
從可儲存到可解析: Bitroot 如何重製 AI 資料值層
Bitroot 一方面通过 EVM 和 Pipeline BFT 的平行化,提供性能高的環境,另一方面通过分布式訓練,推理網路,可信實施和AI資產管理,將數據,模型,算法和Agent 應用程式連接到清除網路. 在這個網路中, 儲存不是一個孤立的模組, 而是一個決定數據是否准确的基礎, 模型是否可以重现, 微积分是否關閉, 以及贡献者是否有能力維持收益的基礎 。

资料来源:Bitroot
儲存不是成本中心,而是Bitroot AI Stack的值分配系統
許多團隊意識到, 數據並未失傳, 服務亦未停止, 但問題出現於另一種方式: 資料存檔裡的訓練資料正在慢慢检索, 由誰來證明總有數據, 由誰負責版本。
理解儲存為從中央雲移動檔案到鏈條下的網路,會在NFT中繼資料時代持續。 一旦操作延伸至 AI 訓練語言、模擬權重與向量索引。
目前大多數團隊都認為儲存是最佳的物流成本, 這篇文章只回答一個問題: 如何构建可核查、可管理和可持续的分布式儲存方案。 依據創用CC授權使用, 判决书主要依据官方协议文件以及尽可能可核实的信息。
就Bitroot而言, 儲存位置更精确的是 AI Stack 的值分配基數 。 Bitroot 一方面通过 EVM 和 Pipeline BFT 的平行化,提供性能高的環境,另一方面通过分布式訓練,推理網路,可信實施和AI資產管理,將數據,模型,算法和Agent 應用程式連接到清除網路. 在這個網路中, 儲存不是一個孤立的模組, 而是一個決定數據是否准确的基礎, 模型是否可以重现, 微积分是否關閉, 以及贡献者是否有能力維持收益的基礎 。

俱系并中. 它在AI不起作用
在過去的幾年裡, 儲存問題常常會減少到一個或另一個, 這兩條路在人工智能場景中是不可持续的。
全鏈壓力很特別 訓練數據、模型權重、推理紀錄、向量索引一般都是高容量、高頻率更新, 完全中心化的運作速度很快。
更关键的是, 數據版的管理決定了誰會主动加入迭代模型;能否證明有數據存在, 水庫不再是物流系統 而是價值分配系統。
所以有條件的儲存結構必須一次回答四個問題: 數據是否真實和可取, 數據是否可追蹤到模型的版本, 能力與效益是否可控制。

Bitroot 輸入點: 讓 AI 資料從"可儲存"移到"可清算"
那就是Bitroot需要填充的地方. Bitroot的存檔敘述不應該停留在「數據放在哪里」, 而是回答「數據如何被證明, 但他們的Hashi承諾、版本關係、許可策略、呼叫記錄與收入事件需要Bitroot上的统一鏈路證據。
Bitroot的高投入和低效率事件不只是服務DeFi交易, 數據集的更新將被固定, 模型版本將被登記, AI Agent呼叫會被解決, 搜尋結果會被仲裁, 儲存節點的可用性會繼續受到質疑和獎勵。 才不會把 AI 資料資產鎖在集中的數據庫裡。

三大范式 都無法單獨穿透
分布式儲存的競爭從來就不是最先進的, 而是你數據結構中最適合的。
內容搜尋網絡解決是否是數據, 根據IPFS官方文件, CID基于內容的HASHI身份, 不依據位置:同樣的內容在相同的編碼設定下產生相同的CID, 只要內容的字節變更, CID就會變更. 此功能使得它自然地可以進行完整性的驗證,加权和跨系統的參考,也是數據驗證的底部能力. 但內容的位置不等于經濟上可持续, 許多團隊推進的第一個坑就是這裡:技術上。
儲存市場網絡是利用經濟機構來買取時間維度。 根據Filecoin的檔案, PoRep證明這本獨一無二的抄本實際上在最初的信封中, WindowsPost通常24小時安排憑證周期,切入多個30分鐘的驗證視窗,如果寄存器在視窗中不提交有效的證件,它會引发抵押的充公和儲存容量的減少. 在這個系統中,易用性是連續的考驗,而不是合同后一次性的承諾. 這項合同性、可稽核的模型適合於中長期的歸檔、備份和數據市場, 但更像是被證明的長期儲藏。
永久儲藏網絡走另一條路線, 部分上傳成本將進入儲藏資源資源池, 以支付長期的儲藏激励, 它適合於歷史檔案、關鍵文件、著作權材料以及不可移除的紀錄。 短板也是很明顯的: 永久性不自动构成高低延遲。
除了這三种基本范式之外,工程兩種共同的组合也是值得权衡的. 一是數據提供層和物件儲存的混合, 另一項是云加协同性、低延迟性、更好的抗災能力。
無論怎樣 吃光所有場景的協議都行不通 有效的方法按數據類型排列:去除持久性、检索時間和遵守性。
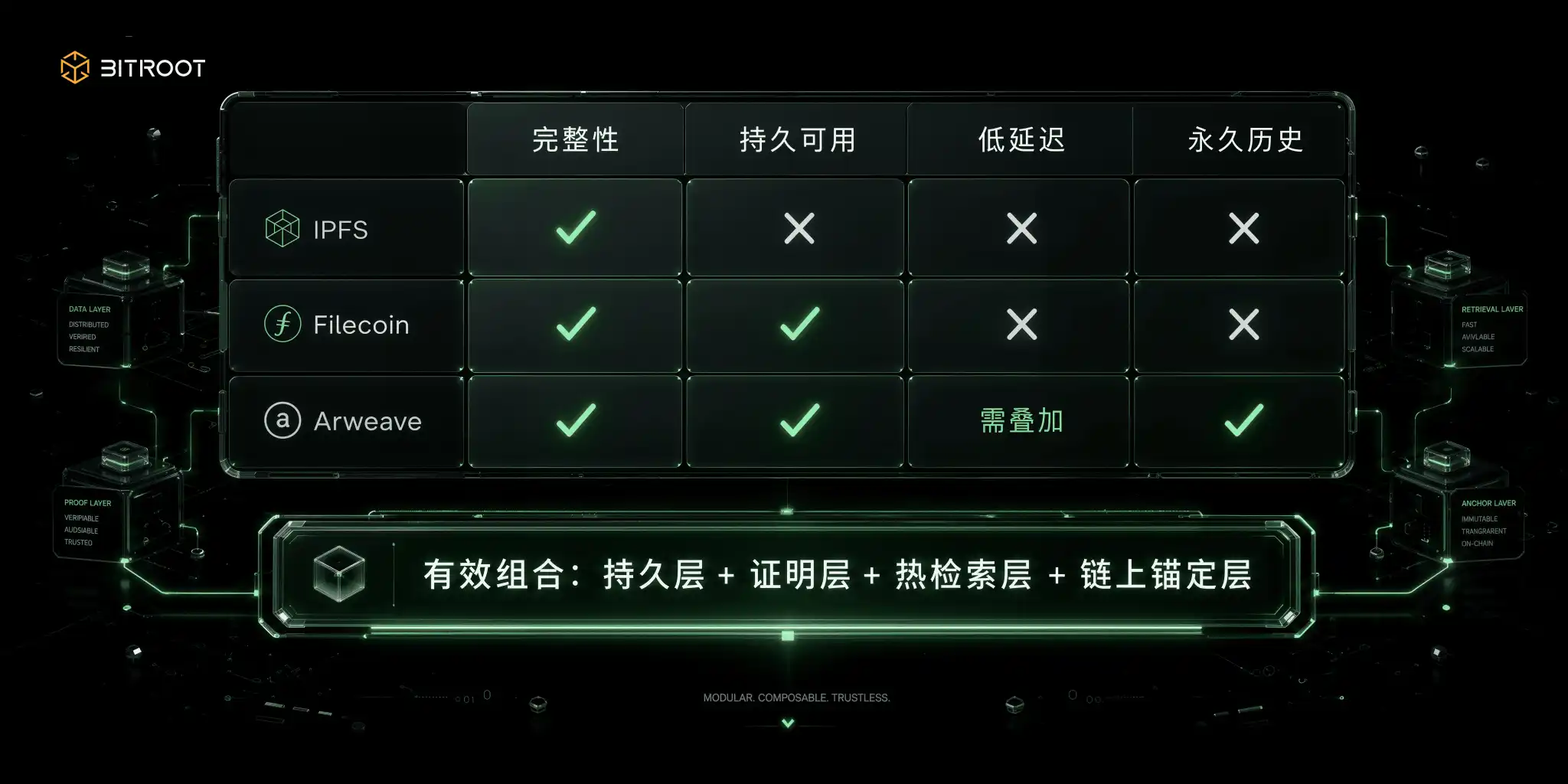
Bitroot 所選擇的空間, 也應該依據此組合邏輯: 而不是用 IPFS 、 Filecoin、 Arweave 或 物件來取代, 內容位址用于數據身份與完整, 儲存憑證用于长期提供, 永久層層用于關鍵歷史與文件, 熱搜尋層用于 AI 應用實驗, 也就是說, Bitroot 不需要是所有資料的物理寄存器, 而是對 AI 資料流的可靠描述 。
AI 儲存困難, 不是檔案, 而是執行製作連結
在 AI 設定中, 儲存物件至少被分成四類: 訓練資料, 模型權重, 向量索引, 推理紀錄 。 這四類主題的生命周期、存取方式和價值密度完全不同。
培訓數據的問題不在能力上, 許多團隊將訓練數據問題與TB等級的儲存成本等同, 問題更嚴重的是漂移:只要清潔規則、樣本選擇阈值或校准變化、模式行為變化, 根據MLFlow的模型和數據追蹤做法, 這項原則在連結上依然有效: 原始資料不需要連結完整, 至少要附加三個標記, 數據版本、訓練操作、模型版本。
模式重點的問題往往不在于能否下載, 一款型號進入製作, 通常會經過幾種灰階、主要用途、回滚及退役的狀態, 一個成熟的模型登記中心記錄血脈、版本化名、簽名限制和審查標籤。 模式版不僅僅是文件, 哈希。
向量索引的難點集中在一個地方: 溫度和冷度層后的一致性. 傳媒搜索、低延遲與低成本對抗, 熱圈依靠內存或高性能索引服務, 沒有一個一致的中繼資料與同步策略, 因此矢量系統必須支持兩件事,索引构建过程可以被追蹤,熱圈索引版本可以和冷主資料調和,這正是同時的文字可以驗證搜尋的方法。
難以建立推理記錄, 它既是安全審查材料, 也是隱私風險的源頭。 可能的方法是三層迷信、不敏化的內容儲存、哈希對上鏈的承諾和存取權的授權。
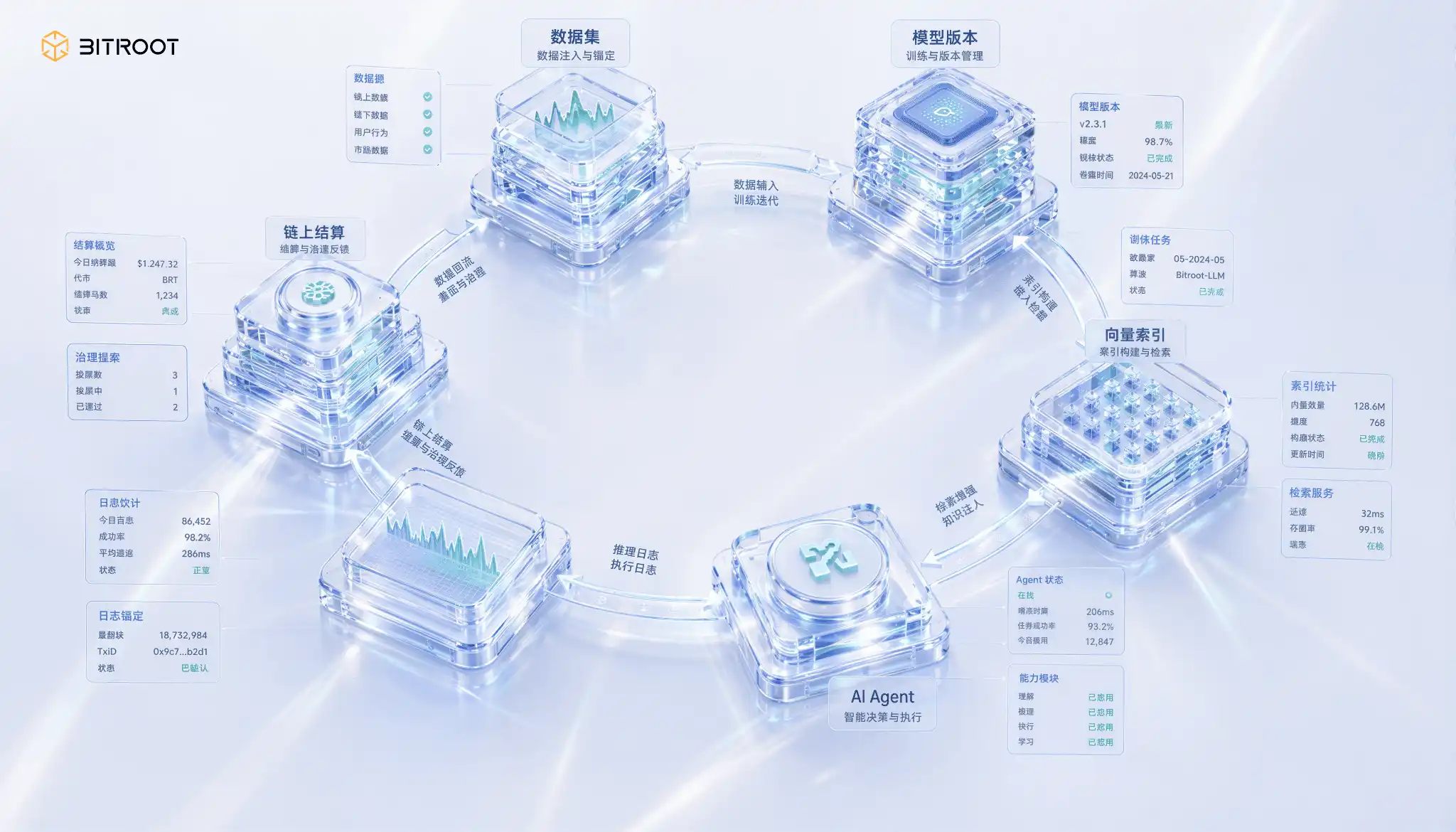
在Bitroot的 AI Stack 中, 這四個類型可以對應四種治理動作:主播與源碼登記的訓練資料, 資產登記與呼叫授權的模型加权, 熱冷分层與一致性的矢量索引, 不敏感儲存的推理紀錄和審核承諾。 但他們需要建立统一的資產ID、版本光谱, 這讓在數據資產、模擬資產與代理應用程式之間形成一個可重用的商业封閉圈。

然其底. 其底
缺乏可用性證據的儲存承諾,基本上相当于生产環境中的承諾。 發行儲存包括至少三種方式:完整性、可用性、行為性、驗證性。
完整性由內容位置加Merkle的承諾證明。 內容位置確保數據指紋穩定, 專案的重點是, 您可以以分數來證明物件的子集, 而不需全部讀取 。 大型模型權重、大型語言與多媒體資料。
可用性体现在挑戰机制和樣本驗證上。 Filecoin的習慣顯示, 可用性不是口述的SLA, 而是一系列周期性挑戰的證據, 在提供數據方面, 根據Celesty的資料可用性樣本設計, 資料由 kxk 擴大至 2kx2k 矩阵, 光節點通过多輪隨機采样和概率积累, 而不必下載全部資料以建立對可用性的高概率信心。 這是人工智能外移的靈感:并非所有的可用性都需由下載來充分驗證。
行為受到鎖定和事件痕跡的影響。 儲存系統最困難的是行為:誰上傳什麼,誰改變策略,誰啟動移動,誰使用敏感的模型. 如果這些行為不融合成一串事件, 而不是把所有細節都放在鏈中。
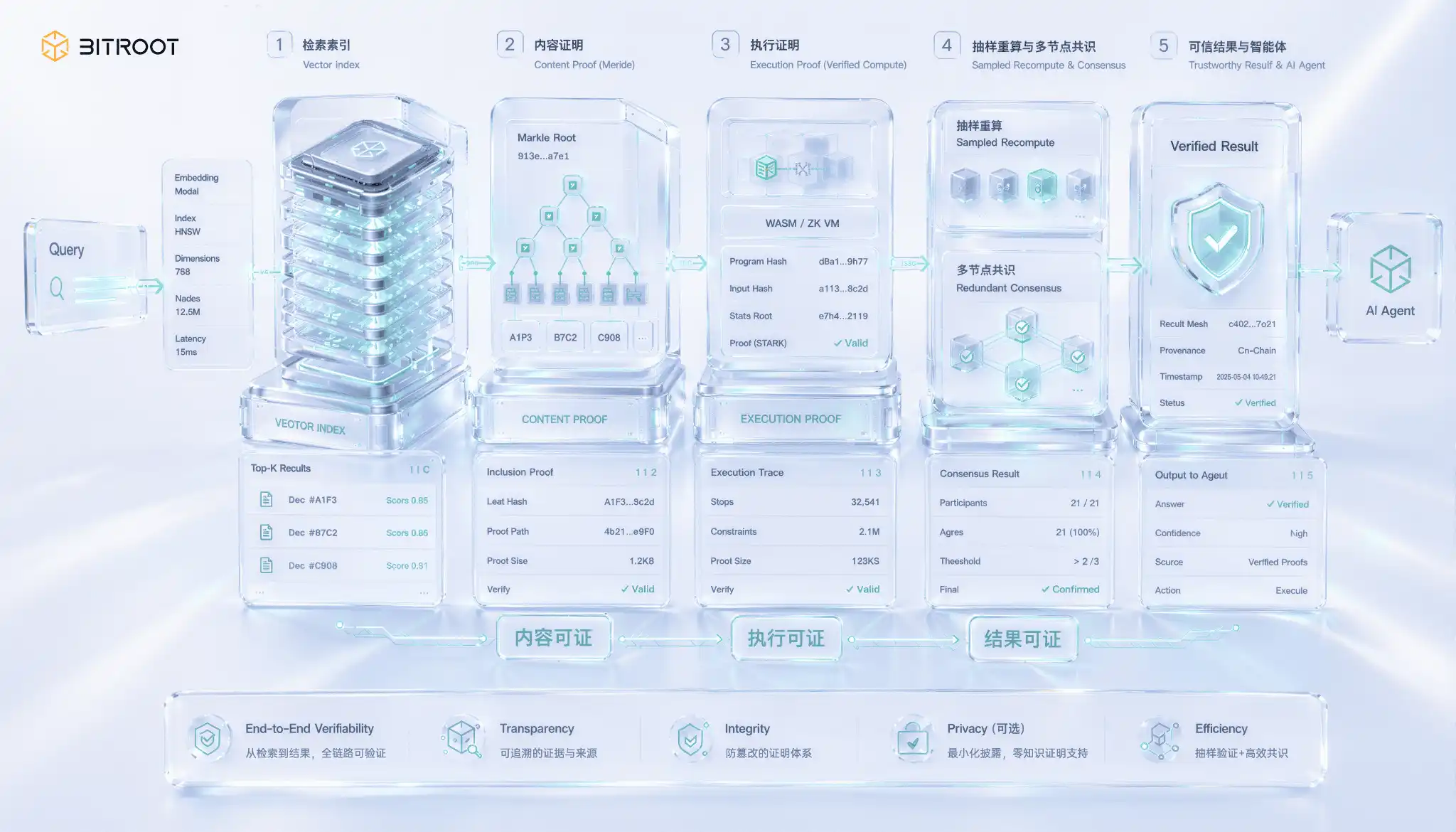
搜尋憑證是 AI 中唯一且最困難的一幕, 問題出現在一個容易被忽略的缺口: 傳回結果與傳回正確結果不一樣 。 向量搜尋節點完全可以取出一個过时的索引, 甚至可以跳過最接近的鄰居, 回到你看似合理的頂端 K 中, 你無法單獨看到返回的價值 。 文意取材的產品本身不能自我證明, 這種差距從質量升至信任。
拆解可搜尋性實際上是改變的三層保障 第一個關卡是證明返回的矢量真的屬於應許的索引版本, 建立索引的數據結構, 承諾默克勒將索引連結在它的根部, 用封裝憑證傳回結果, 以确保節點不是編造或篡改數據的 。 第二層是執行一個憑證, 查詢實際上运行在應許的版本上, 而不是私人修改的索引上, 這要求查詢过程包含在可核查的計算中 。 第三層最難證實, 有結果, 返回的頂端k確實是最近一個量度。
高維度相近鄰居的製作规模的嚴格結果仍居最前列, 實際的工程解決方案是自下而上,而不是一步一步的:第一,將索引版本和建置參數連結,以确保可追溯性;第二,重新計算一些查詢的樣本,按比例重做查詢,把查詢結果與數據可信度比對,而不是逐篇文章的證明;第二,讓多個獨立節點超负荷,就回復結果达成共识,提高作弊單一點的成本;第二,只有在有歧見或共识的情况下,才將重新全面查詢提升到一連串決定。 在大體系統中, 數據確認和爭議的增長往往比文章所嚴格證明的要容易。
對 Bitroot 來說, 可核查的搜尋不是孤立的儲存函數, 而是可信 AIAgent 執行的一部分 。 如果你依靠外部知識基礎、模型重量或矢量索引做決定, 它讀取了數據的版本,呼叫模型的版本,並傳回已登記索引版本的結果. Bitroot可以將這些證據壓縮成一連串可查事件。

選擇的真正問題:不是選擇,而是群組
許多方案評論失敗, 正確的提法不是我們是否想使用協議, 而是我們的數據搭配, 建议采取四步。
數據資產先算數 至少要區分狀態資料, 物件資料, 检索資料, 稽核資料, 讓清單樣本成為固定的字段, 至少要分八個: 數據型態、 增長量、 峰值综合分配、 讀寫比例、 保留周期、 遵守程度、 目標時間展期、 成本上限 。 一旦字段團結,跨隊的選擇交流就快得多了。
重新定義服務目標 。 P95/P99時間展期, 恢復時間 RRO, 恢復點 RPO, 可用性目標。
然后建立能力地圖。 永久儲存、周期性可用性證明、低延遲取用和施政等類別。
确定移民门槛。 哪些數據能讓轉變集中, 哪些指示器能引發移民, 一個實際的方法是設立一個雙倍的阈值:一項TB成本超預, 任何治理都不可能沒有阈值,而过渡时期就成了永久的。
降落方案:五层结构,有生力、可取和可管理
建築值不依數量排序,而是以可核查的環路形式存在. 依據前一個框架,此程式被凝結成五層: 連鎖锚定層, 物件儲存層, 索引搜尋層, 可使用性憑證層, 按鍵存取層. 其目標是將可核查性能轉變成缺省能力。
在 Bitroot 中, 這五層可以被进一步理解為 AI Stack 儲存治理模組: 平行 EVM 提供高頻率的锚定與清除能力, Pipeline BFT 提供低延迟的确定性, 分配儲存網路到大物件與歷史資料, 索引搜尋層服務 AI Agent與應用呼叫, 可用憑證層將節點服務的質量轉譯為信用與獎勵。
連鎖主題被保持在最小的必要狀態:數據承載、版本指紋、權限策略摘要、和解事件。 大物件不是用鎖鏈來證明它的存在和正確的版本. 它保留了鏈子的概率, 也不允许被大文件拖下。
在Bitroot的情況下, 連鎖主題不只是「哈希紀錄」, 數據集、模型權重、向量索引和推理紀錄都可以以最適當的方式儲存在鏈下, 但他們的版本承諾、經授权狀態、呼叫記錄和收益的歸屬需要進入Bitroot鏈中。 因此,鏈式存储器负责承載荷載,而Bitroot负责承载信任。
物質儲存層載有真數據,采用解碼和复制的混合策略:高值,低頻率存取的物質有錯誤,中值,高頻率访问的物質有搜索效率. 這項策略不是靜態配置。
索引搜尋層將中繼資料與向量索引整合到統一的目錄中, 所有索引版本都需要登入源碼版本并建立參數, 否則索引漂移無法追蹤 。
在可用層面的憑證中量化節點行為 。 抗爭成功率、回應時間框架及善後成功率都以可信度、評分與獎勵分配為標準。
關鍵存取控制及遵守 高敏度數據被分類為按鍵與限時授權, 權限操作本身也留下了防止配置漂移的標記 。
五層是關閉的,不是單向的水線: 數據存取後, 切片會編譯成物件層, 在寫入後建立索引, 固定連結; 網路查詢溫層已脫離, 不到一擊回冷層; 返回結果, 同时啟動完整驗證與授權驗證, 這個鏈子的真正價值是 四個問題可以在任何節點或時刻被回答: 資料來自何處, 目前的版本是什麼, 誰有權存取。
這也是Bitroot適合AI儲存治理的關鍵原因。 要求 AI Agent 、 模式版本的切換 、 數據授權的變更 、 搜尋結果的爭議 、 都不是低頻率的後台操作, 如果下層鏈未能提供足夠低的延遲確認和足夠的吞吐量, Bitroot和管道BFT的平行EVM不僅值得更高的TPS。

我們用我們而不是能力來決定回報
要讓儲存長期運作, 只有容量才能得到獎勵, Filecoin 機制修改了這點: 它引入了質量調整的功率概念, 允許接受真實的儲存定單, 特别是有效有效的定單, 也就是最小的儲藏空間量度單位, 這點子值得任何自我建築的刺激。
讓它成為一個可執行的刺激功能, 容量決定了基數分享, 并解答你承諾的空間 。 網路费率與回應時間決定服務質量因數, 并解答這間空間是否真正需要, 數據恢復的成功率決定了災難的可信度, 在節點下降後重建反應副本的能力直接與長期數據的存续有關. 數據數值密度並列決定需求, 高值數據集和高需求模型的差異乘數, 刺激措施應該是被證實的服務,而不是宣示的能力。
光是正面的刺激是不够的, 具有约束力的承諾、懲罰、仲裁同時到位, 在Filecoin的設計中, 寄存器必須用應許的計算法支付預價, 一旦電線掉入演示視窗, 仲裁基于一系列由證據引發的爭議: 當使用者聲稱數據不可用, 節點要求正常服務時。
如何打破三方利益? 由數據提供方的語言支持, 訓練模組提供方, 托管儲存節點, 數據與模型的分計數與自動解析, 以指紋與血緣連結相連, 由於對惡意數據上傳、著作權侵犯及模型盜竊等案件進行仲裁, 否則會有反直覺的結果:資產化越成功。
遵守不是修补,而是有约束力的建構期: 安全基准是端到端加密、分層的金鑰管理及周期旋轉、超級改善Hashi與Merkle承諾, 符合性也是最脆弱且成本最高的連結 : 數據本地化和跨域傳輸策略需要設定, 需要標準的流程介面來刪除, 存取, 以及審查要求; 最困難的不是篡改可以移除的自然衝突, 可行解決方案是加密的擦除及索引無效者: 關鍵的毀壞使得秘密文字無法回收, 使得數據無法被检索, 並且讓刪除要求得以滿足。 從實驗到製作的门槛有三個階段:第一,建立最低可信封鎖的環路,物質儲存、鏈鎖、完整檢查和基本控制穩定、接受、讀寫成功率、定點與物質版本一致、失業回收、實施AI資產化和索引治理、引入數據集和模擬資產管理、版本频谱、向量索引熱冷層、呼叫和培训數據源的模擬授權、接收和檢查訓練是可追蹤的、模式可轉載的稽核、熱層遵守、索引重建效果得到控制;最后,恢复和自動治理得到認定、挑戰憑證、战略移動和獎賞自動、檢查可用憑證覆盖范围、延遲到風險處理、降低單位成本、战略變轉回列。 指示器系統是战略系統,而不是呈現報告。 如果只寫有技術項目, 沒有企業成果; 建議分三層提出:基礎技術指示器(可用性、P95/P99時間延遲、吞吐量、RTO/RPO、錯誤率) 回答系統的健康, AI 具体指示器(訓練資料可追溯率、模型可回收率、推理驗證覆盖范围、索引一致性) 回答模型的质量, 運作結果指示器(數據供應增長、降低呼叫成本、節點活動、資產交易尺度) 回答系統的價值, 三層之間的映射關係, 五個最常用的失敗點大多被先期规避:沒有版本治理的儲存,數據不代表可用性,可用性或重现性;能力本身不支持可用性證明,而提供獎賞的量引發堆積容量光;熱和冷層被做,但沒有同步策略,索引版本未被關閉;遵守策略之后,權限、日志、不敏化、移除晚期回應等成本增加;过渡结构不退出和集中化是合理的道路,但缺失的移位阈值可以使轉變固定和偏离原意。
Bitroot 完全關閉的環: 從數據, 模型到 AI 代理
在這個環境中, Bitroot 可以將 AI 資產的每個關鍵行為轉換成和解事件: Dataset 登記, 模型釋放, 向量索引重建, AI Agent 呼叫, 日志定點推理, 授權與撤銷, 爭議爭議與仲裁結果 。 這條鏈子不需要包含所有數據 而是這些行為的最小證據 數據、模型、算法與應用程式之間的價值關係。
數據提供者從數據的訓練或傳輸中獲益, 模擬提供者從模擬服務中獲益, 儲存與回收節點從源源不斷的提供與服務低的延遲中獲益, 憑證與挑戰節點因發現不可用性、索引漂移或權限异常而獲獎。 Bitroot的經濟系統並非靠上傳。
儲存不是成本中心,而是信任和價值分配系統
在AI時代, 分配儲存並未涉及取代一個物件的儲存產品, 或追求正義化的叙事。
單一協議的單層結構不包含這些目標。 一個更現實的路徑是模块化的結構:內容站點完整, 安全時間維度的儲存證據, 這不是妥协 而是工程原因 降落的焦點並非最有功能, 而是首先建立於封閉圈內, 最小的可信封閉圈先跑。
三步作么生. 第三天以P95時間和單位成本進行移動门槛整體。 由於此。
也存在一個現實的界限需要認同:不管協議合併, 一個真正可持續的程式來自於在明確邊界下持續的迭代模式,而不是棋盤後的长期靜態配置。
專案的未來淘汰對TPS來說常常不是太高, 但數據責任鏈卻不清楚; 在AI時代, 儲存並非關于放入數據。
总结
真正的AI-chain競爭與TPS, 表演是入口,但不是結束。 在進入AI應用器時。
也是Bitroot對水庫的判斷:儲存不是一個附属模組, 數據能否被證實, 模式能否被重製, 呼叫能否被審查, 收益能否自動分配。
Bitroot並非要建立只追求更快實施的連結, 同時的EVM和管道BFT處理高頻頻率連結事件的承載能力, 分布式儲存和可核查的机制處理AI數據和模型的信任基础。
當模型與數據開始成為可交易資產時, 當計算、儲存與推理服務進入同值網路時, 儲存不再是「放在哪裡」的問題。
它將是AI公共連結和下一代智慧網路的價值分配系統的信任基础。
在Bitroot, 未來的真正重要性似乎不在于誰擁有數據最多。
關於位根
Bitroot 是與第1層公共鏈路專案平行的焦點, Bitroot 使用 EVM 相容的科技路徑, 透過平行的執行机制、共识优化及AI介面設計。
這篇論文來自於一份贡献。
