぐためのマークを残します。
5層は、単方向の水線ではなく、実装レベルで閉鎖されます。 データアクセス後、スライスはオブジェクトレイヤーにエンコードされ、チェーンを書いてアンカーした後にインデックスを作成します。オンラインクエリは、温度圏が切り離され、コールドレイヤーに戻り、結果は完全性検証と認証検証をトリガーし、キー動作が決済と監査に入ります。 このチェーンの実際の値は、4つの質問が任意のノードまたは瞬間に応答できることです。 データがどこから来たのか、現在のバージョンが何であるか、誰がアクセスできるか、システムがその可用性を証明できるか。
これは、BitrootがAIストレージガバナンスに適している主な理由です。 AIエージェントの呼び出し、モデルバージョンの切り替え、データ認可の変更、検索結果に関する紛争は、低頻度のバックステージ操作ではなく、アプリケーションの成長を続けるチェーンイベントです。 一番下のチェーンが遅延の十分な低い確認と十分な高いスループットを提供できなかった場合、ストレージ・ガバナンスは最終的にチェーンの下部に戻り、手動の調整を強制されます。 Bitroot と Pipeline BFT の Parallel EVM は、より高い TPS だけでなく、これらの高周波ガバナンスイベントをリアルタイムで固定、解決、そして追求できるようにします。

誰がそれを支払うつもりです:私たちは、容量ではなく、リターンを決定するために使用してみましょう
長期的に実行するストレージのために、インセンティブはすぐに利用できる必要があります。 容量の量だけが報われます。これは、ハードドライブと光サービスを杭打ちするために偽装されたインセンティブと同等です。 このポイントは、Filecoinメカニズムによって変更されています: それは、品質調整された電力の概念を導入し、実際のストレージ注文の受け入れを可能にし、特に有効で検証された注文、すなわち、ストレージスペースの最小測定ユニット、電力の測定でより高い重量を得るために、それによって、単に封筒の空の容量ではなく、実際のサービスを提供するために能力に対するインセンティブを傾けます。 このアイデアは、自己構築のインセンティブに値します。
少なくとも4次元を同時にカウントし、各重みの論理を明白する強制的なインセンティブ機能にそれを入れて下さい。 容量は、ベースシェアを決定し、約束したどのくらいのスペースに応答します。 オンラインレートと応答時間は、サービスの品質要因を決定し、必要なときにこのスペースが本当に望ましいかどうかを答えます。これは、より高い重量を持っている必要があります。そうしないと、ユーザビリティはスローガンになります。 データの回復の成功率は、災害の信頼性を決定し、ノードが直接長期データの生存に関連した結果、応答のコピーを再構築する能力を決定します。 データ バリュー密度は側面によって要求の側面を、価値の高いデータセットのための差動の多重化器および高デマンド モデルと決定し、より大きいリターンを傷にし、頻繁にデータ呼ばれます。 インセンティブは、宣言された容量ではなく、実証済みのサービスに与えられるべきです。
肯定的なインセンティブは、単独で十分ではありません, 結合の誓約, 罰, 仲裁は、同時に配置されている, そして、ボトムアップの変種は、満たすべきです: 不正行為の予想される利点は、罰される予定されたコストよりも低くなければなりません, そうでなければ、任意の認定メカニズムは、経済の合理性によって迂回されます. pledgeノードは、ユーザビリティの素晴らしさのコストであり、その大きさは、受け取ることの計算値とデータ値に比例すべきである。Filecoinの設計では、リポジトリは約束された計算書にプレモルトゲージを支払うために必要があり、ワイヤがデモンストレーションウィンドウにドロップされ、セクターの永続的な再完結は、ヘビアー終了ペナルティをトリガーし、その意味は、期限切れと悪意のある離脱落と悪意のある間を遮断することである。 仲裁は、証拠主導の紛争のチェーンに基づいています: ユーザーがデータが利用できず、ノードは通常のサービス、チャレンジ録画、サンプリング証明書およびインシデントログを主張する場合、マニュアルの介入を必要とする紛争を検証するための機械読み取り可能な基盤を形成します。
AIシナリオには、より困難なガバナンス層も備えています。どのようにして、トリップアートナイトが壊れるのでしょうか? データコントリビューター、モデルコントリビューターのトレーニング、ストレージノードのホスティング、究極の呼び出し値に貢献しているすべてのモデルは、直接観察することは困難です。 測定可能なチェーンイベントのベース値アトリビューション:データとモデルのサブカウントと自動決済は、指紋と血液リンクのバージョンによって各呼び出しに結び付けられ、その後、自動的にアカウントの事前書き込みプログラム可能な部分に分割され、ポストファクトのRIPPLETIONを回避します。 これは BLACKLIST と FORFEITURE メカニズムが伴います。これは、悪意のあるデータのアップロード、著作権侵害、およびモデル盗難に対して仲裁されると、その後続の悲しみや凍結を認めます。 さもなければ、偽り知らずの結果があります。資産化が成功するほど、より多くの紛争が分割され、延期され、最終的に崩壊するのは、まさに環境的信頼そのものです。
コンプライアンスはパッチではなく、結合構造の期間ではありません。 セキュリティベースラインは、エンドツーエンドの暗号化、レイヤキー管理とサイクルの回転、HashiとMerkleの約束を改良し、ダウンロードが検証でき、複数のコピーとデコードされ、カバー障害の回復に組み合わされていることを保証します。データのレベルのプライバシーの両面アクセス制御は、承認の撤退、ワンタイムおよびタイムバードの承認をサポートし、監査バックプレイを容易にするために、重要なアクセスと操作に関するマークを残します。 コンプライアンスは、最も脆弱で高価なリンクです。データのローカリゼーションとクロスドメインの送信戦略は、削除、アクセス、および監査リクエストの標準的なプロセスインターフェイスで構成する必要があります。最も困難は、削除できる天然の競合を改ざんしないようにすることではありません。利用可能なソリューションは暗号化された拭きとインデックス化無効です。キーの破壊は、秘密のテキストを明らかにし、データの回復不能をレンダリングし、チェーンを維持することによって削除を要求を満たすことです。 パイロットから生産までのしきい値の3つの段階があります。まず、最小限の信頼できるクローズドループが確立され、オブジェクトストレージ、チェーンの固定、完全性検証、基本制御が安定化され、受諾が利用可能で、読み取りと書き込みの成功率、アンカーはオブジェクトバージョンと整列され、失敗の回復を実行することができます。その後、AIの資産化とインデックス作成ガバナンスが導入され、データセットとモデル資産管理が導入され、バージョンスペクトラム、ベクトルインデックス作成熱とコールドレイヤー、モデルの承認が、モデルの承認をインデックス化して、データが記録され、再構成され、再構成され、再構成が確認され、再構成されます。 インジケータシステムは、戦略的なシステムであり、プレゼンテーションレポートではありません。 ストレージプログラムは、技術的な項目のみが書面で書かれている場合、純粋にコスト センターに崩壊します。, ビジネス結果なし; 推奨事項は、3つの層で作られています。: 基礎技術指標(可用性、P95 / P99時間の遅延、スループット、RTO / RPO、エラーレート)は、システムの健康に答えます。, AIは、特定の指標(データのトレーサビリティ率の訓練、モデルの回復能力率、妥当性検証カバレッジ、インデックスの一貫性)は、モデルの品質に応答します。, 運用インジケーターは、(実質的には、トラフィックを削減します), 実際の結果は、実際の結果は、システムと、実際の結果が3つの値ではなく、実際の結果は、実際の結果は、実際の結果と一致しません。 5つの最も一般的な障害ポイントは、バージョンガバナンスのないストレージ、データが可用性、可用性、または再発の代表的ではありません。 容量単独は、可用性の証明によってサポートされていない、および報酬は、スタック容量の光を誘発するためのボリュームによって提供されます。 熱と寒さの層が行われるが、同期戦略が実行されず、インデックスバージョンは閉鎖されません。 コンプライアンス戦略は、特権、ログブック、失調、遅延応答の除去が、移行を欠かせません。 移行および移行が、移行が、移行が、移行を制限します。
Bitrootの完全クローズリング:データ、モデルからAIエージェントまで
このリングでは、Bitroot は、AI アセットの重要な行動を決済イベントに変えることができます。データセットの登録、モデルリリース、ベクターインデックスの復元、AI エージェントの呼び出し、推論のログのアンカー、権限の委任、紛争の課題と仲裁結果。 チェーンは、すべてのデータを含む必要はありませんが、これらの行為の最小限の証拠。 このようにして、データ、モデル、アルゴリズム、アプリケーション間の価値の関係は、プログラム可能なサブアカウントと監査可能なガバナンスに対する動的なコミットメントを超えて行きます。
Bitrootの運用および生態学的拡張でこのメカニズムを配置するには、ストレージインセンティブは別々のハードウェア補助金として設計すべきではありませんが、AI Stackフローの一部である必要があります。データコントリビューターは、データのトレーニングや転送から恩恵を受け、モデルコントリビューターはモデルサービス、ストレージ、および検索ノードから恩恵を受け、継続的な可用性と低遅延の恩恵を受け、認証およびチャレンジノードは、非アベイラビリティ、インデックス作成、またはドリフト権限を発見するための報酬を受けています。 このようにして、Bitrootの経済システムがアップロードではなく、「継続的に有益なものを提供」で報います。
ストレージはコストセンターではありませんが、信頼と価値配分システム
AI時代の流通貯蔵は、オブジェクトのストレージ製品の交換ではなく、集中的な物語の追求ではなく、より困難なものの4つです。 被験者を横断するガバナンスの秩序、データとモデルに対する責任の連鎖、および持続可能な経済インセンティブ。
単層構造は、これらの目的をカバーしていません。 より現実的な道はモジュラー構造です: コンテンツサイトの整合性、セキュリティ時間次元の可用性の貯蔵の証拠、重要な歴史の永続的な層、熱圏のオンライン経験、ガバナンスおよびクリアランスを保護するチェーン。 エンジニアリングの理由は妥協しません。 着陸の焦点は、最も機能的ではありませんが、最初にクローズされた円に建てられ、最初は最も小さな信頼性のクローズされた円で、AI、検証可能な検索、自動化されたガバナンスの資産化が続いています。
3ステップの操作です。 最初の日は、8フィールドのデータ在庫を完了し、3日目は、アクセス、ストレージ、検索から実際のビジネスエリアでの検証まで最小限のリンクを実行し、7日目はP95時間とユニットコストで移行し続けます。 そこで、コンセプトからエンジニアリングコンセンサスへとチームを移しました。
また、合意の組み合わせに関係なく、コスト、期間、耐久性のトレードオフがあり、すべての操作に適した単一の回答はありません。 本当に持続可能なプログラムは、ボード後の長期静的構成ではなく、明確な境界下にある連続的な反復パターンから来ています。
プロジェクトの将来のフェーズアウトは、多くの場合、TPSにとってそれほど高くはありませんが、データ責任チェーンは不明です。 AI時代では、ストレージはデータを入れることではありませんが、データが常に実証されることを可能にします。
特定商取引法に基づく表示
実際のAIチェーンの競争はTPS、ガスまたは確認の時間と比較して終わらない。 性能は入口ですが、端ではありません。 AIアプライアンス年齢を入力すると、チェーンシステムは取引だけでなく、データバージョン、モデル呼び出し、アルゴリズム、推論レコード、エージェントの行動、複数の進捗分布を運ぶことを意図しています。
また、Bitrootのreservoirの判断です。ストレージは補助モジュールではありませんが、AI Stackの一番近いレイヤーは、値のソースです。 データを証明できるかどうか、モデルが再現できるかどうか、コールが監査できるかどうか、送金が自動的に配布できるかどうか、または集中型のAIネットワークが長期的に真に有効であるかどうか。
Bitrootは、より高速な実装を追求するだけでなく、AIアセットを識別できるようにするインフラを構築するつもりはありません。 Parallel EVM および Pipeline BFT は、高周波チェーンイベントのキャリング容量、分散ストレージおよび検証可能なメカニズムが、プログラム可能なサブアカウントおよびチェーン・ガバナンスが持続可能な経済インセンティブへの貢献を翻訳しながら、AI データとモデルの信頼拠点に対処します。
AI エージェントがユーザーの代理で行動し始めたとき、モデルとデータが交渉可能なアセットになったら、ストレージは「コンピューティング、ストレージ、および推論サービスが同じ値ネットワークに入るとき」ファイルを配置する場所の問題ではありません。
次世代のインテリジェントネットワークのAIパブリックチェーンと価値分布システムの信頼拠点となります。
Bitrootでは、将来の本当の重要性は、最もデータを持っている人ではないようですが、誰がそれを実証、アクセス可能、任意の時間で説明し、最終的に価値の決済に参加することができます。
Bitrootについて
Bitrootは、AIオリジナルの構造でレイヤー1パブリックチェーンプロジェクトに並行して焦点を合わせています。 Bitroot は、EVM 互換の技術ルートを使用して、AI エージェント、DeFi および Web3 アプリケーション向けの高性能で低コストの実装環境を、並列実装機構、コンセンサス最適化、AI インターフェイス設計を通じて探索します。
この論文は、貢献したものであり、ブラックビートの視点を表すものではありません。
