
Từ có thể lưu trữ đến có thể thanh toán: Cách Bitroot tái cấu trúc lớp giá trị của dữ liệu AI!
Một mặt, Bitroot cung cấp môi trường thực thi trên chuỗi hiệu suất cao thông qua EVM và Pipeline BFT song song. Mặt khác, nó kết nối dữ liệu, mô hình, sức mạnh tính toán và ứng dụng Tác nhân vào một mạng có thể giải quyết được thông qua đào tạo phân tán, mạng suy luận, thực thi đáng tin cậy và quản lý tài sản AI. Trong mạng này, bộ lưu trữ không phải là một mô-đun biệt lập mà là cơ sở hạ tầng xác định liệu dữ liệu có thể được xác thực hay không, liệu mô hình có thể được sao chép hay không, khả năng tính toán có thể được giải quyết hay không và liệu những người đóng góp có thể tiếp tục nhận được lợi ích hay không.

Nguồn bài viết: Bitroot
Bộ nhớ không phải là trung tâm chi phí, nó là hệ thống phân phối giá trị của Bitroot AI Stack
Nhiều nhóm chỉ sau hơn nửa năm lên mạng mới nhận ra rằng lớp lưu trữ nên được chọn cẩn thận hơn. Dữ liệu không bị mất và dịch vụ không bị dừng, nhưng vấn đề lại xuất hiện theo một cách khác: việc truy xuất dữ liệu đào tạo đã lưu trữ ngày càng chậm hơn, độ trễ đuôi của truy vấn vectơ điểm phát sóng dao động từ mili giây đến vài giây và khi đến lúc xem xét một sự cố trực tuyến, không ai có thể biết mô hình đang sử dụng phiên bản dữ liệu đào tạo nào vào thời điểm đó. Lúc này, điều cần giải quyết không còn là mở rộng công suất mà là ba vấn đề khó khăn hơn: ai có thể chứng minh rằng dữ liệu luôn có sẵn, ai chịu trách nhiệm về phiên bản và ai trả chi phí dài hạn.
Hiểu về lưu trữ khi di chuyển tệp từ đám mây tập trung sang mạng ngoài chuỗi vẫn có thể duy trì được trong kỷ nguyên siêu dữ liệu NFT. Một khi doanh nghiệp mở rộng sang kho dữ liệu đào tạo AI, trọng số mô hình và chỉ mục vectơ, bộ ý tưởng này sẽ nhanh chóng trở nên không hiệu quả.
Hầu hết các nhóm vẫn coi việc lưu trữ là một chi phí hậu cần có thể tiết kiệm được nhiều nhất có thể. Đây chính xác là nơi nó bị đánh giá thấp nhất và có nhiều khả năng đưa ra lựa chọn sai nhất: trong chuỗi công khai AI, trên thực tế, lớp phân phối giá trị sẽ xác định ai kiểm soát dữ liệu và ai nhận được lợi ích. Bài viết này chỉ trả lời một câu hỏi: làm thế nào để xây dựng một giải pháp lưu trữ phân tán có thể kiểm chứng, có thể quản lý và bền vững trong kịch bản tích hợp AI và chuỗi công cộng. Phần sau đây trước tiên sẽ phá vỡ ranh giới khả năng của ba mô hình chính thống, sau đó giải thích những khó khăn đặc biệt của dữ liệu AI và cuối cùng là kiến trúc triển khai năm lớp và ngưỡng khởi chạy theo từng giai đoạn. Phán quyết chủ yếu dựa trên các tài liệu thỏa thuận chính thức và dựa trên thông tin có thể kiểm chứng càng nhiều càng tốt.
Lấy Bitroot làm ví dụ, lớp lưu trữ được định vị chính xác hơn làm cơ sở phân phối giá trị của Ngăn xếp AI. Một mặt, Bitroot cung cấp môi trường thực thi trên chuỗi hiệu suất cao thông qua EVM và Pipeline BFT song song. Mặt khác, nó kết nối dữ liệu, mô hình, sức mạnh tính toán và ứng dụng Tác nhân vào một mạng có thể giải quyết được thông qua đào tạo phân tán, mạng suy luận, thực thi đáng tin cậy và quản lý tài sản AI. Trong mạng này, bộ lưu trữ không phải là một mô-đun biệt lập mà là cơ sở hạ tầng xác định liệu dữ liệu có thể được xác thực hay không, liệu mô hình có thể được sao chép hay không, khả năng tính toán có thể được giải quyết hay không và liệu những người đóng góp có thể tiếp tục nhận được lợi ích hay không.

Cả tập trung hoàn toàn và trên chuỗi đều không còn khả thi trong các tình huống AI
Trong vài năm qua, các vấn đề về lưu trữ thường được đơn giản hóa thành hai lựa chọn: tập trung toàn bộ trên chuỗi hoặc tập trung hoàn toàn. Cả hai con đường này đều không bền vững trong kịch bản AI.
Áp suất của cuộn dây hoàn toàn rất cụ thể. Dữ liệu huấn luyện, trọng số mô hình, nhật ký suy luận và chỉ mục vectơ thường có khối lượng lớn và được cập nhật thường xuyên. Ngay cả khi chúng được cắt lát trước và sau đó được tải lên chuỗi, chúng sẽ đồng thời đạt đến mức trần thông lượng và đường cong chi phí. Quá trình tập trung hoàn toàn diễn ra nhanh chóng, nhưng nền tảng tin cậy mà trên đó khả năng xác minh, truy xuất nguồn gốc, chủ quyền dữ liệu và hợp tác giữa các chủ thể rất mong manh và không thể đứng vững khi có sự tham gia của nhiều bên và xác nhận quyền.
Thay đổi quan trọng hơn là AI thay đổi việc lưu trữ từ một hạng mục chi phí thành một yếu tố sản xuất. Ai quản lý phiên bản dữ liệu sẽ xác định ai có quyền lặp lại mô hình; liệu dữ liệu có thể được chứng minh là có sẵn hay không có ảnh hưởng trực tiếp đến mức độ ưu tiên của việc lập kế hoạch và giải quyết sức mạnh tính toán hay không; và khả năng tận dụng dữ liệu có liên quan đến việc liệu một nhóm có thể thiết lập các ưu đãi lâu dài trong hệ sinh thái hay không. Tại thời điểm này, lớp lưu trữ không còn là hệ thống hậu cần nữa mà là hệ thống phân phối giá trị.
Vì vậy, một kiến trúc lưu trữ đủ tiêu chuẩn phải trả lời cùng lúc bốn vấn đề: liệu dữ liệu có thực sự tồn tại và có sẵn liên tục hay không, liệu có thể truy tìm mối quan hệ phiên bản giữa dữ liệu và mô hình hay không, liệu có thể quản lý các quyền và lợi ích hay không và liệu hệ thống có thể duy trì sự cân bằng lâu dài giữa chi phí và hiệu suất hay không.

Điểm vào của Bitroot: chuyển dữ liệu AI từ “có thể lưu trữ” sang “có thể thanh toán”
Đây chính xác là vị trí mà Bitroot cần lấp đầy. Là chuỗi công khai Parallel EVM hiệu suất cao dành cho các kịch bản AI, câu chuyện lưu trữ của Bitroot không nên dừng lại ở “nơi đặt dữ liệu” mà phải trả lời “cách dữ liệu được chứng minh, cách gọi và cách dữ liệu tham gia chia sẻ sổ cái”. Kho dữ liệu đào tạo, trọng số mô hình, chỉ mục vectơ và nhật ký suy luận có thể nằm trong lớp lưu trữ phân tán phù hợp hơn với các đối tượng lớn, nhưng các cam kết băm, mối quan hệ phiên bản, chính sách cấp phép, bản ghi cuộc gọi và sự kiện doanh thu của chúng cần phải tạo thành bằng chứng thống nhất trên chuỗi trên Bitroot.
Từ quan điểm này, thông lượng cao và độ trễ thấp của Bitroot không chỉ phục vụ các giao dịch DeFi mà còn phục vụ các sự kiện quản trị chi tiết hơn và thường xuyên hơn trong Ngăn xếp AI: các bản cập nhật tập dữ liệu cần được cố định, các phiên bản mô hình cần phải được đăng ký, các cuộc gọi Tác nhân AI cần được giải quyết, các tranh chấp về kết quả truy xuất cần được phân xử và tính khả dụng của nút lưu trữ cần phải được thử thách và khen thưởng liên tục. Chỉ khi chuỗi cơ bản có thể xử lý những sự kiện này, tài sản dữ liệu AI sẽ không bị khóa trong cơ sở dữ liệu tập trung và chúng sẽ không trở thành hộp đen ngoài chuỗi không thể chịu trách nhiệm.

Không có mô hình nào trong ba mô hình chính thống có thể tự mình thâm nhập vào toàn bộ bối cảnh
Sự cạnh tranh về lưu trữ phân tán không bao giờ là về ai là người tiên tiến nhất mà là ai là người phù hợp nhất trong cấu trúc dữ liệu của bạn.
Điều mà mạng có địa chỉ nội dung giải quyết là liệu đây có phải là dữ liệu hay không chứ không phải ai đảm bảo rằng dữ liệu đó trực tuyến. Theo tài liệu chính thức của IPFS, CID là thông tin nhận dạng dựa trên hàm băm nội dung và không dựa vào địa chỉ vị trí: cùng một nội dung sẽ tạo ra cùng một CID trong cùng cài đặt mã hóa và giải mã. Miễn là nội dung thay đổi một byte thì CID sẽ thay đổi tương ứng. Tính năng này làm cho nó phù hợp một cách tự nhiên cho việc xác minh tính toàn vẹn, chống trùng lặp và tham chiếu giữa các hệ thống. Đó là khả năng cơ bản để xác minh cơ quan dữ liệu. Nhưng việc giải quyết nội dung không đồng nghĩa với khả năng sẵn sàng kinh tế lâu dài. CID trả lời câu hỏi về danh tính chứ không phải ai sẽ đảm bảo rằng nó luôn trực tuyến. Cạm bẫy đầu tiên mà nhiều nhóm gặp phải sau khi lên mạng là ở đây: về mặt kỹ thuật, họ đã có được CID, nhưng lại chưa nhận được các cam kết về tính khả dụng từ góc độ kinh doanh.
Mạng lưới thị trường lưu trữ sử dụng các cơ chế kinh tế để mua tính sẵn có của chiều thời gian. Theo tài liệu của Filecoin, mạng sử dụng Proof-of-Replication và Proof-of-Spacetime để thiết lập cơ chế cam kết lưu trữ và bằng chứng liên tục. PoRep đã chứng minh rằng bản sao duy nhất này thực sự đã được lưu trữ trong quá trình đóng gói ban đầu và PoSt liên tục chứng minh rằng nó tồn tại trong các chu kỳ tiếp theo. Chu kỳ chứng nhận của WindowPoSt thường được tổ chức trên cơ sở 24 giờ và sau đó được chia thành nhiều giai đoạn chứng nhận, mỗi đợt 30 phút. Nếu bên lưu trữ không gửi chứng nhận hợp lệ trong thời hạn, điều đó sẽ gây ra hình phạt thế chấp và giảm dung lượng lưu trữ. Trong hệ thống này, tính sẵn có là hạng mục đánh giá liên tục chứ không phải cam kết một lần sau khi ký hợp đồng. Mô hình hợp đồng và có thể kiểm tra này phù hợp với thị trường dữ liệu, sao lưu và lưu trữ trung hạn đến dài hạn, nhưng nó giống một kho lưu trữ dài hạn đã được chứng minh chứ không phải là một dịch vụ trực tuyến có độ trễ thấp tự nhiên. Nếu các truy vấn trực tuyến tần số cao được đẩy trực tiếp lên cao, trải nghiệm sẽ bị kéo xuống bởi độ trễ đuôi.
Mạng lưu trữ vĩnh viễn đi theo một con đường khác, trao đổi các khoản thanh toán một lần để lấy lịch sử bất biến. Theo giao thức Arweave và thông tin trong giấy vàng, một phần phí tải lên sẽ được chuyển vào quỹ quyên góp bộ nhớ để chi trả cho các ưu đãi lưu trữ dài hạn, ưu tiên tính bền vững lâu dài trong mô hình thanh toán thay vì dựa vào thói quen gia hạn tiếp theo. Nó phù hợp với các hồ sơ chống giả mạo như kho lưu trữ lịch sử, tài liệu quan trọng và tài liệu có bản quyền. Những thiếu sót cũng rất rõ ràng: tính kiên trì không tự động đồng nghĩa với khả năng đồng thời cao và độ trễ thấp. Trong thực tế, các lớp lập chỉ mục bộ đệm, cổng hoặc gần dòng vẫn phải được thêm vào để đáp ứng trải nghiệm thời gian thực ở phía người dùng.
Ngoài ba mô hình cơ bản này, còn có hai sự kết hợp phổ biến đáng cân nhắc trong kỹ thuật. Một là sự kết hợp giữa lớp sẵn có của dữ liệu và lưu trữ đối tượng, giúp cho việc phát hành và chứng nhận tính sẵn có của dữ liệu được tiêu chuẩn hóa hơn, tuy nhiên phải trả giá bằng sự cộng tác giữa các lớp phức tạp và chi phí quản lý giao diện cao. Giải pháp còn lại là cộng tác đa đám mây và biên, có độ trễ thấp và khả năng khắc phục thảm họa tốt hơn, nhưng khó đạt được quản trị chi phí và quản lý nhất quán hơn.
Cho dù bạn chọn cách nào, về mặt kỹ thuật, việc sử dụng một giao thức để xử lý hết tất cả các tình huống là không khả thi. Một phương pháp hiệu quả là kết hợp theo loại dữ liệu: tách biệt tính kiên trì, độ trễ truy xuất và tuân thủ, khớp với lớp khả năng tương ứng, sau đó sử dụng các lớp quản trị và neo trên chuỗi để sắp xếp chúng một cách thống nhất.
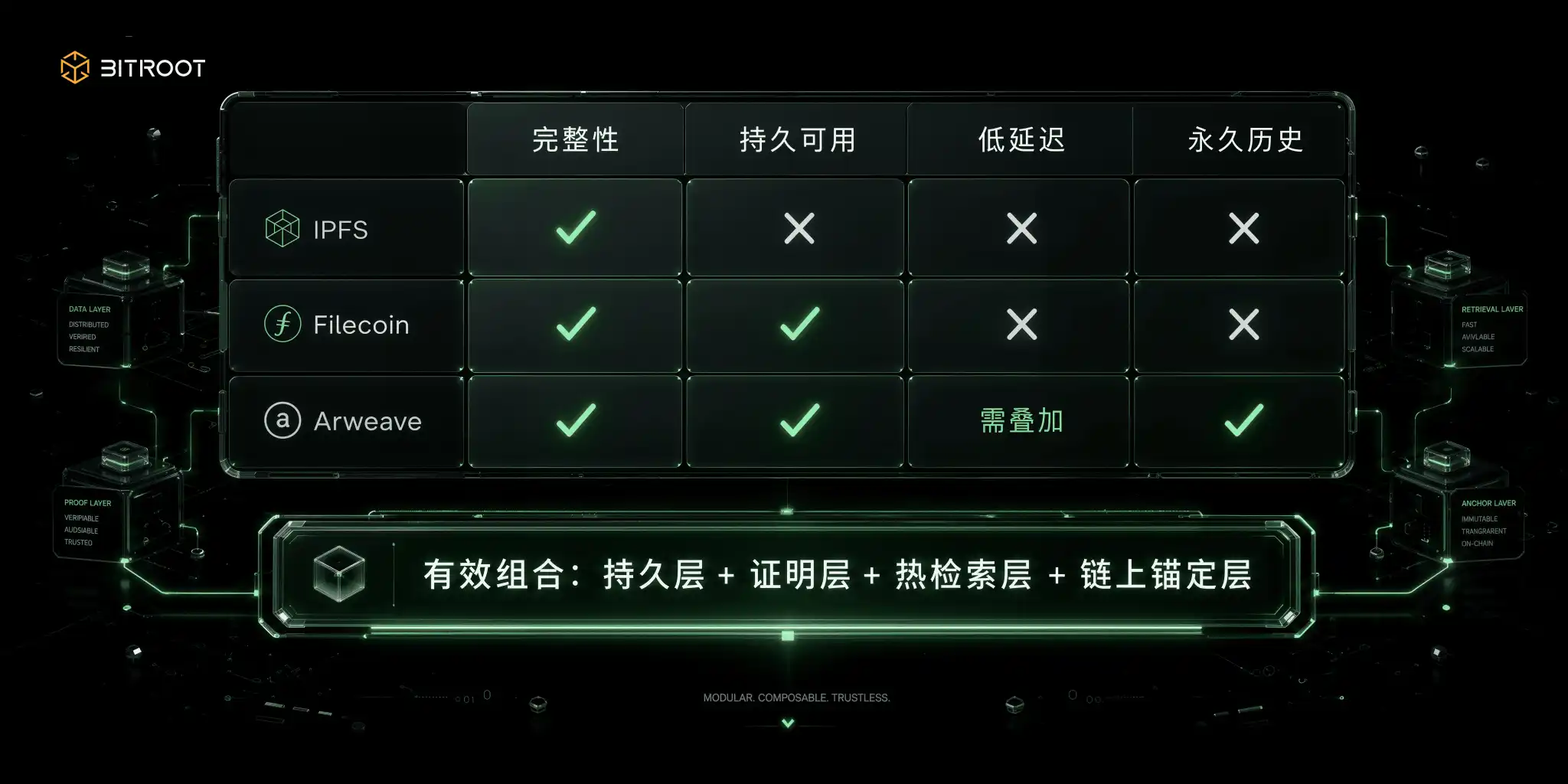
Không gian lựa chọn của Bitroot cũng phải dựa trên logic kết hợp này: thay vì thay thế IPFS, Filecoin, Arweave hoặc lưu trữ đối tượng với nhau, hãy đặt chúng vào các lớp trách nhiệm khác nhau. Địa chỉ nội dung được sử dụng để nhận dạng và toàn vẹn dữ liệu, bằng chứng lưu trữ được sử dụng để đảm bảo tính khả dụng lâu dài, lớp cố định được sử dụng cho lịch sử và thông tin xác thực chính, lớp truy xuất nóng được sử dụng cho trải nghiệm ứng dụng AI và lớp trên của chuỗi Bitroot thống nhất mang phiên bản neo, chính sách cấp phép, giải quyết cuộc gọi và xử lý tranh chấp. Nói cách khác, Bitroot không cần phải là kho lưu trữ vật lý của tất cả dữ liệu mà là sổ cái đáng tin cậy cho luồng giá trị dữ liệu AI.
Khó khăn của việc lưu trữ AI không phải là lưu trữ tệp mà là quản lý liên kết sản xuất
Trong các kịch bản AI, các đối tượng lưu trữ được chia thành ít nhất bốn loại: dữ liệu huấn luyện, trọng số mô hình, chỉ mục vectơ và nhật ký suy luận. Vòng đời, kiểu truy cập và mật độ giá trị của bốn loại đối tượng là hoàn toàn khác nhau. Quản lý chúng bằng một bộ chiến lược sẽ tránh được rắc rối trong ngắn hạn, nhưng về lâu dài, việc quản lý chắc chắn sẽ vượt khỏi tầm kiểm soát.
Vấn đề với dữ liệu huấn luyện không phải là dung lượng mà là sự trôi dạt của phiên bản. Nhiều nhóm đánh đồng các vấn đề về dữ liệu đào tạo với chi phí lưu trữ ở mức terabyte. Trên thực tế, điều khó khăn hơn là sự trôi dạt: miễn là các quy tắc làm sạch, ngưỡng sàng lọc mẫu hoặc cỡ nòng ghi nhãn thay đổi, hoạt động của mô hình sẽ thay đổi tương ứng. Nếu không có sự ràng buộc giữa phiên bản dữ liệu và phiên bản mô hình, việc đánh giá ngoại tuyến sẽ khó kiểm tra lại. Theo mô hình của MLflow và các phương pháp theo dõi dữ liệu, quá trình đào tạo ràng buộc với các phiên bản dữ liệu là điều kiện tiên quyết để tái tạo các thử nghiệm. Nguyên tắc này vẫn đúng trên chuỗi: dữ liệu gốc không nhất thiết phải nằm trên chuỗi, nhưng cam kết phiên bản, tóm tắt khóa và dấu vân tay nguồn phải được neo trên chuỗi. Khi nói đến các dự án, ít nhất phải có ba mã định danh bị ràng buộc, đó là phiên bản dữ liệu, quá trình đào tạo và phiên bản mô hình. Nếu thiếu một cái, việc truy tìm vấn đề trực tuyến sẽ chuyển từ việc kiểm tra bằng chứng sang việc đoán nguyên nhân.
Vấn đề về trọng lượng của mô hình thường không phải là liệu nó có thể được tải xuống hay không mà là ai kiểm soát ranh giới cuộc gọi. Khi một mô hình được đưa vào sản xuất, nó thường trải qua một số trạng thái: thang độ xám, hoạt động, khôi phục và ngừng hoạt động. Nếu không có hệ thống ủy quyền và đăng ký được tiêu chuẩn hóa, các cuộc gọi trực tuyến sẽ là một hộp đen không thể kiểm tra được. Sổ đăng ký mô hình trưởng thành sẽ đồng thời ghi lại dòng dõi, bí danh phiên bản, ràng buộc chữ ký và nhãn kiểm tra. Đối với các hệ thống trên chuỗi, phiên bản mô hình không chỉ là một tệp băm mà còn được gắn với các chính sách cấp phép, phân phối doanh thu và ranh giới trách nhiệm.
Khó khăn của việc lập chỉ mục vectơ tập trung ở một chỗ: tính nhất quán sau khi phân tầng nóng và lạnh. Có một mâu thuẫn cố hữu trong việc truy xuất vectơ. Độ trễ thấp và chi phí thấp mâu thuẫn với nhau: cấp nóng dựa vào bộ nhớ hoặc dịch vụ lập chỉ mục hiệu suất cao để đảm bảo phản hồi trực tuyến, trong khi cấp lạnh dựa vào lưu trữ đối tượng để giảm chi phí dài hạn. Nếu không có chiến lược đồng bộ hóa và siêu dữ liệu thống nhất, hai lớp sẽ nhanh chóng phân nhánh và cuối cùng, cùng một truy vấn sẽ trả về các kết quả ngữ nghĩa khác nhau trên các nút khác nhau. Vì vậy, hệ thống vectơ phải hỗ trợ hai điều. Quá trình xây dựng chỉ mục có thể được theo dõi và có thể xác minh phiên bản chỉ mục lớp nóng và dữ liệu chính của lớp lạnh. Đây là những gì việc truy xuất có thể kiểm chứng sau này sẽ giải quyết.
Rất khó để nhật ký suy luận có thể đồng thời duy trì quyền riêng tư, kiểm tra và tuân thủ. Nó không chỉ là tài liệu kiểm tra bảo mật mà còn là nguồn gây ra rủi ro về quyền riêng tư: việc giữ lại tất cả văn bản thuần túy sẽ mang lại rủi ro về tuân thủ, nhưng nếu không giữ lại sẽ mất khả năng xem xét sự cố. Một cách tiếp cận khả thi là xếp chồng ba lớp, lưu trữ nội dung sau khi giải mẫn cảm, cam kết băm đối với chuỗi, quyền truy cập phải được kiểm tra và cấp phép, đồng thời đạt được việc triển khai theo lớp quyền truy cập không thể giả mạo và có thể hủy bỏ.
Trong Ngăn xếp AI của Bitroot, bốn loại đối tượng này có thể tương ứng với bốn hành động quản trị: dữ liệu đào tạo để đăng ký nguồn và neo phiên bản, trọng số mô hình để đăng ký nội dung và lệnh gọi được ủy quyền, chỉ mục vectơ cho phân tầng nóng và lạnh và chứng nhận tính nhất quán cũng như nhật ký suy luận cho các cam kết kiểm tra và lưu trữ được giải mẫn cảm. Chúng không cần phải được tải lên chuỗi theo cùng một cách, nhưng tất cả chúng đều cần tạo thành một ID tài sản thống nhất, dòng phiên bản và các sự kiện gọi điện trên Bitroot. Bằng cách này, có thể hình thành một vòng khép kín kinh doanh có thể tái sử dụng giữa nội dung dữ liệu, nội dung mô hình và ứng dụng Đại lý.

Khả năng xác minh là điểm mấu chốt và bằng chứng về tính khả dụng là bước ngoặt
Cam kết lưu trữ mà không có bằng chứng về tính khả dụng về cơ bản tương đương với việc không có cam kết trong môi trường sản xuất. Để lưu trữ phân tán đi vào sản xuất, nó phải vượt qua ít nhất ba bước: chứng nhận tính toàn vẹn, chứng nhận tính sẵn sàng và khả năng kiểm tra hành vi. Khi đã vào kịch bản truy xuất AI, bước khó khăn nhất là thêm chứng nhận truy xuất.
Giải quyết nội dung được đảm bảo tính toàn vẹn cộng với Cam kết Merkle. Địa chỉ nội dung đảm bảo dấu vân tay dữ liệu ổn định và Merkle hứa hẹn khả năng xác minh cục bộ. Ý nghĩa kỹ thuật là bạn có thể sử dụng bằng chứng ở cấp độ phân đoạn để xác minh một tập hợp con của đối tượng mà không cần phải đọc toàn bộ đối tượng mỗi lần. Đối với trọng lượng mô hình lớn, kho dữ liệu lớn và dữ liệu đa phương tiện, điều này trực tiếp xác định chi phí xác minh.
Cơ chế thách thức độ tin cậy về khả năng sử dụng và xác minh lấy mẫu. Thực tiễn của Filecoin đã chỉ ra rằng tính khả dụng không phải là SLA bằng lời nói mà là một thách thức định kỳ cộng với bằng chứng trên chuỗi. Được trừu tượng hóa thành một kiến trúc chung, nó là một bộ ba phần bao gồm kiểm tra tại chỗ thụ động, kiểm tra chủ động và hình phạt lỗi: các nút phải phản ứng với các thách thức trong cửa sổ được chỉ định, nếu không hình phạt hoặc giảm trọng lượng sẽ được kích hoạt. Ý tưởng tương tự còn đi xa hơn trong lớp sẵn có của dữ liệu. Theo thiết kế lấy mẫu tính sẵn có của dữ liệu của Celestia, dữ liệu được mở rộng từ ma trận k×k sang ma trận 2k×2k. Thông qua nhiều vòng lấy mẫu ngẫu nhiên và tích lũy xác suất, các nút ánh sáng có thể xây dựng độ tin cậy có xác suất cao về tính khả dụng mà không cần tải xuống toàn bộ dữ liệu. Điều này mang lại nguồn cảm hứng có thể chuyển nhượng cho các kịch bản AI: khi đối mặt với các đối tượng rất lớn và khả năng truy cập đồng thời cao, không phải tất cả tính khả dụng đều phải được xác minh bằng cách tải xuống đầy đủ. Xác nhận thống kê thực tế hơn trong các hệ thống quy mô lớn.
Hành vi có thể được kiểm tra bằng cách neo vào chuỗi và để lại dấu vết sự kiện. Điều khó quản lý nhất trong hệ thống lưu trữ thực sự là hành vi: ai đã tải lên cái gì, ai đã thay đổi chính sách, ai đã kích hoạt di chuyển và ai gọi các mô hình nhạy cảm khi nào. Nếu những hành vi này không hội tụ thành một luồng sự việc thống nhất thì một khi nảy sinh tranh chấp sẽ quay lại lời nói mà không có bằng chứng. Điều mà lớp quản trị cần làm không phải là đưa tất cả các chi tiết vào chuỗi mà là nắm trong tay một bộ bằng chứng tối thiểu, chắc chắn và có thể kiểm chứng được khi xảy ra tranh chấp.
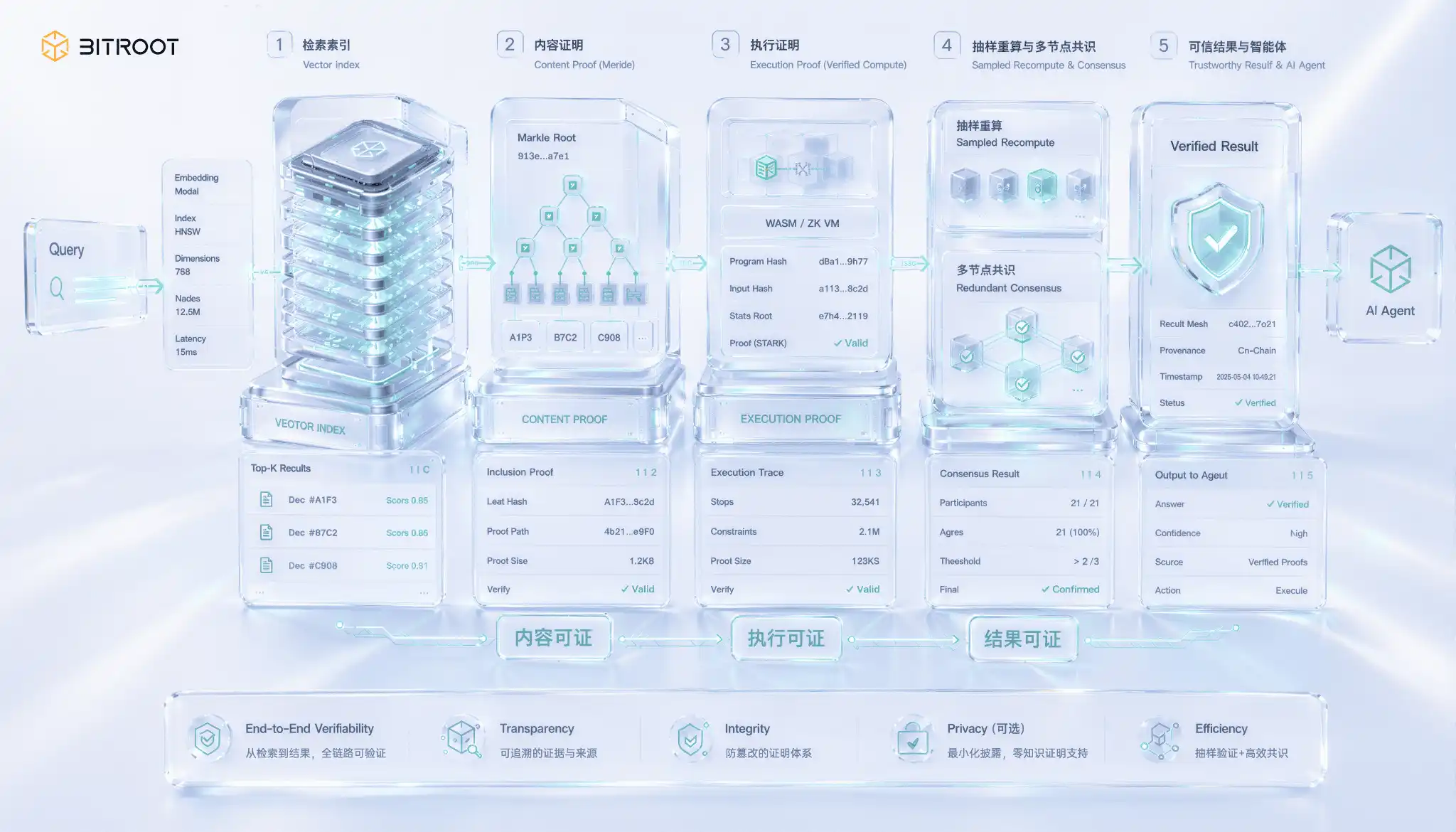
Việc lấy lại chứng chỉ là khía cạnh đặc biệt và khó khăn nhất trong các tình huống AI. Vấn đề nằm ở một lỗ hổng dễ bị bỏ qua: trả về kết quả không có nghĩa là trả về kết quả đúng. Nút truy xuất vectơ có thể lấy chỉ mục đã hết hạn hoặc thậm chí bỏ qua nút lân cận thực sự gần nhất và trả về cho bạn top-k có vẻ hợp lý, nhưng bạn không thể biết chỉ bằng cách nhìn vào giá trị trả về. Bản thân đầu ra của truy xuất ngữ nghĩa không có tính năng tự xác minh và các lỗi sẽ không được báo cáo mà chỉ âm thầm làm giảm chất lượng thu hồi và hiệu suất mô hình. Khi kết quả tìm kiếm được sử dụng để giải quyết, ủy quyền hoặc ra quyết định trên chuỗi, khoảng cách này sẽ chuyển từ vấn đề chất lượng sang vấn đề tin cậy.
Việc tách chứng chỉ truy xuất thực sự là một sự đảm bảo rằng ba lớp sẽ ngày càng trở nên khó khăn. Lớp đầu tiên là chứng nhận nội dung, chứng minh rằng vectơ trả về thực sự thuộc về phiên bản chỉ mục đã cam kết. Phương pháp này là thiết lập cấu trúc dữ liệu được chứng nhận cho chỉ mục, sử dụng cam kết Merkle để đặt gốc chỉ mục trên chuỗi và trả về kết quả kèm theo chứng chỉ đưa vào để đảm bảo rằng nút không bị giả mạo hoặc đánh cắp dữ liệu ngoài luồng. Cấp độ thứ hai là chứng nhận thực thi, chứng minh rằng truy vấn thực sự đã chạy trên phiên bản đã cam kết chứ không phải trên một chỉ mục được sửa đổi riêng tư. Điều này đòi hỏi quá trình truy vấn phải được đưa vào phạm vi tính toán có thể kiểm chứng. Lớp thứ ba là lớp khó nhất vì kết quả có thể kiểm chứng được, chứng minh rằng top-k được trả về thực sự là những lớp gần nhất theo một số liệu nhất định, thay vì thiếu các lớp lân cận gần hơn. Điều này về cơ bản cung cấp bằng chứng về tính đúng đắn của việc tìm kiếm hàng xóm gần nhất.
Việc xác minh nghiêm ngặt các kết quả đối với các láng giềng gần nhất có chiều cao gần đúng trên quy mô sản xuất vẫn là một chủ đề tiên tiến. Mặc dù các phương pháp mã hóa như bằng chứng không có kiến thức đang phát triển, nhưng chi phí chứng minh của các hoạt động vectơ chiều cao vẫn còn lâu mới có thể được sử dụng trực tuyến trên quy mô lớn. Giải pháp kỹ thuật thực dụng là thực hiện theo từng lớp thay vì một bước: trước tiên, hãy cam kết phiên bản chỉ mục và các thông số xây dựng cho chuỗi để đảm bảo khả năng truy xuất nguồn gốc; sau đó thực hiện tính toán lại mẫu của truy vấn, trích xuất truy vấn trực tuyến theo tỷ lệ với bản sao đáng tin cậy, chạy lại và so sánh kết quả, đồng thời sử dụng độ tin cậy thống kê để thay thế bằng chứng từng cái một; đồng thời, để nhiều nút độc lập tìm kiếm dư thừa và đạt được sự đồng thuận về kết quả trả về, làm tăng chi phí gian lận một điểm; chỉ khi có sự bất đồng trong việc so sánh hoặc đồng thuận, hãy nâng cấp lên tính toán lại đầy đủ và xét xử trực tuyến đối với truy vấn đang tranh chấp. Lộ trình này phù hợp với ý tưởng ưu tiên lấy mẫu xác minh bằng chứng sẵn có: trong các hệ thống quy mô lớn, xác nhận thống kê và leo thang tranh chấp thường khả thi hơn so với bằng chứng nghiêm ngặt từng cái một.
Đối với Bitroot, truy xuất có thể kiểm chứng không phải là chức năng lưu trữ biệt lập mà là một phần trong hoạt động thực thi đáng tin cậy của Tác nhân AI. Nếu Tác nhân trên chuỗi dựa vào cơ sở kiến thức bên ngoài, trọng số mô hình hoặc chỉ mục vectơ để đưa ra quyết định, thì hệ thống phải có khả năng trả lời ít nhất ba điều: nó đọc phiên bản dữ liệu nào, phiên bản mô hình nào nó gọi và liệu kết quả trả về có đến từ phiên bản chỉ mục đã đăng ký hay không. Bitroot có thể nén những bằng chứng này thành các sự kiện có thể xác minh được trên chuỗi, tiếp tục biến hành vi của Tác nhân từ “trông có vẻ thông minh” thành “có thể theo dõi, có thể tranh chấp và có thể giải quyết được”.

Vấn đề thực sự trong việc lựa chọn: không chọn giao thức mà tạo ra sự kết hợp
Nhiều đánh giá chương trình thất bại vì đặt câu hỏi sai. Công thức đúng không phải là liệu chúng ta có nên sử dụng một giao thức nhất định hay không, mà là sự kết hợp dữ liệu của chúng ta là gì, chỉ số mục tiêu của chúng ta là gì và những hạn chế của chúng ta là gì. Nên làm theo bốn hành động.
Trước tiên hãy kiểm kê tài sản dữ liệu. Ít nhất hãy phân biệt giữa dữ liệu trạng thái, dữ liệu đối tượng, dữ liệu truy xuất và dữ liệu kiểm tra, đồng thời biến mẫu kiểm kê thành các trường cố định với ít nhất tám mục: loại dữ liệu, mức tăng hàng ngày, mức đồng thời cao nhất, tỷ lệ đọc-ghi, thời gian lưu giữ, mức độ tuân thủ, độ trễ mục tiêu và giới hạn chi phí trên. Sau khi các trường được thống nhất, việc trao đổi lựa chọn giữa các nhóm sẽ nhanh hơn nhiều.
Xác định lại mục tiêu cấp độ dịch vụ. Viết lần lượt độ trễ P95/P99, thời gian khôi phục RTO, RPO điểm khôi phục, mục tiêu khả dụng và giới hạn chi phí TB đơn lẻ, nếu không sẽ không có thước đo cho tất cả các cuộc thảo luận tiếp theo.
Sau đó thiết lập sơ đồ năng lực. Các khả năng bản đồ như lưu trữ vĩnh viễn, bằng chứng sẵn có định kỳ, truy xuất có độ trễ thấp và quản lý quyền truy cập vào các lớp công nghệ khác nhau, thay vì mong đợi một lớp duy nhất có thể bao gồm tất cả.
Cuối cùng xác định ngưỡng di chuyển. Dữ liệu nào cho phép lưu trữ tập trung trong giai đoạn chuyển đổi, chỉ số nào kích hoạt quá trình di chuyển và khi nào việc thay thế phi tập trung phải được hoàn thành. Một cách tiếp cận thực tế là đặt trước các ngưỡng kép: nếu chi phí của một TB vượt quá ngân sách trong hai kỳ thống kê liên tiếp hoặc độ trễ P95 vượt quá mục tiêu trong hai tuần liên tiếp thì quá trình xem xét di chuyển kiến trúc sẽ tự động được kích hoạt. Không có ngưỡng sẽ không có quản trị và các giai đoạn chuyển tiếp sẽ trở thành trạng thái vĩnh viễn.
Kế hoạch triển khai: kiến trúc năm lớp, tích hợp khả năng lưu trữ, khả năng truy cập và khả năng quản lý vào một vòng lặp
Giá trị của kiến trúc không phải là số lượng lớp mà là liệu nó có thể tạo thành một vòng lặp khép kín có thể kiểm chứng được hay không. Dựa trên khung trước đó, giải pháp hội tụ thành năm lớp: lớp neo trên chuỗi, lớp lưu trữ đối tượng, lớp truy xuất chỉ mục, lớp chứng nhận tính khả dụng và lớp thẩm quyền chính. Mục tiêu là biến khả năng xác minh thành khả năng mặc định, hiệu suất cao thành khả năng có thể định cấu hình và quản trị thành các quy trình thực thi.
Khi đưa vào Bitroot, năm lớp này có thể được hiểu sâu hơn là mô-đun quản trị lưu trữ của Ngăn xếp AI: EVM song song cung cấp khả năng neo và giải quyết tần số cao, Pipeline BFT cung cấp độ chắc chắn có độ trễ thấp, mạng lưu trữ phân tán đảm nhận các đối tượng lớn và dữ liệu lịch sử, lớp truy xuất chỉ mục phục vụ các lệnh gọi Ứng dụng và Tác nhân AI, lớp chứng minh tính khả dụng chuyển đổi chất lượng dịch vụ nút thành độ tin cậy và phần thưởng, đồng thời lớp quyền hạn chính kết nối chủ quyền của người dùng, bảo vệ quyền riêng tư và ủy quyền thương mại hóa mô hình.
Chỉ trạng thái cần thiết tối thiểu mới được lưu trữ trong lớp neo trên chuỗi: cam kết dữ liệu, dấu vân tay phiên bản, tóm tắt chính sách quyền và sự kiện giải quyết. Các đối tượng lớn không được tải lên chuỗi. Những gì được tải lên là chứng chỉ chứng minh rằng đối tượng tồn tại và phiên bản là chính xác. Nó không chỉ duy trì khả năng xác minh trên chuỗi mà còn ngăn thông lượng bị kéo xuống bởi các tệp lớn.
Trong bối cảnh kiến trúc của Bitroot, lớp neo trên chuỗi không chỉ là nơi để "ghi lại hàm băm", mà còn là lối vào chung để đăng ký tài sản AI, quản trị quyền hạn, phân phối thu nhập và xét xử tranh chấp. Các tập dữ liệu, trọng số mô hình, chỉ mục vectơ và nhật ký suy luận đều có thể được lưu trữ ngoài chuỗi theo cách thích hợp nhất, nhưng các cam kết phiên bản, trạng thái ủy quyền, bản ghi cuộc gọi và phân bổ doanh thu của chúng cần phải chuyển sang trạng thái trên chuỗi của Bitroot. Theo cách này, bộ lưu trữ ngoài chuỗi chịu trách nhiệm mang lại khối lượng và Bitroot chịu trách nhiệm mang lại niềm tin.
Lớp lưu trữ đối tượng mang dữ liệu thực và áp dụng chiến lược kết hợp giữa mã hóa xóa và bản sao: các đối tượng truy cập tần số thấp, giá trị cao tập trung vào khả năng chịu lỗi, trong khi các đối tượng truy cập tần số cao, giá trị trung bình tập trung vào hiệu quả truy xuất. Chính sách này không phải là cấu hình tĩnh và phải được điều chỉnh linh hoạt theo mức độ phổ biến truy cập và cấp độ doanh nghiệp.
Lớp truy xuất chỉ mục kết hợp các chỉ mục siêu dữ liệu và chỉ mục vectơ vào một thư mục hợp nhất. Lớp nóng đảm nhận việc truy xuất trực tuyến và lớp lạnh đảm nhận việc lưu trữ và tái thiết. Tất cả các phiên bản chỉ mục phải đăng ký phiên bản dữ liệu nguồn và các tham số xây dựng, nếu không thì việc trôi chỉ mục sẽ không thể chịu trách nhiệm.
Lớp chứng minh tính khả dụng định lượng hành vi của nút. Tỷ lệ thành công trong việc ứng phó với các thử thách, độ trễ phản hồi và tỷ lệ sửa chữa thành công đều được tính vào điểm danh tiếng và điểm số sau đó được gắn với việc phân bổ phần thưởng để tránh việc chỉ khen thưởng năng lực chứ không phải tính khả dụng.
Lớp quyền chính kiểm soát quyền truy cập và tuân thủ. Dữ liệu có độ nhạy cảm cao sử dụng khóa phân cấp và ủy quyền theo thời gian, nhật ký suy luận sử dụng bộ lưu trữ được giải mẫn cảm và phát lại kiểm tra, đồng thời lệnh gọi mô hình sử dụng các quyền có thể thu hồi. Bản thân thao tác cấp phép cũng phải để lại dấu vết để ngăn chặn tình trạng trôi cấu hình.
Năm lớp này là một vòng khép kín ở cấp độ thực thi, không phải là đường dẫn một chiều: sau khi dữ liệu được truy cập, đầu tiên nó được cắt và mã hóa vào lớp đối tượng, sau khi ghi, một chỉ mục sẽ được tạo và neo trên chuỗi; lớp nóng được truy vấn trực tuyến và nếu không đủ lượt truy cập, nó sẽ quay trở lại lớp lạnh; khi kết quả được trả về, xác minh tính toàn vẹn và xác minh quyền được kích hoạt cùng lúc và các hành vi chính được đưa vào giải quyết và kiểm tra. Giá trị thực sự của liên kết này là bất kỳ nút nào, vào bất kỳ lúc nào, đều có thể trả lời bốn câu hỏi: dữ liệu đến từ đâu, phiên bản hiện tại là gì, ai có quyền truy cập và liệu hệ thống có thể chứng minh rằng nó có sẵn hay không.
Đây cũng là lý do chính khiến Bitroot phù hợp để thực hiện quản lý lưu trữ AI. Việc gọi Tác nhân AI, chuyển đổi phiên bản mô hình, thay đổi ủy quyền dữ liệu và tranh chấp về kết quả truy xuất không phải là các hoạt động nền có tần suất thấp mà là các sự kiện trên chuỗi sẽ tiếp tục xảy ra khi ứng dụng phát triển. Nếu chuỗi cơ bản không thể cung cấp độ trễ xác nhận đủ thấp và thông lượng đủ cao, thì việc quản lý lưu trữ cuối cùng sẽ bị buộc quay trở lại các bảng ngoài chuỗi và đối chiếu thủ công. Sự kết hợp giữa EVM song song và BFT đường ống của Bitroot, giá trị không chỉ TPS cao hơn mà còn cho phép các sự kiện quản trị tần suất cao này được cố định, giải quyết và chịu trách nhiệm trong thời gian thực.

Ai sẽ trả tiền: Hãy để tính sẵn có chứ không phải năng lực quyết định doanh thu
Để việc lưu trữ hoạt động lâu dài, các biện pháp khuyến khích phải nhắm vào tính sẵn có chứ không phải dung lượng đống. Chỉ khen thưởng dung lượng là một hình thức trá hình để khuyến khích các nút tích hợp đĩa cứng và dịch vụ nhẹ. Filecoin đã khắc phục điểm này bằng một cơ chế: nó đã đưa ra khái niệm về sức mạnh được điều chỉnh theo chất lượng, cho phép các lĩnh vực thực hiện các đơn đặt hàng lưu trữ thực, đặc biệt là các đơn hàng hợp lệ đã được xác minh, tức là đơn vị đo lường nhỏ nhất của không gian lưu trữ, đạt được trọng số cao hơn trong phép đo sức mạnh tính toán, do đó nghiêng phần thưởng về phía năng lực thực sự cung cấp dịch vụ, thay vì hướng tới dung lượng trống được đóng gói hoàn toàn. Ý tưởng này đáng để học hỏi từ bất kỳ lớp khuyến khích tự xây dựng nào.
Để biến nó thành một chức năng khen thưởng có thể thực thi được, ít nhất bốn chiều phải được tính đến cùng lúc và logic trọng số tương ứng phải được làm rõ. Dung lượng xác định phần cơ bản và trả lời bạn đã cam kết bao nhiêu dung lượng. Tốc độ trực tuyến và độ trễ phản hồi xác định hệ số chất lượng dịch vụ và trả lời liệu không gian này có thực sự được mong muốn khi cần hay không. Mặt hàng này phải có trọng lượng cao hơn, nếu không tính sẵn có sẽ trở thành khẩu hiệu. Tỷ lệ khôi phục dữ liệu thành công quyết định độ tin cậy của việc khắc phục thảm họa. Việc bản sao có thể được xây dựng lại sau khi nút ngoại tuyến hay không có liên quan trực tiếp đến sự tồn tại của dữ liệu đuôi dài. Mật độ giá trị dữ liệu xác định phần thưởng phía cầu. Hệ số nhân vi phân được đặt cho các tập dữ liệu có giá trị cao và các mô hình có nhu cầu cao, do đó dữ liệu khan hiếm và được gọi thường xuyên có thể thu được lợi nhuận cao hơn. Phần thưởng nên được trao cho dịch vụ có thể chứng minh được chứ không phải năng lực được công bố.
Chỉ khuyến khích tích cực thôi là chưa đủ. Cam kết, hình phạt và trọng tài ở phía ràng buộc phải được thực hiện cùng lúc và phải thỏa mãn sự bất bình đẳng cơ bản: lợi ích mong đợi của việc gian lận phải thấp hơn chi phí dự kiến của việc bị phạt, nếu không mọi cơ chế chứng minh sẽ bị bỏ qua bởi tính hợp lý về mặt kinh tế. Đặt cược cho phép các nút đặt cọc chi phí cho các cam kết về tính khả dụng và quy mô của cam kết phải tỷ lệ thuận với sức mạnh tính toán và giá trị dữ liệu đã hứa; in Filecoin's design, the storage party needs to pay pre-mortgage according to the promised computing power. Once offline within the proof window, a failure fee will be triggered, and if the sector is permanently abandoned, a heavier termination penalty will be triggered. The significance of this set of stepped penalties is to treat short-term disconnection and malicious exit differently. Arbitration uses on-chain evidence to drive dispute processing: when a user claims that data is unavailable and a node claims that it has served normally, challenge records, sampling certificates and event logs form a machine-readable basis for ruling, compressing disputes that originally required manual intervention into a verifiable on-chain judgment.
The AI scenario also requires a more difficult layer of governance: how to split the profits of the three parties. A model that is called repeatedly is backed by the corpus provided by data contributors, the training invested by model contributors, and the hosting undertaken by storage nodes. All three parties contribute to the final call value, but the contributions are difficult to directly observe. A feasible approach is to base value attribution on measurable on-chain events: pay-per-call calls are automatically settled, data and models are bound to each call through version fingerprints and blood relationships, and are automatically split according to a pre-coded programmable account split ratio to avoid wrangling afterwards. It is accompanied by a blacklist and forfeiture mechanism. For malicious data uploading, copyright infringement, and model theft, once determined by arbitration, the mortgage will be seized and subsequent income will be frozen. Otherwise, there will be a counter-intuitive result: the more successful the assetization is, the more disputes will arise about the division of accounts and the confirmation of rights, and it is precisely the ecological trust itself that will eventually be brought down.
Compliance is not a patch after going online, but a constraint during the architecture period: the security baseline is end-to-end encryption, hierarchical key management and periodic rotation, superimposed hash check and Merkle commitment to ensure download verifiability, and then joint disaster recovery with multiple copies and erasure coding is used to ensure fault recovery; the privacy side implements minimum permission access control based on data level, supports revocable authorization, one-time authorization and time-sensitive authorization, and leaves traces of key access and operations across the entire link to facilitate audit playback. Compliance is also the link that is most likely to be postponed and the most expensive: data localization and cross-domain transmission policies must be configurable, and deletion, access, and audit requests must have standard process interfaces; the most difficult thing is the natural conflict between non-tamperability and deletability. A feasible solution is cryptographic erasure and index invalidation: destroying the key makes the ciphertext irrecoverable, invalidating the index so that the data cannot be retrieved, and satisfying the deletion request while retaining on-chain records. There are three stage thresholds from pilot to production: first establish a minimum trusted closed loop, stabilize object storage, on-chain anchoring, integrity verification and basic monitoring, and check availability, read and write success rate, anchoring and object version consistency rate, and fault recovery can be drilled; then do AI Assetization and index governance introduce data set and model asset management, version pedigree, vector index hot and cold stratification, model authorized calls and training data source registration. For acceptance, the training is traceable, the model can be rolled back and audited, the hot layer delay meets the standards, and the impact of index reconstruction is controllable. Finally, verifiable retrieval and automated governance are introduced, and challenge proof, policy migration, and reward and punishment automation are introduced. The acceptance depends on availability proof coverage, risk treatment delay, unit cost reduction, and policy changes can be tracked and rolled back. The indicator system is a strategic system rather than a display report. If only technical items are written and business results are not written, the storage solution will collapse into a pure cost center; it is recommended to divide it into three layers: basic technical indicators (availability, P95/P99 delay, throughput, RTO/RPO, error rate) to answer whether the system is healthy, AI Special indicators (training data traceability rate, model reproducibility rate, inference verification coverage rate, index consistency) answer whether the model quality can be managed, and business result indicators (data supply growth, call cost reduction, node activity, asset transaction scale) answer whether the system creates value. There must be a mapping relationship between the three layers. The real purpose of the indicators is input for strategy tuning, not a report for display. The five most common failure points can basically be avoided in advance: only storage without version management, data does not mean available, and availability does not mean reproducibility; only looking at capacity without looking at availability proof, and rewarding based on capacity will induce heap capacity-light services; hot and cold tiering is implemented but synchronization strategy is not implemented , the index version synchronization and failure processing are not closed loop; the compliance policy is set behind, and the later the permissions, logs, desensitization, and deletion responses are, the greater the cost; the transition architecture has no exit mechanism, and centralization first and then decentralization is a reasonable path, but the lack of migration threshold will solidify the transition state and deviate from the original intention.
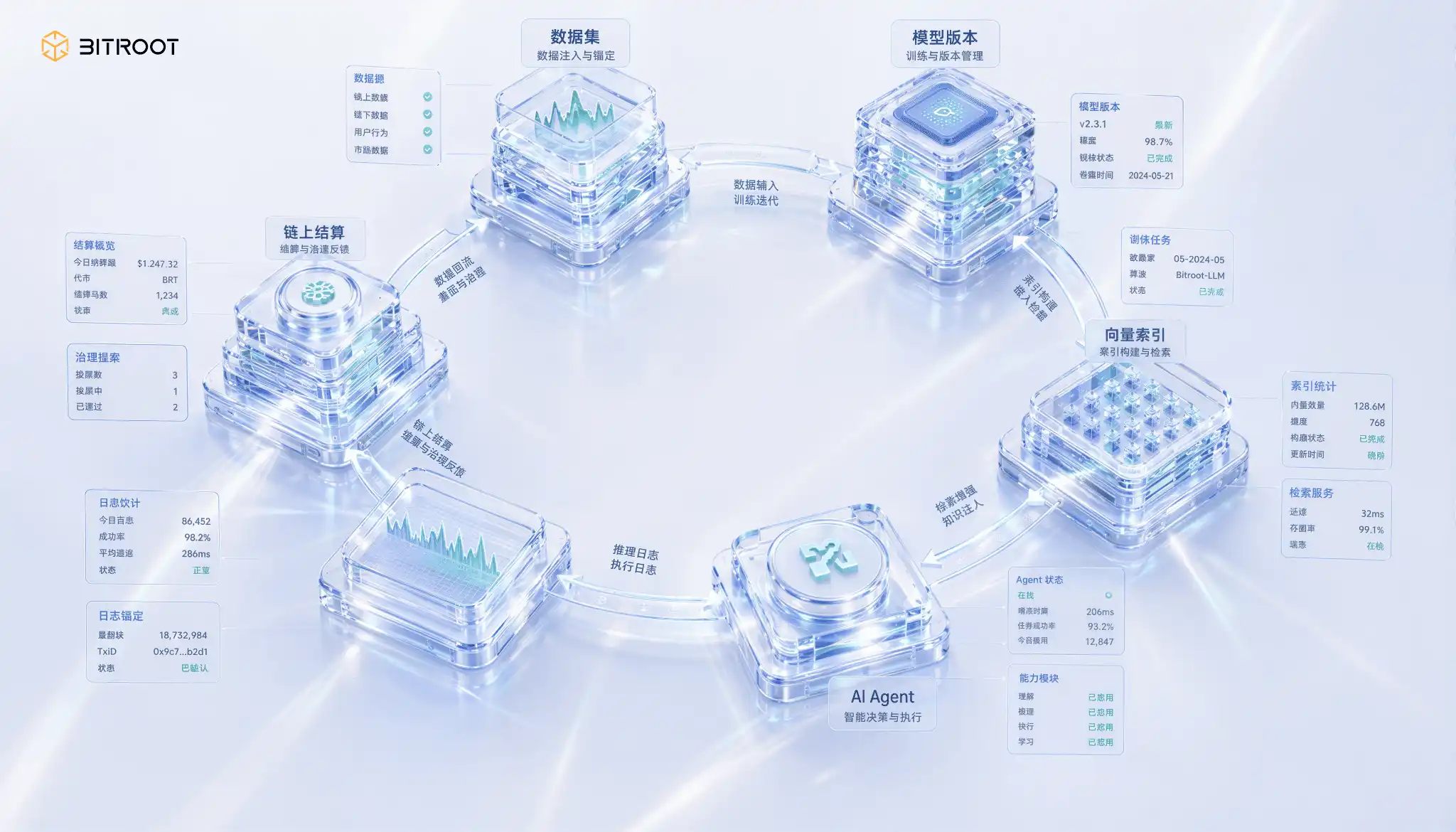
Bitroot’s complete closed loop: from data, model to AI Agent
In this closed loop, Bitroot can convert every key behavior of AI assets into settleable events: data set registration, model version release, vector index reconstruction, AI Agent invocation, inference log anchoring, permission authorization and revocation, dispute challenge and arbitration results. The chain does not need to carry all the data, but it must carry the minimum evidence of these actions. Only in this way will the value relationship between data, models, computing power and applications not remain just verbal promises, but will enter into programmable ledgers and auditable governance.
Putting this mechanism into Bitroot’s operations and ecological expansion, storage incentives should not be designed as separate hardware subsidies, but should become part of the AI Stack value stream: data contributors receive income for data being trained or called, model contributors receive income for model services, storage and retrieval nodes receive income for continuous availability and low-latency services, and verification and challenge nodes receive rewards for discovering unavailability, index drift, or permission anomalies. In this way, Bitroot's economic system rewards not "uploaded", but "continuously provable usefulness."
Storage is not a cost center, but a trust and value distribution system
What distributed storage needs to solve in the AI era is not to replace a certain object storage product, nor to pursue a decentralized narrative, but four harder things: long-term reliable proof, a governance order for cross-subject collaboration, a responsibility link between data and models, and sustainable economic incentives.
A single-protocol single-layer architecture cannot cover these goals. A more realistic path is a combined architecture: content addressing ensures integrity, storage proof ensures availability in the time dimension, the permanent layer ensures key history, the hot layer ensures online experience, and on-chain anchoring ensures governance and settlement certification. This is not a compromise, it is engineering rationality. The focus of implementation is not to have the most complete functions, but to establish the closed loop first. First, run through the minimum trusted closed loop, and then add AI assetization, verifiable retrieval and automated management layer by layer.
Condensing this method into a week of actions, there are actually only three steps: complete an eight-field data inventory table on the first day, run through the minimum link from access, storage, retrieval to verification in a real business domain on the third day, and hold a migration threshold review meeting using P95 latency and unit cost on the seventh day. By completing these three steps, the team will move from conceptual consensus to engineering consensus.
We must also acknowledge a realistic boundary: no matter which protocol combination is used, there are trade-offs between cost, delay, and durability, and there is no single answer that is optimal for all businesses at the same time. Truly sustainable solutions come from continuous iteration under clear boundaries, rather than long-term static configurations after a single decision.
What will eliminate a project in the future is often not that the TPS is not high enough, but that the data responsibility chain is unclear; in the era of AI public chains, storage is not about putting data in, but allowing data to be proven at any time.
Conclusion
The real AI public chain competition will not stop at the comparison of TPS, Gas or confirmation time in the end. Performance is the entrance, but not the end. After entering the era of AI native applications, the on-chain system must carry not only transactions, but also data versions, model calls, computing power scheduling, inference records, Agent behaviors, and multi-party income distribution.
This is also Bitroot’s judgment on the storage layer: storage is not an accessory module, but the layer closest to the source of value in the AI Stack.数据能不能被证明,模型能不能被复现,调用能不能被审计,收益能不能被自动分配,决定了一个去中心化 AI 网络是否真正具备长期生命力。
Bitroot 要构建的,不是一条只追求更快执行的链,而是一套让 AI 资产能够被确认、被调用、被结算、被治理的基础设施。 Parallel EVM 和 Pipeline BFT 解决的是高频链上事件的承载能力,分布式存储与可验证机制解决的是 AI 数据和模型的信任基础,而可编程分账与链上治理,则把贡献转化为持续的经济激励。
当 AI Agent 开始代表用户行动,当模型和数据开始成为可流通资产,当算力、存储和推理服务进入同一个价值网络,存储就不再是「把文件放在哪里」的问题。
它会成为 AI 公链的信任底座,也会成为下一代智能网络的价值分配系统。
在 Bitroot 看来,未来真正重要的不是谁拥有最多数据,而是谁能让数据在任何时刻都可证明、可调用、可追责,并最终参与价值结算。
关于 Bitroot
Bitroot 是一个聚焦并行执行与 AI 原生架构的 Layer 1 公链项目。 Bitroot 采用 EVM 兼容技术路线,并通过并行执行机制、共识优化和 AI 相关接口设计,探索为 AI Agent、DeFi 及 Web3 应用提供高性能、低成本的链上执行环境。
本文来自投稿,不代表BlcokBeats观点。
