
해결하기 쉬운에서 : Bitroot가 AI 데이터 값 레이어를 재구성하는 방법
Bitroot, 한 손으로, EVM의 병렬화를 통해 성능 체인과 함께 고성능 환경을 제공 파이프 BFT, 그리고, 다른 한편으로는 데이터, 모델, 알고리즘 및 에이전트 애플리케이션을 분산 교육, 네트워킹, 신뢰할 수있는 시행 및 AI 자산 관리. 이 네트워크에서 스토리지는 고립 된 모듈이 아니지만 데이터가 정확하다고 결정하는 인프라는 모델이 재연할 수 있는지 여부를 결정합니다. calculus가 폐쇄되고 기여자가 이익을 유지할 수 있는지 여부。

출처: Bitroot
저장은 비용 센터가 아닙니다, 그것은 Bitroot AI 더미의 가치 분배 체계입니다
많은 팀은 저장 층이 1 년 상반기에 더 신중하게 선택되어야한다는 것을 깨달았습니다. 데이터가 손실되지 않았고 서비스가 멈추지 않았습니다. 그러나 문제는 다른 방법으로 등장했습니다. 아카이브의 교육 데이터는 천천히 회복되고, 핫스팟 벡터 검색의 꼬리는 밀리 초에서 초로 흔들리고 아무도 교육 데이터의 버전이 재생 될 때 사용되었는지 알려 줄 수 없습니다. 이 시점에서 더 이상 확장이 아니지만 3 가지 어려운 질문 : 데이터가 항상 사용할 수 있다는 것을 입증 할 수있는 사람은 버전과 장기 비용을 지불하는 사람。
중앙 클라우드에서 네트워크로 이동하는 파일로 스토리지를 이해하면 NFT 메타데이터 시대에 올라갑니다. 작업이 AI 교육 언어, 모델 무게 및 벡터 인덱스로 확장되면이 접근법은 신속하게 실패합니다。
팀의 대부분은 지금까지 저장을 고려하고있다. 최고의 물류 비용, 이는 정확 하 게 가장 UNDERVALUED 및 선택하는 가장 쉬운 장소: AI 체인에서, 그것은 실제로 데이터와 누가 진행을 얻을 결정 하는 가치 배포 층. 이 문서는 하나의 질문 만 답변 : 공공 체인과 AI 통합의 컨텍스트에서 검증 가능한 관리 및 지속 가능한 분산 스토리지 프로그램을 구축하는 방법. 3개의 지배적인 패러다임의 기능 경계는 아래에 부서지고, AI 자료의 특정한 어려움은 설명되고, 마지막으로 5 층 건축술과 입장을 위한 단계적인 문턱. 판단은 공식적인 프로토콜 문서에 주로 근거하고, 가능한 범위에, VERIFIABLE 정보。
Bitroot의 경우, 저장의 더 정확한 위치는 AI 스택의 값 분포베이스입니다. Bitroot, 한 손으로, EVM의 병렬화를 통해 성능 체인과 함께 고성능 환경을 제공 파이프 BFT, 그리고, 다른 한편으로는 데이터, 모델, 알고리즘 및 에이전트 애플리케이션을 분산 교육, 네트워킹, 신뢰할 수있는 시행 및 AI 자산 관리. 이 네트워크에서 스토리지는 고립 된 모듈이 아니지만 데이터가 정확하다고 결정하는 인프라는 모델이 재연할 수 있는지 여부를 결정합니다. calculus가 폐쇄되고 기여자가 이익을 유지할 수 있는지 여부。

그것은 모든 CHAINED 올라와 CENTERED. AI에서 작동하지 않습니다
지난 몇 년 동안 스토리지 문제는 종종 하나 또는 다른 사람으로 감소했습니다. 전체 체인 또는 중앙화. 두 도로는 AI 장면에서 UNSUSTAINABLE 입니다。
가득 차있는 사슬 압력은 특정합니다. 교육 자료, 모델 무게, 이유 로그, 벡터 인덱스는 일반적으로 높은 볼륨 및 고주파 업데이트이며, 그들은 슬라이딩 및 chained 경우에도, 그들은 보드 천장과 비용 곡선 모두 충돌. 전체 중심화는 빠른 실행하지만, 검증, 추적성, 데이터 주권 및 크로스 서브젝트 협업에 대한 신뢰 기반은 fragile이며 여러 계정이 분할되고 권한이 포함됩니다。
더 중요하게, AI는 생산 인자에 비용 품목에서 저장을 바꿨습니다. 데이터 버전의 관리는 이식 모델에 대한 이니셔티브를 취하는 것을 결정합니다. 데이터가 사용할 수 있음을 입증하고 컴퓨팅 및 정리의 우선 순위에 직접적인 영향을 미칠 수 있는지 여부를 입증 할 수 있습니다. 그리고 AUTOMATE 데이터는 팀이 장기적인 생태적 인 인센티브를 만들 수 있는지 여부의 문제입니다. 더 이상 물류 시스템이지만 가치 분배 시스템。
그래서 자격이 된 저장 구조는 한 번에 4개의 질문에 대답해야 합니다: 데이터가 실제적이고 바람직하다는 점은, 데이터가 모델의 버전에 추적 할 수 있는지 여부, competencies 및 혜택이 관리 할 수 있는지 여부, 그리고 시스템 잔액 비용과 성능이 한 번에。

Bitroot 항목 포인트 : AI 데이터를 "storable"에서 "liquidable"로 이동
Bitroot가 채워질 필요가 있는 곳입니다. AI 장면에 대한 고성능 Parrallel EVM 공개 링크로서 Bitroot의 저장 narrative는 "데이터가 배치되는 곳"을 멈추지 않아서 "데이터가 입증 된 방법, 그들이 호출하는 방법, 어떻게 분할에 참여합니다." 교육 자료, 모델 무게, 벡터 인덱스 및 소싱 로그는 더 큰 개체에 적합 한 배포 스토리지 레이어에서 왼쪽 될 수 있습니다, 하지만 그들의 Hashi 약속, 버전 관계, 권한 전략, 통화 기록 및 수익 이벤트 비트 루트에 통합 된 체인 증거。
이 관점에서 Bitroot의 높은 입력 및 낮은 deliberate 이벤트는 DeFi 거래뿐만 아니라 AI 스택에서 더 많은 수치 및 고주파 지배 이벤트를 제공합니다. 데이터 세트의 업데이트는 앵커됩니다, 모델 버전은 등록 될 것입니다, AI 에이전트 통화는 정착 될 것입니다, 검색 결과는 중재되고 저장 노드 가용성은 지속적으로 도전하고 보상 될 것입니다. 아래 체인이 이러한 이벤트를 통해 수행 할 수 있다면 AI 데이터 자산이 중앙 데이터베이스에 고정되지 않거나 체인 아래의 비할 수없는 블랙 박스로 전환됩니다。

세 지배적 인 패러다임,무엇을 관통할 수 있는 장면 혼자
분산 스토리지의 경쟁은 가장 진보 된 것은 아니지만 데이터 구조에 가장 적합합니다。
콘텐츠 검색 네트워크는 데이터가 아닌지 여부를 해결하고 아무도 온라인을 보장합니다. IPFS 공식 문서에 따르면, CID는 내용의 HASHI ID에 근거하고 위치에 의존하지 않습니다: 동일한 내용은 동일한 코덱 설정의 밑에 동일한 CID를 생성하고, CID는 내용 변화 바이트로 긴 변화합니다. 이 기능은 완전 검증, 무게 및 크로스 시스템 참조를 위해 자연적으로 만들어졌으며 데이터 검증을위한 하단 용량입니다. 그러나 콘텐츠의 위치는 경제적으로 지속 가능한 것으로 간주되지 않으며 CID 답변 정체 질문에 대한 답변은 라인에 남아있는 것을 보장하지 않습니다. 첫 번째 PIT 그 많은 팀 단계는 여기: 기술적으로, CID, 및 운영, 유용성에 대한 약속。
시장 네트워크의 저장은 경제적인 기계장치의 사용 시간 차원의 가용성을 사는 입니다. Filecoin 문서에 따르면 네트워크는 Proof-of-Replication 및 Proof-of-Spacetime을 통해 스토리지 약속과 연속 인증을 위한 메커니즘을 만듭니다. PoRep는이 독특한 복사본이 초기 봉투에서 사실이었고 PoSt는 반복적으로 후속 사이클에 있었다는 것을 증명했습니다. WindowsPost는 보통 24 시간 기초에 증명서 주기를, 다수 30 분 증거 창으로 절단하고, 저장소가 창에 있는 유효한 증거를 제출하지 않는 경우에, 저장 수용량에 있는 collateral forfeiture 그리고 감소 방아쇠를 답니다. 이 체계에서는, usability는 계약 후에 1 떨어져 투입 아닙니다 지속적인 시험입니다. 이 계약, 감사 모델은 중간 및 장기 보관, 백업 및 데이터 시장에 적합하지만, 맞춤 지연의 압력과 경험에서 직접 고주파 온라인 쿼리를 넣어 천연 저 지연 온라인 서비스보다 입증 된 장기 창고와 같은 더 많은 것입니다。
영구 저장 네트워크는 또 다른 경로, 역사에 대한 원오프 지불. Arweave 계약 및 Yellow Book 정보에 따르면, 업로드 비용의 일부는 장기 스토리지 인센티브를 커버하기 위해 저장 endowment 풀로 이동하고 후속 오염 관행에 의존하지 않는 빌링 모델의 장기 지속 가능성. 역사 아카이브, 키 문서, 저작권 자료 및 비 이동식 레코드에 적합 합니다. Shortboards는 또한 명확합니다: permanency는 높고 낮은 지연에 자동적으로 총계를 하지 않으며, 실제로는 아직도 사용자의 측에 순간 경험을 만족시키기 위하여 캐시, 출입구 또는 가까운 선 색인 층을 접히는 필요 아직도 있습니다。
이러한 세 가지 기본 패러다임 외에도 엔지니어링의 두 가지 공통 조합은 무게가 있습니다. 하나의 데이터 가용성 레이어 플러스 객체 저장의 혼합물, 그리고 더 표준화 된 데이터 분산 및 크로스 합성 및 복잡한 인터페이스 관리 비용의 가용성의 증거. 다른 사람은 구름 플러스 synergetic, 낮은 지연 및 더 나은 재해 포용력입니다, 그러나 비용 관리 및 일관성 관리는 도달하게 더 어렵습니다。
어느 방법, 모든 장면을 먹는 계약은 작동하지 않습니다. 효과적인 방법은 데이터 유형에 의해 그룹화되기 위한 것입니다: persistence, retrieval 시간 및 수락을 제거하기 위하여는, 기능 층을 따로따로 일치하고, 사슬 닻을 달고 지배적인 층에 의해 획일한 방법으로 조직될 것입니다。
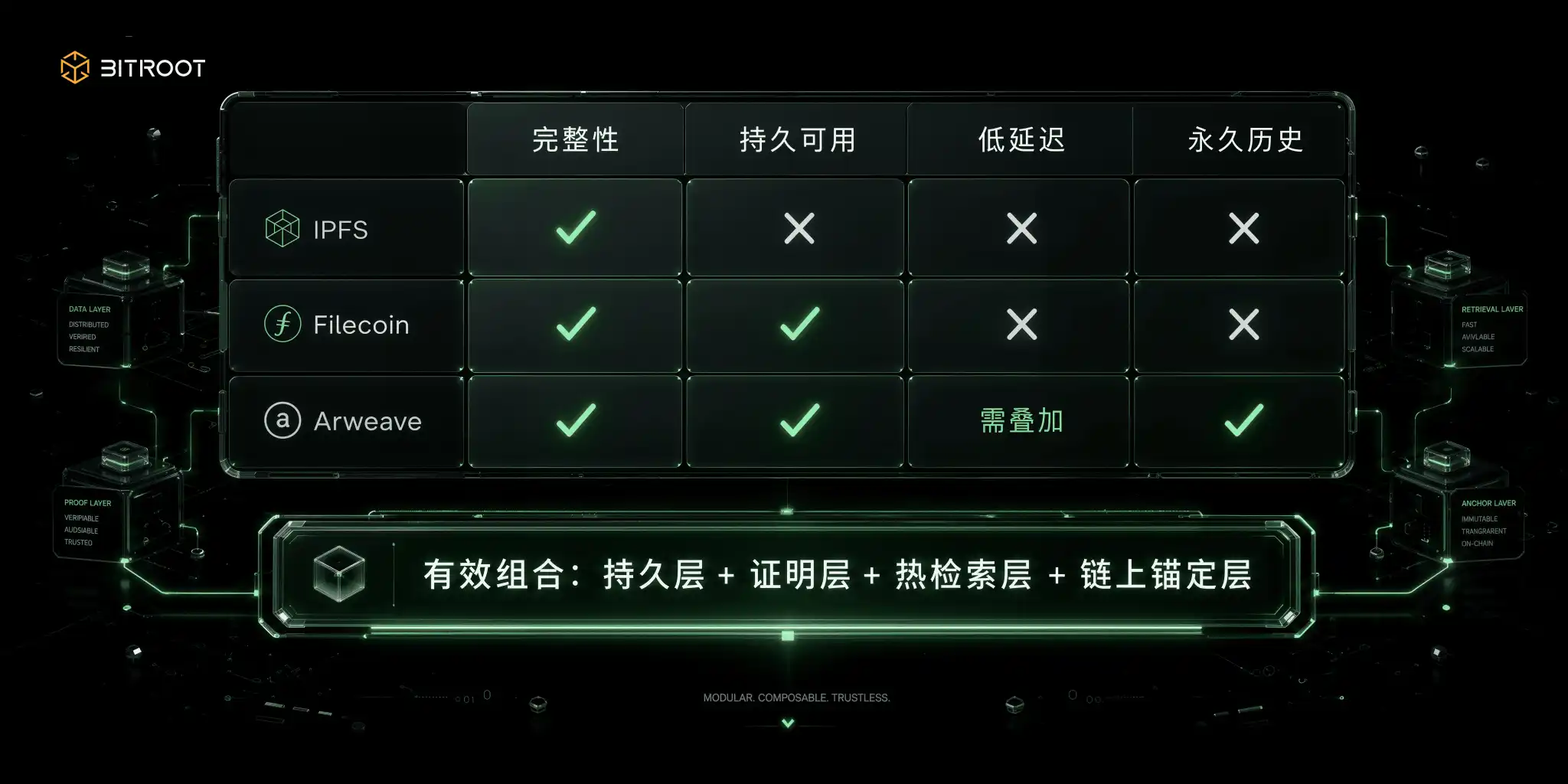
Bitroot '공간의 선택은 IPFS, Filecoin, Arweave 또는 물체와 서로 교체하는 것보다이 조합 논리에 따라야 합니다. 콘텐츠 주소는 데이터 정체성 및 무결성에 사용됩니다, 저장 인증서는 장기적인 가용성을 위해 사용됩니다, 영구 층은 중요한 역사 및 문서, 열 수색 층은 AI 신청 경험을 위해 사용되고, 위 Bitroot 사슬은 획일한 나르는 버전 닻, 권위 정책, 외침 및 분쟁 해결을 위해 이용됩니다. 즉, Bitroot는 모든 데이터의 물리적 저장소가 될 필요가 없습니다. 그러나 AI 데이터 흐름의 신뢰할 수있는 계정。
AI 저장 어려움, 파일이 아니라, 생산 링크를 실행
AI 설정에서 저장 개체는 적어도 4 가지 범주로 나뉩니다. 교육 데이터, 모델 무게, 벡터 인덱스, 이유 로그. 생명주기, 접근 모드 및 4 개의 범주의 가치 밀도는 완전히 다르며, 관리, 단기 저축 및 제어 가능한 거버넌스의 장기적인 기간에 대한 전략 세트와。
교육 데이터와 문제는 용량과 버전의 편향이 아닙니다. TB-grade 스토리지 비용으로 많은 팀 equate 교육 데이터 문제, 그리고 더 많은 문제 해결: 청소 규칙, 샘플 선택 임계값 또는 교정 변경, 모델 행동 변경, 및 바인딩 데이터 및 모델 버전 없이, 오프라인 평가는 확인 어렵습니다. MLFlow의 s 모델 및 데이터 추적 연습에 따르면, 훈련 작업 및 데이터 버전 바인딩은 실험의 복제를위한 필수품입니다. 이 원리는 사슬에 유효합니다: 본래 자료는 가득 차있에서 chained 필요, 그러나 방출 투입, 열쇠 summaries 및 근원 지문은 chained이어야 합니다. 적어도 3명의 감적자는 프로젝트, 자료 버전, 훈련 가동, 모형 버전 및, 1개 없이, 선에 문제는 추측하는 증거에서 degenerate 할 것입니다。
모델 무게의 문제는 종종 다운로드 할 수 있는지 여부,하지만 누가 경계를 호출합니다. 모델은 일반적으로 그레이 스케일, 기본 사용, 롤백 및 분해의 몇 가지 상태를 통해 이동, 등록 및 승인의 표준화 된 시스템없이, 및 온라인 통화는 unauditable 검은 상자입니다. 성숙한 모델 등록 센터 기록 혈액, 버전 별명으로, 서명 제약 및 감사 라벨. 사슬 체계를 위해, 모형 버전은 다만 문서, hashi이어야 합니다, 그러나 권위 전략과 함께 연결되어야 합니다, 진행과 책임 경계의 배급。
벡터 색인의 어려움은 1개의 장소에서 집중됩니다: 열과 찬 층 후에 견실함. 벡터 검색, 낮은 지연 및 저비용과 다른 모든 싸움 사이의 무장 금전이 있습니다. Thermosphere는 메모리 또는 고성능 인덱스 서비스에 의존하여 온라인 응답을 보장하고 콜드 레이어는 장기 비용을 포함하기 위해 객체 저장소에 의존합니다. 통합 된 메타 데이터 및 동기화 된 전략이없는 두 레이어는 빠르게 분할되고 다른 노드에서 semantic 결과를 반환 같은 쿼리의 문제입니다. 그래서 벡터 시스템은 두 가지를 지원해야, 인덱스 구성 프로세스 추적 할 수 있고 열구 지수 버전은 콜드 마스터 데이터로 재구성 할 수 있습니다, 정확히 어떤 측면 텍스트가 검색을 검증 할 수 있는지。
개인 정보 보호, 감사 및 준수가 설치되는 이유를 설정하는 것은 어렵습니다. 그것은 보안 감사 자료와 개인 정보 보호 위험의 소스입니다 : 전체 및 명시 적 유지는 준수 위험을 감안하고 사고 회전 능력의 완전하고 손실. 가능한 접근법은 Superstition, dissensitized content storage, Hashi 's promise to go up chain and access is subject to Audit authorization to achieve non-removable and revocable hierarchies。
Bitroot의 AI 스택에서, 이 4 개의 범주는 네 가지 유형의 지배 행동에 대응 할 수 있습니다 : 앵커 및 소스 등록을위한 교육 데이터, 자산 등록 및 허가에 대한 모델 무게, 열 및 냉간화 및 일관성에 대한 벡터 색인, 불명한 저장 및 감사의 약속에 대한 기록. 그들은 같은 방법으로 체인질 할 필요가 없습니다, 그러나 그들은 Bitroot에 통합 된 자산 ID, 버전 스펙트럼 및 통화 이벤트를 형성해야합니다. 데이터 자산, 모델 자산 및 에이전트 애플리케이션 사이의 재사용 가능한 상업 폐쇄 원형을 형성 할 수 있습니다。

그러나 그것은 밑바닥 선입니다. 그것은 밑바닥 선입니다
신뢰성의 증거 없이 저장 투입은 생산 환경에 있는 투입과 근본적으로 동등합니다. 유통 저장은 적어도 세 가지 방법에서 생산을 포함한다 : 무결성, 유용성, 행위, 감사성, 그리고, 한 번 AI 검색 장면은 장소에, 함께 검색하는 더 어렵다。
Completeness는 콘텐츠 위치와 Merkle 약속에 의해 입증됩니다. 콘텐츠 위치는 데이터 지문이 안정적이며 Merkle은 부분적으로 검증 될 것을 약속합니다. 프로젝트의 점은 전체에서 읽을 필요없이 분수의 개체의 하위 세트를 증명할 수 있다는 것입니다. 큰 모형 무게를 위해, 큰 언어 및 멀티미디어 자료는, 이 직접 유효성의 비용을 결정합니다。
Availability는 도전 메커니즘과 샘플 검증에 의해 입증됩니다. Filecoin 연습은 usability가 oral SLA가 아니라 추상적 인 구조가 수동적 인 스폿 검사, 활성 검사 및 실패 처벌 세트 인 정기적 인 과제의 체인에 대한 증거가 있음을 보여주었습니다. 노드는 처방된 창에서 도전에 응답해야합니다. 그렇지 않으면 벌금이 트리거되거나 무게가 감소됩니다. 같은 생각은 데이터 가용성 측면에서 더 간다. Celesti의 데이터 가용성 샘플 디자인에 따르면, 데이터는 kxk에서 2kx2k matrix로 확장되며, 여러 휠 임의 샘플링과 확률을 통해 축적된 조명 노드와 함께 전체 데이터를 다운로드하지 않고 유용성을 높일 수 있습니다. 이것은 AI 시나리오에 대한 영감입니다. 모든 가용성은 다운로드하여 완전히 검증되어야하며 통계 확인은 큰 시스템에서 더 현실적입니다。
행동은 체인 닻 및 사건 표에 지배되었습니다. 스토리지 시스템에 대한 가장 어려운 것은 행동입니다. 누가 전략을 변경, 누가 민감한 모델을 사용하는 마이그레이션을 트리거. 이 행위는 이벤트의 단일 스트림에 통합되지 않는 경우, 그들은 분쟁이 있는 지점으로 되돌릴 것입니다. 체인의 모든 세부 사항을 배치하는 것보다 거버넌스는 분쟁의 시간에 가장 작고 확실한 징수 및 검증 가능한 징수를 보유합니다。
검색 인증서는 AI 장면의 독특하고 가장 어려운 하나이며, 쉽게 무시한 격차에 문제가 발생합니다. 결과 반환은 올바른 결과를 반환과 동일하지 않습니다. 벡터 검색 노드는 최신 인덱스를 복용하거나, 심지어 실제 가장 가까운 이웃을 건너 뛸 수 있으며, 겉보기에 알맞은 top-k 중 하나로 돌아가고, 혼자 반환의 값을 볼 수 없습니다. Semanticly retrieved 산출은 자체에서 각자 입증되지 않으며, 과실은 보고되지 않습니다, 그러나 단지 조용히 뒤 질 및 모형 성과를 가지고 갑니다. 결과가 결산, 허가 또는 체인 결정에 사용될 때, 이 간격은 질에서 신뢰까지 escalates。
검색할 수 있는 Dismantling은 사실, 변화의 3 계층 보증입니다. 첫 번째 수준은 반환의 벡터가 인덱스의 약속 된 버전에 속한다는 증거입니다, 인덱스의 데이터 구조를 설정함으로써, 자신의 루트에 인덱스를 chaining하고 캡슐화 인증서로 결과를 반환하는 것은 노드가 데이터로 제작되거나 탬퍼되지 않도록. 두 번째 계층은 쿼리가 실제로 약속 된 버전에서 실행 한 인증서의 실행이었다, 오히려 개인적으로 수정 된 인덱스에, 이는 쿼리 프로세스가 verifiable 계산에 포함되어야. 세 번째 수준은 입증하기가 어렵습니다. 결과적으로, 반환된 top-k는 가장 최근 가장 최근 가장 가까운 이웃의 누락보다 가장 최근의 neighbour 검색의 번영에 필수적으로 증명됩니다。
가장 가까운 neighbour에 높은 차원 근접의 관점에서 생산의 규모에 대한 엄격한 결과는 여전히 문제의 최전선에 있으며, 지식의 제로 증거와 같은 암호는 발전하고 있으며, 높은 차원 벡터 컴퓨팅의 비용은 대규모 온라인 사용으로 입증되었습니다. 이 웹 사이트는 귀하가 웹 사이트를 탐색하는 동안 귀하의 경험을 향상시키기 위해 쿠키를 사용합니다. 이 쿠키들 중에서 필요에 따라 분류 된 쿠키는 웹 사이트의 기본적인 기능을 수행하는 데 필수적이므로 브라우저에 저장됩니다. 또한이 웹 사이트의 사용 방식을 분석하고 이해하는 데 도움이되는 제 3 자 쿠키를 사용합니다. 이 쿠키는 귀하의 동의하에 만 브라우저에 저장됩니다. 이러한 쿠키 중 일부를 선택 해제하면 검색 환경에 영향을 미칠 수 있습니다. 이러한 쿠키 중 일부를 선택 해제하면 검색 환경에 영향을 미칠 수 있습니다. 선은 책임의 증명서에 있는 표본을 우선적으로 하기의 아이디어로 손이 갑니다: 대규모 체계에서, 통계 확인 및 분쟁의 에스컬레이션은 기사에 의해 엄격히 입증된 보다는 더 읽을 수 있는 경향이 있습니다。
Bitroot의 경우, 검증 가능한 검색은 격리 된 저장 기능이 아니지만 신뢰할 수있는 AIAgent 실행의 일부입니다. 외부 지식베이스, 모델 무게 또는 벡터 인덱스에 의존하는 경우, 시스템은 적어도 세 가지를 응답해야: 그것은 데이터의 버전을 읽고, 모델의 버전을 호출하고 등록 된 인덱스 버전에서 결과를 반환. Bitroot는 verifiable 사건의 사슬에 이 증거를 압축할 수 있고, 대리인이 "retroactive, controversial, 해결"에 "똑똑한 전망"에서 이동하는 것을 허용하。

선택을 가진 진짜 문제: 선택이 아닙니다, 그러나 그룹화
많은 프로그램 리뷰는 문제가 잘못되었기 때문에 실패했습니다. 올바른 정립은 우리가 합의를 사용하려는 여부, 그러나 우리의 데이터 믹스가 무엇인지, 대상 지표가 무엇인지, 그리고 제약이 무엇인지. 4개의 움직임이 이어지는 것이 좋습니다。
데이터 자산은 먼저 계산합니다. 상태 데이터, 객체 데이터, 검색 데이터, 감사 데이터와 재고 템플릿을 최소 8개: 데이터 유형, 증가 볼륨, 피크 결합된 배포, 읽기 및 쓰기 비율, 유지 주기, 준수 수준, 목표 시간 연장, 비용 캡과 같은 고정 필드를 만듭니다. 필드가 통합되면 Cross-team 선택 통신이 훨씬 빠릅니다。
서비스 수준 목표의 REDEFINITION. P95 / P99 시간 확장, 복구 시간 RRO, 복구 포인트 RPO, 가용성 대상, 단일 TB 비용 캡은 다이로 작성, 그렇지 않으면 모든 후속 토론에 대한 통치자가 없습니다。
그런 다음 기능 맵을 만듭니다. 영원한 저장의 종류, 사용 가능성의 주기적인 증거, retrieval에 있는 낮은 지연 및 지배에 접근은 단 하나 층 보다는 기술의 다른 층에 보입니다。
마이그레이션 임계값을 정의합니다. 어떤 데이터는 전환의 중앙화, 어떤 지표 트리거 마이그레이션, 및 탈중앙화 교체가 완료되어야합니다. 한 가지 실용적인 접근법은 이중 임계값을 설정하는 것입니다. 단일 TB는 두 개의 연속 통계 주기 또는 P95, 두 개의 연속 주 오버 타트, 자동으로 구조 마이그레이션 리뷰를 트리거. 임계 값없이 거버넌스가 없으며 전환 기간은 영구적입니다。
착륙 프로그램 : 생활, 바람직하고 관리 가능한 폐쇄와 다섯 계층 구조
건축의 가치는 규모의 순서, 그러나 verifiable 반복의 모양에서 아닙니다. 이전 프레임 워크에 따라, 프로그램은 5 층으로 집광됩니다 : 체인 앵커 층, 객체 저장 층, 색인 검색 층, 서비스성 인증서 층, 키 액세스 층. 목적은 기본 용량으로 검증할 수 있으며, 구성으로 고성능 및 실행 가능한 프로세스로 관리됩니다。
Bitroot에서, 이 5개의 층은 AI 더미 저장 주관 단위로 더 이해될 수 있습니다: 평행한 EVM는 고주파 닻을 제공하고 명확한 기능을, 파이프라인 BFT는 큰 목표 및 역사 자료에 낮은 지연된 특정, 배부된 저장 네트워크를, 색인 수색 층 서비스 AI 대리인 및 신청 외침, 가용성 증명서 층은 신용과 보상으로 노드 서비스 질을 번역하고, 중요한 접근 층 연결 사용자 soignverety, 개인 정보 보호 및 모형 상업화 허가를 번역합니다。
체인 앵커는 가장 작은 상태에 보관됩니다 : 데이터 약속, 버전 지문, 권한 전략 요약, 결제 이벤트. 큰 객체는 존재와 올바른 버전을 증명하기 위해 chained되지 않습니다. 그것은 체인의 확률을 보존하고 큰 문서에 의해 끌 수 stale을 허용하지 않습니다。
Bitroot의 프레임 워크에서 체인 앵커는 "Hashi의 기록"뿐만 아니라 AI 자산 등록, 권위 지배, 절차 및 분쟁 결정의 배포를위한 일반적인 항목 포인트입니다. 데이터 세트, 모델 무게, 벡터 인덱스 및 소싱 로그는 가장 적합한 방식으로 체인 아래에 저장 될 수 있지만, 그들의 버전 약속, 허가 된 상태, 통화 기록 및 Bitroot 체인에 입력해야합니다. 따라서, 사슬 저장은 짐을 나르기를 책임지고, Bitroot는 신뢰를 나르기를 책임집니다。
오브젝트 저장 층은 디코더링 및 복사의 혼합 전략을 사용하여 실제 데이터를 운반합니다. 고가치, 저주파 접근 대상은 오류 및 중간값에 따라 높 주파수 기반 객체는 효율성을 검색하는 데 적용됩니다. 이 전략은 정적 구성이 아니며 열 및 비즈니스 클래스 동적을 방문하도록 조정됩니다。
인덱스 검색 레이어는 메타데이터와 벡터 인덱스를 통합하여 통합된 카탈로그로, thermosphere는 온라인 검색에 연결되며, 콜드 레이어는 아카이브되고 재구성됩니다. 모든 인덱스 버전은 소스 버전을 등록하고 매개 변수를 구축해야합니다. 그렇지 않으면 인덱스 drift는 추적 할 수 없습니다。
가용성 층의 인증서에 노드 행동의 정량. 도전, 응답 시간 프레임 및 재활 성공률에 대한 성공률은 보상 용량 및 가용성을 피하기 위해 연결된 신뢰성, 등급 및 인센티브 할당의 관점에서 모든 평가됩니다。
중요한 접근 제한 및 수락. 고감도 데이터는 키와 시간 벌어지는 허가로 분류되며, 로그를 소지하고, 모델 통화는 재발할 수 있습니다. 허가 작업 자체는 구성을 방지하기 위해 마크를 나눕니다。
5개의 층은 단일 방향 물 선이 아닙니다 구현 수준에 닫힙니다: 데이터 액세스 후, 슬라이스는 객체 레이어로 인코딩되어 체인을 작성하고 앵커 한 후 인덱스를 생성합니다. 온라인 쿼리 열구는 콜드 레이어로 돌아가는 것보다 적은으로 분리되어 있습니다. 완전한 검증 및 인증 검증을 트리거하면서 결과를 반환하고 주요 행동은 결제 및 감사를 입력합니다. 이 체인의 실제 값은 네 가지 질문은 노드 또는 순간에 응답 할 수 있다는 것입니다. 데이터가 어디에서 왔는지, 현재 버전이 무엇인지, 누가 액세스 할 수 있고 시스템이 가용성을 증명 할 수 있는지 여부。
이것은 또한 Bitroot가 AI 저장 거버넌스에 적합 이유입니다. AI Agent의 호출, 모델 버전의 전환, 데이터 권한 변경, 검색 결과에 대한 분쟁은 저주파 백업 작업이 아니지만 응용 성장으로 계속 체인 이벤트입니다. 아래 체인이 지연과 충분한 높은 처리량의 충분한 낮은 확인을 제공하기 위해 실패한 경우, 저장 거버넌스는 결국 체인의 바닥으로 돌아와 수동 재구성에 강제됩니다. Bitroot 및 Pipeline BFT의 병렬 EVM은 더 높은 TPS의 가치가 아니지만, 이 고주파 지배적 인 이벤트를 실시간으로 고정하고 추구 할 수 있습니다。

누가 지불 할거야 : 우리를 사용하여, 용량이 아닌, 반환을 결정
장기에서 실행하기 위하여 저장을 위한 순서에서는, incentives는, 겹쳐 쌓이는 수용량을 읽을 수 없습니다. 용량의 양은 보상, 이는 하드 드라이브와 빛 서비스에 손상된 인센티브와 동일. 이 점은 Filecoin 메커니즘에 의해 수정되었습니다. 그것은 품질 조정 된 전력의 개념을 소개합니다, 특히 유효하고 검증 된 주문의 수용을 허용, 즉, 저장 공간의 최소 측정 단위, 전력의 측정에 더 높은 무게를 얻기 위해, 단지 봉투의 빈 용량보다 실제 서비스를 제공 할 수있는 용량에 대한 인센티브를 기울이십시오. 이 아이디어는 자체 빌딩 인센티브가 될 것입니다。
적어도 4개의 차원을 동시에 계산하고 각 무게 논리를 명확하게 하는 강제적인 incentive 기능으로 끼워넣으십시오. 용량은 기본 공유를 결정하고 약속 한 공간에 얼마나 응답합니다. 온라인 요금 및 응답 시간은 서비스 품질 요소를 결정하고이 공간이 필요할 때 정말 바람직하지 않다는 것을 응답합니다. 이는 더 높은 무게를 가지고 있어야하며 그렇지 않으면 유용성은 슬로건이됩니다. 데이터 복구의 성공률은 재난의 신뢰성을 결정하고 노드가 장기 데이터의 생존에 직접 의존하는 후 응답의 사본을 다시 구축 할 수있는 능력. 데이터 값 밀도는 높은 가치 데이터 세트 및 높은 주문 모델에 대한 차별 멀티 플라이어와 함께 측면에 따라 수요 측면을 결정하며, 더 높은 수익을 얻고 데이터를 호출합니다. Incentives는 선언 된 용량보다 입증 된 서비스로 제공해야합니다。
긍정 인센티브는 혼자 충분하지 않습니다, 바인딩 권고, 처벌, 중재는 동시에 장소, 및 하단 업 변형은 충족 될 것이다: 부정 행위의 예상된 이점은 처벌의 예상 비용보다 낮아야, 그렇지 않으면 어떤 인증 메커니즘 경제 합리적에 의해 우회 될 것입니다. 이 웹 사이트는 귀하가 웹 사이트를 탐색하는 동안 귀하의 경험을 향상시키기 위해 쿠키를 사용합니다. 이 쿠키들 중에서 필요에 따라 분류 된 쿠키는 웹 사이트의 기본적인 기능을 수행하는 데 필수적이므로 브라우저에 저장됩니다. 또한이 웹 사이트의 사용 방식을 분석하고 이해하는 데 도움이되는 제 3 자 쿠키를 사용합니다. 이 쿠키는 귀하의 동의하에 만 브라우저에 저장됩니다. 이러한 쿠키를 거부 할 수도 있습니다. 이러한 쿠키 중 일부를 선택 해제하면 검색 환경에 영향을 미칠 수 있습니다. 중재는 증거 중심 분쟁의 사슬에 근거합니다: 사용자는 데이터가 유효하지 않으며 노드가 정상적인 서비스, 도전 기록, 샘플링 인증서 및 사고 로그를 요청할 경우, 검증 가능한 체인 결정에 수동 개입을 필요로 하는 분쟁을 압축합니다。
AI 시나리오에는 훨씬 더 어려운 지배 층이 있습니다. TRIPARTITE 이득은 어떻게 깨질 수 있습니까? DATA CONTRIBUTORS의 언어에 의해 반복적으로 사용 된 모델, 모델 기여자 훈련, 저장 노드 호스팅, 궁극적 인 통화 값에 기여하는 모든 것이 있지만 직접 관찰하기 어렵다. 이 웹 사이트는 애플 리케이션에 전념. 우리는 정품 앱과 게임을 제공 할 목적으로이 사이트를 만들었습니다. 4APPSAPK 최고의 안드로이드 애플 리케이션을위한 무료 APK 파일 다운로드 서비스, 계략. 이 블랙리스트와 FORFEITURE 메커니즘과 함께, 이는 악성 데이터 업로드, 저작권 침해 및 모델 도난에 대해 한 번 중재 후 진행. 그렇지 않으면, 반대 직관적 인 결과가있을 것입니다 : 더 성공적인 자산화, 더 많은 분쟁은 분할되고 VESTED, 궁극적으로 붕괴되는 정확하게 생태적 신뢰 자체입니다。
규정 준수는 패치가 아니지만 바인딩 구조 기간 : 보안 기반은 엔드 투 엔드 암호화, 계층화 된 키 관리 및 사이클 회전, Superimproving Hashi 및 Merkle은 다운로드가 실패 복구를 커버하기 위해 검증되고 여러 사본 및 데코드가 결합 될 수 있도록 약속합니다. 데이터 수준에 기반한 개인 정보 보호 사이드 최소 액세스 제어, 권한 부여, 일회성 및 시간 배율 승인의 철수 지원, 중요한 액세스 및 작업에 표시를 남겨 전체 링크로 다시 감사를 촉진합니다. 이 웹 사이트는 애플 리케이션에 전념. 우리는 정품 앱과 게임을 제공 할 목적으로이 사이트를 만들었습니다. 4AppsApk 최고의 안드로이드 애플 리케이션을위한 무료 APK 파일 다운로드 서비스, 계략. 이 웹 사이트는 귀하가 웹 사이트를 탐색하는 동안 귀하의 경험을 향상시키기 위해 쿠키를 사용합니다. 이 쿠키들 중에서 필요에 따라 분류 된 쿠키는 웹 사이트의 기본적인 기능을 수행하는 데 필수적이므로 브라우저에 저장됩니다. 또한이 웹 사이트의 사용 방식을 분석하고 이해하는 데 도움이되는 제 3 자 쿠키를 사용합니다. 이 쿠키는 귀하의 동의하에 만 브라우저에 저장됩니다. 이러한 쿠키 중 일부를 선택 해제하면 검색 환경에 영향을 미칠 수 있습니다. 이러한 쿠키 중 일부를 선택 해제하면 검색 환경에 영향을 미칠 수 있습니다. 이러한 쿠키 중 일부를 선택 해제하면 검색 환경에 영향을 미칠 수 있습니다. 지표 시스템은 전략적 시스템이며 발표 보고서가 아닙니다. 저장 프로그램은 기술적인 품목만, 사업 결과 없이, 기록되는 경우에 순으로 비용 센터로 붕괴합니다; 권고는 3개의 층에서 합니다: underlying 기술적인 지시자 (availability, P95/P99 시간 지연, 처리량, RTO/RPO의 과실 비율)는 체계, AI의 특정한 지시자 (훈련 자료 traceability 비율, 모형 recoverability 비율, reasoning validation 적용, 색인 견실함) 응답의 건강에 응답합니다, 모형의 질은, (조정되는), 실제적인 측정값의 사이에서, 확고한 차원이 감소된 이익, 확고한 차원이 있는 3개의 층을 설명합니다. 이 웹 사이트는 애플 리케이션에 전념. 우리는 정품 앱과 게임을 제공 할 목적으로이 사이트를 만들었습니다. 4AppsApk 최고의 안드로이드 애플 리케이션을위한 무료 APK 파일 다운로드 서비스, 계략。
Bitroot를 위한 가득 차있는 닫히는 반지: 자료에서, AI 대리인에 모형
이 링에서 Bitroot는 AI 자산의 모든 주요 행동을 합의 이벤트로 전환 할 수 있습니다 : Dataset 등록, 모델 릴리스, 벡터 인덱스 재건축, AI 에이전트 통화, 이해의 닻을 기록, 권위 및 재직, 분쟁 문제 및 중재 결과. 체인은 모든 데이터를 포함 할 필요가 없지만 이러한 행동의 가장 작은 증거. 이 방법으로는 데이터, 모델, 알고리즘 및 애플리케이션 간의 가치 관계가 프로그래밍 가능한 하위 계정 및 감사 가능한 거버넌스에 대한 헌신을 넘어갑니다。
Bitroot의 운영 및 생태 확장에서이 메커니즘을 배치하려면 저장 인센티브는 별도의 하드웨어 보조제로 설계되어야하지만 AI 스택 플로우의 일부이어야합니다. 데이터 기여자는 데이터의 훈련 또는 전송에서 혜택을받을 수 있으며 모델 기여자는 모델 서비스, 저장 및 검색 노드에서 혜택을받을 수 있으며 지속적인 가용성 및 서비스 지연, 인증 및 도전 노드는 비 가용성, 색인 또는 허가를 발견하는 것으로 보상됩니다. 이런 식으로 Bitroot의 경제 시스템 보상은 업로드에 의해 아니지만, "지속적으로 유용합니다."。
스토리지는 비용 센터가 아니지만 신뢰와 가치 분배 시스템
AI 시대의 유통 저장은 객체의 저장 제품의 교체가 아니라 탈중앙화 된 NARRATIVE의 추적이 아니라 4 가지 더 어려운 것들 : 시간이 지남에 따라 가능한 신뢰할 수있는 증거, 주제 전반에 걸쳐 작동되는 지배의 순서, 데이터 및 모델에 대한 책임의 사슬, 지속 가능한 경제 인센티브。
단일 인식 단일 층 구조는 이러한 목적을 커버하지 않습니다. 더 현실적인 경로는 모듈 구조입니다: 내용 위치 무결성, 안전 시간 차원의 가용성의 저장 증거, 긴요한 역사의 영원한 층, 열구에 선 경험, 안전 지배력 및 정리에 사슬 고정. 그것은 타협하지 않습니다, 그것은 엔지니어링 이유입니다. 착륙의 초점은 가장 기능적이지 않지만, 가장 작은 신뢰할 수있는 닫힌 원형을 사용하여 첫 번째로 설립되어 AI의 자산화, 검증 가능한 분산 및 자동화 된 거버넌스에 의해 이어졌습니다。
그것은 3 단계 가동입니다. 첫째 날은 8 필드 데이터 재고를 완료, 세 번째 날은 액세스, 저장, 실시간 비즈니스 영역에서 검증에 대한 검색, 그리고 일곱 번째 날은 P95 시간과 단위 비용에 마이그레이션 임계값을 실행. 이렇게 해서, 팀은 CONSENSUS를 엔지니어링하는 개념에서 이동했습니다。
또한 사실적인 경계가 있습니다: 계약의 조합에 관계 없이, 비용, 내구 및 내구성 사이 무역 떨어져 있고, 모든 가동을 위해 최선인 단 하나 대답이 없습니다. 진정한 지속 가능한 프로그램은 명확한 경계 아래 연속적인 패턴에서 온다, 오히려 보드 후 장기적 정적 구성보다。
프로젝트의 미래 단계 아웃은 종종 TPS에 너무 높지 않지만 데이터 책임 체인은 불충분합니다. AI 시대에서 저장은 데이터를 입력하지 않지만 데이터가 항상 입증 될 수 있습니다。
관련 상품
실제 AI-chain 경쟁은 TPS, 가스 또는 확인 시간과 비교하여 끝나지 않습니다. 공연은 입구이지만 끝이 없습니다. AI 어플라이언스 시대에 들어가면 체인 시스템은 트랜잭션뿐만 아니라 데이터 버전, 모델 통화, 알고리즘, 소싱 레코드, 에이전트 행동 및 여러 배포를 수행 할 예정입니다。
그것은 또한 Bitroot의 저수지의 판단입니다: 저장은 ancillary 단위 아닙니다, 그러나 가치의 근원에 AI 더미의 가장 가까운 층. 데이터가 입증 될 수 있는지 여부, 모델이 재제작 될 수 있는지 여부, 전화가 감사 할 수 있는지 여부, 절차가 자동으로 배포 될 수 여부, 또는 탈중앙화된 AI 네트워크가 장기적으로 승리 여부。
Bitroot는 더 빠른 구현을 추구하는 체인을 구축하지는 않지만 AI 자산을 식별 할 수있는 인프라, 호출, 명확하고 지배. 평행한 EVM와 파이프라인 BFT는 고주파 사슬 사건의 나르는 수용량을, 분배한 저장 및 verifiable 기계장치 해결합니다 AI 자료와 모형의 신뢰 기초를, 풀그릴 잠수함 및 사슬 지배인은 계속한 경제 인센티브로 공헌을 번역합니다。
AI Agent가 사용자를 대신하기 위해 시작될 때, 모델 및 데이터가 양도할 수 있는 자산이되기 시작될 때, 저장은 더 이상 "파일을 배치할 때"의 질문은, 저장 및 소원 서비스는 동일한 가치 네트워크를 입력합니다。
AI 공공 체인의 신뢰 기지이며 차세대 지능형 네트워크의 가치 분배 시스템입니다。
Bitroot에서, 그것은 미래의 실제 중요성이 가장 데이터가없는 것 같다, 그러나 누가 그것을 입증 할 수, 접근 가능, 주어진 시간에 회계 및 궁극적으로 가치 정착에 참여。
Bitroot에 관하여
Bitroot는 AI 본래 구조를 가진 층 1 공중 사슬 프로젝트에 평행한 초점입니다. Bitroot는 EVM 호환 기술 루트를 사용 하 여 고성능, 낮은 비용 구현 환경을 탐구 AI 에이전트, DeFi 및 Web3 응용 프로그램 병렬 구현 메커니즘을 통해, 합의 최적화 및 AI 인터페이스 디자인。
이 종이는 기여하고 Black Beats의 관점을 나타내지 않습니다。
