
世界モデルが予測から計画、HWM、長距離制御の課題に移動
4月3日、NYUとMeta FAIRチームは、Late Worldパフォーマー(HWM)と紙の階層計画を発表しました。 元のアドレス: (https://arxiv.org/abs/2604.03208) 紙は未来のより現実的な映像を生成することに焦点を合わせませんが、代わりに世界モデルの長期実装の挑戦に変わります。 タスクチェーンが長くなると予測が蓄積され、アクション検索スペースが急速に拡大します。
導入事例
近年の世界モデルの研究は、学習と将来の予測の現れに最初にありました。 モデルは世界を理解し、未来のために押します。 このルートは、結果の代表的なセットを生成しました。 V-JEPA 2の特長ビデオポイントは、先述のアーキテクチャを埋め込む 2— メタは、2025年にビデオ世界モデルを立ち上げ、インターネットビデオの事前トレーニングの1万時間以上で、少量のロボットインタラクティブデータと組み合わせ、世界モデルの理解、予測、ゼロサンプルロボティックプランニングの可能性を実証します。
しかし、モデルは、それが長いミッションと同じではないことを予測します。 制御の複数の段階に直面して、システムは通常2つの圧力に遭遇します。 1つは、長いロールアウト(連続マルチステップの演習)で予測されたエラーの継続的な蓄積であり、ターゲットの偏差へのパス全体の脆弱性が増加する。 もう1つは、計画コストの継続的な増加につながる、地平線の成長と運用検索スペースの急速な拡大です。 世界のモデルの底学習ルートを記述する代わりに、HWMは、アクション条件を持つ世界モデルにレイヤー化された計画構造を追加し、システムがローカルアクションを処理する前にフェーズパスを整理できるようにしました。
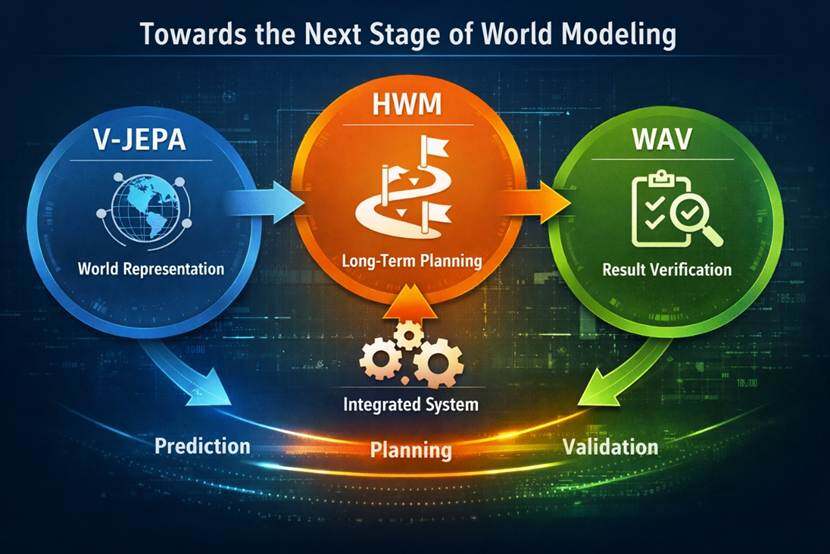
技術的には、V-JEPA 2 (https://ai.meta.com/research/vjepa/) は、世界表現とベース投影を好む、HWM は長期計画を好む、WAV世界行動計画:フォワード・インバース・アシムネトリーによる世界モデルの自己改善https://arxiv.org/abs/2604.01985 より多くの偏見モデルは、独自の予測を特定し、変更します。 3つのラインは徐々に縮小します。 世界モデリング研究の焦点は、将来の予測から予測能力の変換に、実装可能、リバーシブル、検証可能なシステム機能に移行しました。
I. なぜ長期制御は世界モデルのボトルネックのまま
長期制御の難しさは、ロボットのミッションで見やすくなります。 メカニカルアームの操作など、カップは分離され、引き出しに入れられます。これは単一の動きではなく、一連のステップです。 システムは、オブジェクトにアプローチし、態度を調整し、キャプチャを完了し、ターゲットポジションに移動し、引き出しを再処理し、配置することです。 チェーンが長くなると、両方の問題が同時に発生します。 一方、予測されたエラーはロールアウトと反対側に蓄積し、モーション検索スペースが急速に拡大します。
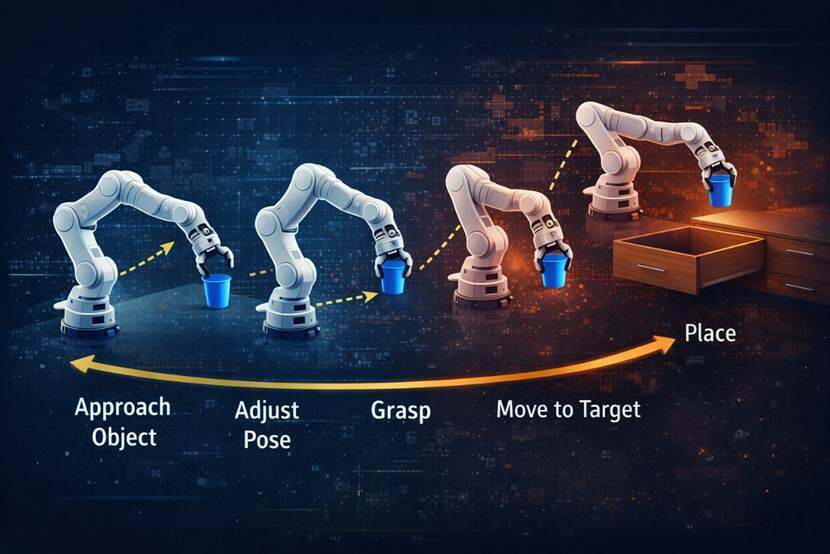
システムの欠如は、多くの場合、ローカルをプロジェクトする能力ではありませんが、長期目標を段階に整理する能力です。 ターゲットから局所的に逸脱している多くのアクションは、実際には目標を達成するために必要な中間ステップです。 たとえば、あなたがそれらを取る前にあなたの腕を持ち上げます、あなたはあなたの引き出しを開き、あなたの角度を調整する前に少し戻って回ります。
デモミッションでは、世界規模のモデルは、既に一貫した予測を提供してきました。 しかし、実際にコントロールシーンを入力すると、パフォーマンスが低下し始め、問題が続きます。 圧力は、標識自体だけでなく、計画レベルから来ています。
II. 計画プロセスの再構築方法
HWMは計画プロセスの元のレベルを2つの層に分けます。 上位は、ステージの方向を長時間のスケールで責任を負い、より短い時間スケールで部分的な実行を担当します。 1つのリズムでモデルを計画しないが、2つの異なる時間リズムで。
単一のレイヤーが長いタスクを処理すると、アクションチェーン全体を直接検索すると、通常はボトムアクションスペースで必要になります。 ミッションが長いほど、検索コストが高まり、予測エラーが複数のステップのロールアウトに沿って広がります。 HWMブレークアッププロセスの後、トップはより長い時間スケールでルートの選択だけを扱います、低いハンドルは移動のこの現在の部分の完了だけであり、全体の長いタスクはいくつかの短いタスクに分解され、計画の複雑性を減らします
また、高レベルのアクションが単に2つの状態の違いの記録ではなく、低レベルのアクションをより高いレベルのアクションに圧縮するコーダの重要なデザインもあります。 長い使命のために、キーは、開始点と終点の違いだけでなく、中間ステップが編成される方法だけではありません。 高レベルは、シフトだけを見ていれば、このアクションチェーンでパス情報を簡単に失うことができます。
HWMは、タスク組織に対する階層的なアプローチを反映しています。 多相プロセスの面では、システムはもはや1回限りの方法ですべてのアクションを実行し、より粗相パスから始まり、段落による実装と修正に従う。 この階層が世界モデルに入ると、予測能力は計画能力に着実に変化し始めます。
3。 0%から70%、結果が示したものは
実際の世界では、紙にセットされたタスクをキャプチャして配置し、システムは最終的な目標条件だけを与え、人工的に分離された中間目標を提供していません。 これらの条件下では、HWMの成功率は70パーセントで、単層世界モデルの成功率は0パーセントです。 達成できなかった長期的なタスクは、階層計画の導入で達成可能な結果になります。

また、プッシュオブジェクト操作や迷路ナビゲーションなどのシミュレーションをテストしました。 結果は、計画段階のコストを削減するだけでなく、成功率を高めるだけでなく、計画段階のコストを削減したことを示しています。 一部の環境での計画段階のコストは、約4分の1に削減でき、より高いまたは同等の成功率を維持できます。
IV. V-JEPAからHWMへWAV
V-JEPA 2は世界の道を表しています。 V-JEPA 2 は、インターネットビデオの 1 万時間以上で事前訓練された, 物理的な世界を理解し、予測し、計画するための世界モデルを得るために、ポストプリトトレーニングのためのロボットビデオの 62 時間未満と組み合わせて. 大規模な観測で世界標識を獲得し、ロボット計画に移行できるモデルを示しています。
HWM は次です。 既にモデルには世界的表現力とベース予測能力がありますが、複数の制御段階、エラー蓄積の問題、検索スペースの拡張ERUPTを入力します。 HWMは学習ルートの一番下式は変わりませんが、アクション条件で世界モデルに基づいてマルチタイムスケール計画構造を組み込んでいます。 モデルが段落ごとに進むためのステップの中間セットを形成する方法の質問に対処します。
WAVは、その一部について、認証能力をさらに重視しています。 戦術的な最適化と展開のシナリオに移動しようとする世界モデルは、予測だけでなく、歪みを起こしやすい領域を検出し、正しい領域を予測することはできません。 自分のモデルを調べる方法が心配です。
V-JEPAは、世界を代表する立場で発言し、HWMはミッション・プランニングに精通していますが、WAVは結果に偏っています。 同じ方向の3つが異なります。 世界のモデルの次のフェーズは、もはや内部予測ではなく、予測、計画、検証するためのシステム機能ではありません。
V.内部投影から実装可能なシステムへの移行
過去の世界の ' s モデリング作業の多くは、将来の状態予測の継続性を改善したり、内部世界宣言の安定性を向上させるために近づいてきました。 しかし、現在の研究の焦点は変化し始めており、環境判断と行動の両方に進化し、結果が入手可能になったら、次のステップを見直し続ける必要があります。 実際の展開に近づくためには、長距離ミッションのエラーの広がりをコントロールし、検索範囲を圧縮し、推論コストを削減する必要があります。
これらの変更はAIに影響します。 多くのエージェントシステムは、コールツール、ドキュメントの読み込み、いくつかのステップの手順を実行など、ショートリンクタスクを実行できるようになりました。 しかし、タスクが長いチェーンになると、中間再計画を必要とする多相化された1つは、パフォーマンスが低下します。 これは、ロボット制御の難しさとは根本的に異なっていますが、ハイレベルなパス組織の能力の欠如であり、ローカルの実装と全体的な目的間の切断につながる。
HWMが提供する階層的なアプローチは、パスとステージの目的に対する上級の責任を持ち、ローカルのアクションとフィードバック処理に対する責任を下げ、結果の追加検証を継続して、将来のより多くのシステムで出現します。 世界モデルの次のフェーズでは、将来を予測するだけでなく、予測、実装、および機能パスへのリビジョンを整理する焦点はもはやありません。
