
a16z:AIのためのアンネシア、それを継続学習することができますか
ブレークスルーは、モデルをデプロイして訓練するときに強いものにすることです: 圧縮, 抽象化, 学習。

オリジナルタイトル: 定期的なリースが必要な理由
原作:マリカ・アユバキロヴァ、マット・ボルスタイン、16z暗号
元の言語:深い潮テックフロー
クリストファー・ノランのMementoでは、主要な俳優、レオナード・シェルビーが壊れた瞬間に住んでいます。 脳の損傷は、新しいメモリの増殖と損失に苦しむために彼を引き起こしました。 数分間、彼の世界がリセットされ、永遠の「この瞬間に」閉じ込められている - 何が起こったのかを記憶し、何が起こるか疑問に思う。 生き残るために、彼は脳が実行できない記憶機能を置き換えるために、彼の体を書いて撮影しました。
ビッグ・ランゲージ・モデルは、同じ永遠の時代に生きています。 トレーニングの後、知識の量はパラメータで凍結され、モデルは新しい記憶を作成しず、新しい経験の光でパラメータを更新しません。 このギャップを埋めるために、私たちはそれを足場に入れます:短期のハンドプリントとしてチャット履歴、外部のノートとして検索システム、入れ墨としてシステムヒント。 しかし、モデル自体は、この新しい情報に本当に統合されていない。
研究者が増えていると、これが不足していると考えます。 コンテキストラーニング(ICL)は、世界の一部の地域で既に存在する回答(または回答のフラグメント)が既に存在する場合に問題を解決します。 しかし、モデルが導入後に新しい知識と経験を直接含める方法を必要とする理由は、実際に発見される必要があるそれらの問題(例えば、新しい数学証明書)、対立シナリオ(例えば、セキュリティ上の注意)、または言語で表現する余りな微妙な知識のために。
コンテキスト学習は一時的です。 実際の学習は圧縮を必要とします。 モデルが圧縮されるまで、メモリ残骸の永遠の瞬間に閉じ込められます。 逆に、モデルを訓練すれば、外部のカスタマイズされたツールに依存するのではなく、独自のメモリ構造を学ぶことができます。完全に新しいスケーリング次元を解除できます。
このフィールドは継続学習(継続学習) このコンセプトは新しいものではありません(McCloskeyとCohen 1989の論文をご覧ください)が、現在のAI分野における最も重要な研究の方向の1つです。 過去2〜3年にわたるモデリング能力の爆発的な成長は、モデルの認知度と認知度がますます顕著に区別しました。 この記事の目的は、私たちがフィールドのトップ研究者から学んだことを共有することです, 継続的な学習のさまざまなパスを明らかにし、起業家の生態学におけるこのトピックの開発に貢献するために役立つために。
注意: 優れた研究者、博士学生、起業家のグループと集中的な交流から恩恵を受ける記事の形状は、継続的な学習の分野での仕事と洞察を寛大に共有しました。 理論的基礎から、後進学習の工学的現実に至るまで、その洞察は、私たちが単独で書かれているよりも、より固体を作った。 皆様のお越しをお待ちしております
コンテキストから始めましょう
パラメータレベルの学習を防御する前に(モデルの重みを更新する学習)、コンテキスト学習が機能するという事実を認識する必要があります。 勝ち続けるという強い引数があります。
トランスの本質は、シーケンスの条件に基づいて、次のトークン予測者です。 正しいシーケンスを与え、あなたは驚くほど豊かな行動を得、あなたは体重に触れる必要はありません。 そのため、コンテキスト管理、ヒント、指示の微調整、いくつかのサンプル例は非常に強力です。 スマートカプセル化は静的パラメータであり、ウィンドウにフィードするときに劇的に変化を示す機能です。
Cursorによる最新の詳細な記事は、自動プログラミングのスマートスケーリングに関するものです。モデルの重みは固定され、システムが実行されるのは、コンテクストの細かいレイアウトです。まとめると、数時間で一貫性を維持する方法が自律的な操作です。
OpenClawは他の良い例です。 特別なモデルの特権(底ですべて利用できる)のために爆発しませんが、コンテキストとツールを優れた効率で作業条件に変換します。何をしているかを追跡し、中級を指示し、再侵入を決定し、以前の作業の永続的な記憶を維持します。 OpenClawは、インテリジェントの「シェルデザイン」を独立した規律に引き上げました。
プロジェクトのプロンプトが最初に現れたとき、多くの研究者は「広告だけで」が適切なインターフェイスである可能性があるという事実について意味がありました。 ジャックのように見えます。 しかし、トランスアーキテクチャのオリジナル製品であり、再訓練を必要としず、モデルの進捗として自動的にアップグレードされます。 モデルが強くなると、ヒントが強くなります。 「シンプルだけどプリミティブ」インターフェイスは、一番下のシステムに直接接続するので、しばしば勝っています。 これまでのところ、LMの軌跡はまさにそのものです。
状態空間モデル: コンテキストのステロイド バージョン
コンテキスト学習モデルは、元のLMからインテリジェントな循環に移動する主流ワークフローとして圧力を増加させています。 過去には、文脈の窓が十分に満たされるのは比較的まれでした。 通常、LM がディスクリートタスクの長い行を実行するように求められているとき、アプリケーションレイヤーはチャット履歴をより直接切断し、圧縮することができます。
しかし、インテリジェントな身体のために、使命は、常に利用可能なコンテキストの大部分を食べることがあります。 インテリジェントサイクルの各ステップは、最初のシーケンスが渡されるコンテキストに依存します。 そして、行が壊れているので、彼らはしばしば20〜100ステップ後に失敗します。コンテキストが満たされ、一貫性が劣化し、それは含まれません。
その結果、主要なAIラボでは、超長期のコンテキストウィンドウのモデルを開発するために、重要なリソース(大規模のトレーニング操作)を奪います。 これは自然な道です。, それは既に有効である方法に基づいているので (コンテキストで学習) そして、業界 ' s の一般的な傾向と推論にシフトする. 最も一般的な構造は、固定記憶層です。例えば、状態空間モデル(SSM)とリニアな注意の変形(以下、総称してSSM)を、一般的な注意を払ったものです。 SSMは、根本的に優れたスケーリング曲線をコンテキストで提供します。
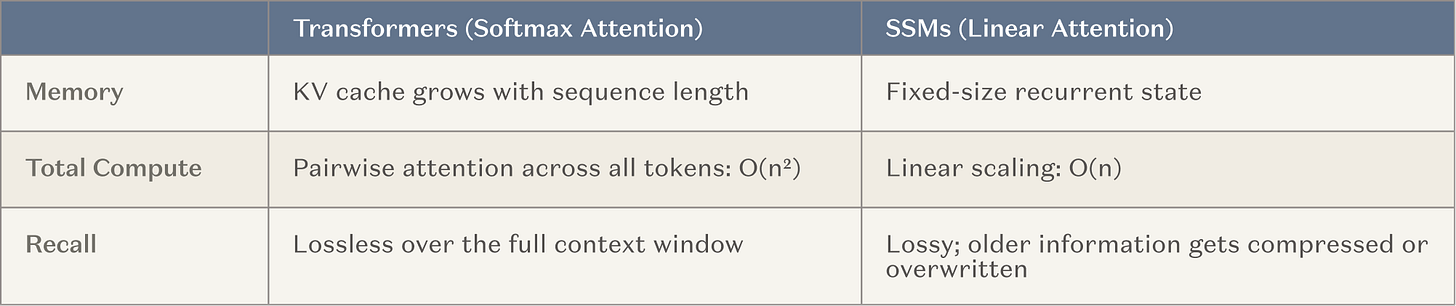
図:従来の注意メカニズムのスケーリングと比較してSSM
目標は、従来のトランスによって提供される広範なスキルと知識を失うことなく、約20から約20,000までの一貫した手順の数を上げるためにインテリジェントを助けることです。 成功すると、これは長期にわたるインテリジェントのための主要なブレークスルーです。
継続学習の形態として、これを見ることができます。 モデルの重みが更新されず、外部メモリ層が導入されず、交換が困難でした。
そのため、これらの非パラメトリックメソッドは現実的で強力です。 継続的学習の評価は、ここで開始する必要があります。 質問は、今日のコンテキストシステムが機能するかどうかではありませんが、それはそうではありません。 質問は:私達は天井を見ました、そして新しいアプローチは私達を更に導くことができますか。
コンテキストで何が欠落していますか
「AGIと事前訓練されたことは、意味で、彼らは圧倒...人間はAGIではありません。 はい、人間はスキルベースを持っていますが、知識の大きな問題はありません。 継続的学習に頼ります。
超スマート15歳の男の子を作ったら、何も知りません。 学習意欲のある学生。 あなたが言うことができます, プログラマになる, 医者に行く. 導入自体は、いくつかの種類の学習、テスト、エラーを含みます。 完成品を捨てない工程です。 Ilya Sutskever(イリヤ・ススキバー)
無制限のストレージスペースでシステムを想像してみてください。 世界最大規模のファイリングキャビネットは、インデックス化され、アクセス可能です。 何でも見つけられます。 学びましたか
いいえ。 圧縮を行わないのは無理です。
これは、Ilya Sutskever: LLMが基本的に圧縮されたアルゴリズムで前のポイントを引用する私たちの引数の核です。 トレーニングの過程で、インターネットをパラメータに圧縮します。 圧縮はダメージを受け、強いダメージです。 コンプレッションフォースモデルは、構成、一般化、コンテクストを横断できる標識を構成します。 すべてのトレーニングのハードバックサンプルのモデルは、ボトムパターンのモデルではありません。 圧縮は学習そのものです。
基本的に、LLMがトレーニング中に非常に強力であるように許可したメカニズム(生データを圧縮、転送可能な症状に圧縮)は、デプロイ後にそれらを続行させることを拒否したものです。 その瞬間に圧縮を止め、外部メモリに交換しました。
もちろん、ほとんどのスマートボディケーシングは、いくつかの方法でコンテキストを圧縮します。 しかし、モデル自身が圧縮、直接、大規模なスケールで学ぶべきビットレッスンではありませんか
Yu Sunは、この議論の一例を共有しました:数学. フェルマットの理論を見てみましょう。 長年にわたり、数学者は正しい文学を欠いているだけでなく、解決策は非常に新規であるため、それを証明していません。 数学と最終的な答えの知識との間の概念的な距離はあまりありません。
アンドリュー・ワイルズ、彼は最終的に1990年代にそれを取ったとき、イソレーションで7年間働いた、答えに到達するために新しい技術を発明しました。 彼の認定は、2つの異なる数学枝に成功した橋に依存しています。楕円曲線とモデルの形態。 ケン・リベットは、以前、この接続がFermatian Theoremを自動的に解決することができることを証明しましたが、誰も実際にワイルの前にブリッジを構築するための理論的なツールはありません。 Grigori Perelmanはポンガリの推測の証拠と同じことをすることができます。
コアの問題は次のとおりですLLMが何かを欠いているというこれらの例は、優先順位を更新し、創造的に考える能力はあるのでしょうか? あるいは、物語は反対を証明するだけです。すべての人間の知識は、訓練され、再構成できるデータであり、WilesとPerelmanは、より大きな規模でLMができることを示していますか
質問は必須であり、答えは不確実です。 しかし、今日の学習に失敗する問題の多くのカテゴリがあることを知り、パラメータレベルの学習が役に立つかもしれません。 例えば:

図: コンテキスト学習障害、パラメータ学習の可能性のある問題カテゴリ
より重要なのは、文脈学習は、言葉で伝えられない概念を重み合わせることができる一方で、言語で表現できるものだけに対処することができます。 一部のモデルは高すぎ、目に見えない、あまりにも深く構造化される。 たとえば、医療スキャンでは、腫瘍の視覚的なテクスチャから激しい擬似腫瘍を区別する視覚的なテクスチャ、または話者のユニークなリズムを定義するオーディオのわずかな変動は、正確な語彙に簡単に壊れません。
言語は、それらにのみ似ています。 そのような知識は、その体重内でしか生き残ることができません。 言葉ではなく、学習サインの空間に住んでいます。 コンテキストウィンドウの成長に関係なく、テキストに記述できない知識が常にありますが、パラメーターによってのみ実行できます。
これは、明らかな「ロボットがあなたを思い出させる」機能(ChatGPTのメモリなど)が、ユーザーが驚くのではなく、不快になる理由を説明するかもしれません。 ユーザーが本当に「記憶」ではなく「パワー」を望んでいます。 行動パターンを内部化したモデルは、新しいシーンに翻訳することができます。単にあなたの歴史を覚えているモデルはそうではありません。 「これは、このメールに答えた最後の時間を書いたものです」と「自分が必要とするものを予測するのに十分な考え方を理解している」の違いは、検索と学習の間のギャップです。
継続学習入門
継続学習には多くのパスがあります。 分割線は「メモリなし」ではなく、圧縮が起こる場所これらのパスは、非圧縮(ピュア検索、重量凍結)からフル内部圧縮(重量学習、モデルがよりスマートになります)まで、スペクトルに沿って配布されます。重要な領域(モジュール)。
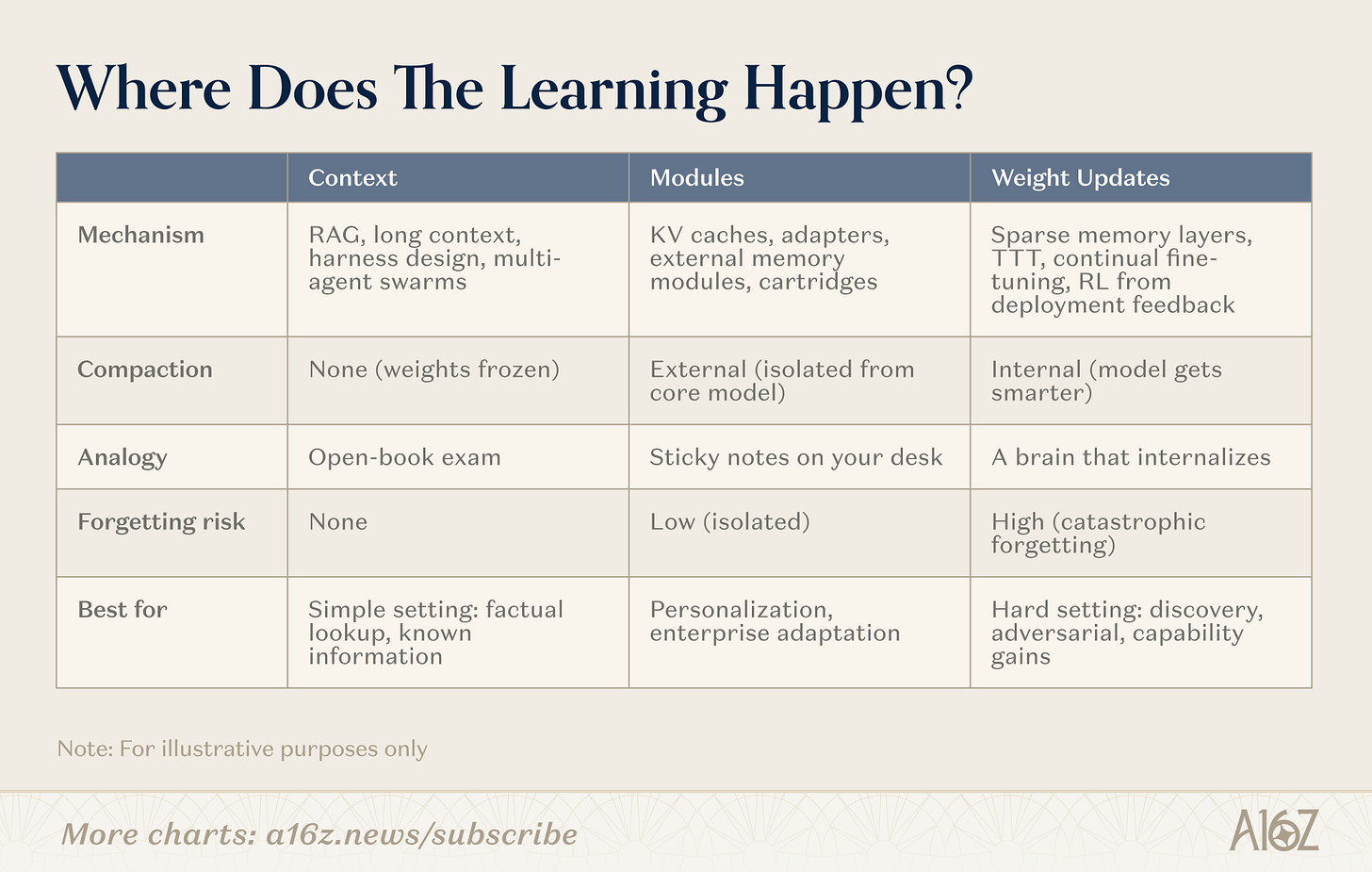
図: 連続学習のための3つの経路 - コンテキスト、モジュール、重量
コンテンツ
コンテキストのこの端で、チームはよりインテリジェントな検索チューブ、スマートボディケーシング、ヒント組織を構築します。 これは最も成熟したカテゴリです: インフラが検証され、展開パスはクリアです。 制限は深さ: コンテキストの長さです。
注目すべき新しい方向: コンテキスト自体のスケーリング戦略としての多知的構造。 単一のモデルが128Kトークンウィンドウに閉じ込められている場合、インテリジェントなボディの調整されたセット - それぞれ独自のコンテキスト、問題に焦点を当てた単一のスライス、および互いにコミュニケーションの結果 - 無限の作業メモリ全体を近似することができます。 各スマートボディは、独自のウィンドウでコンテキスト学習を行い、システム集計を行います。 KarpathyのAutoresearchプロジェクトとCursorのWebブラウザの最近の例は初期です。 これは純粋に非パラメトリックなアプローチ(重量を変えない)ですが、コンテクストシステムが達成できる天井が大幅に上昇します。
モジュール
モジュラー空間では、チームは組み込み型のナレッジモジュール(圧縮されたKVキャッシュ、アダプタレイヤー、外部メモリストレージ)を構築し、再トレーニングなしで汎用モデルをプロテインします。 適切なモジュールを持つ8Bモデルは、ターゲットタスクの109Bモデルのパフォーマンスに一致させることができます。 魅力は、既存のトランスインフラと互換性があることです。
体重
重みの更新の最後に、研究者は真のパラメータレベルの学習を求めています。関連するパラメータセグメントの薄いメモリ層だけを更新し、フィードバックからモデルの強化学習サイクルを最適化し、推論のコンテキストで圧縮重量のテストでのトレーニングを最適化します。 これらは最も深く、導入が困難ですが、モデルは新しい情報やスキルを完全に統合することができます。
パラメータを更新するための多くの特定のメカニズムがあります。 いくつかの研究の方向は与えられます:
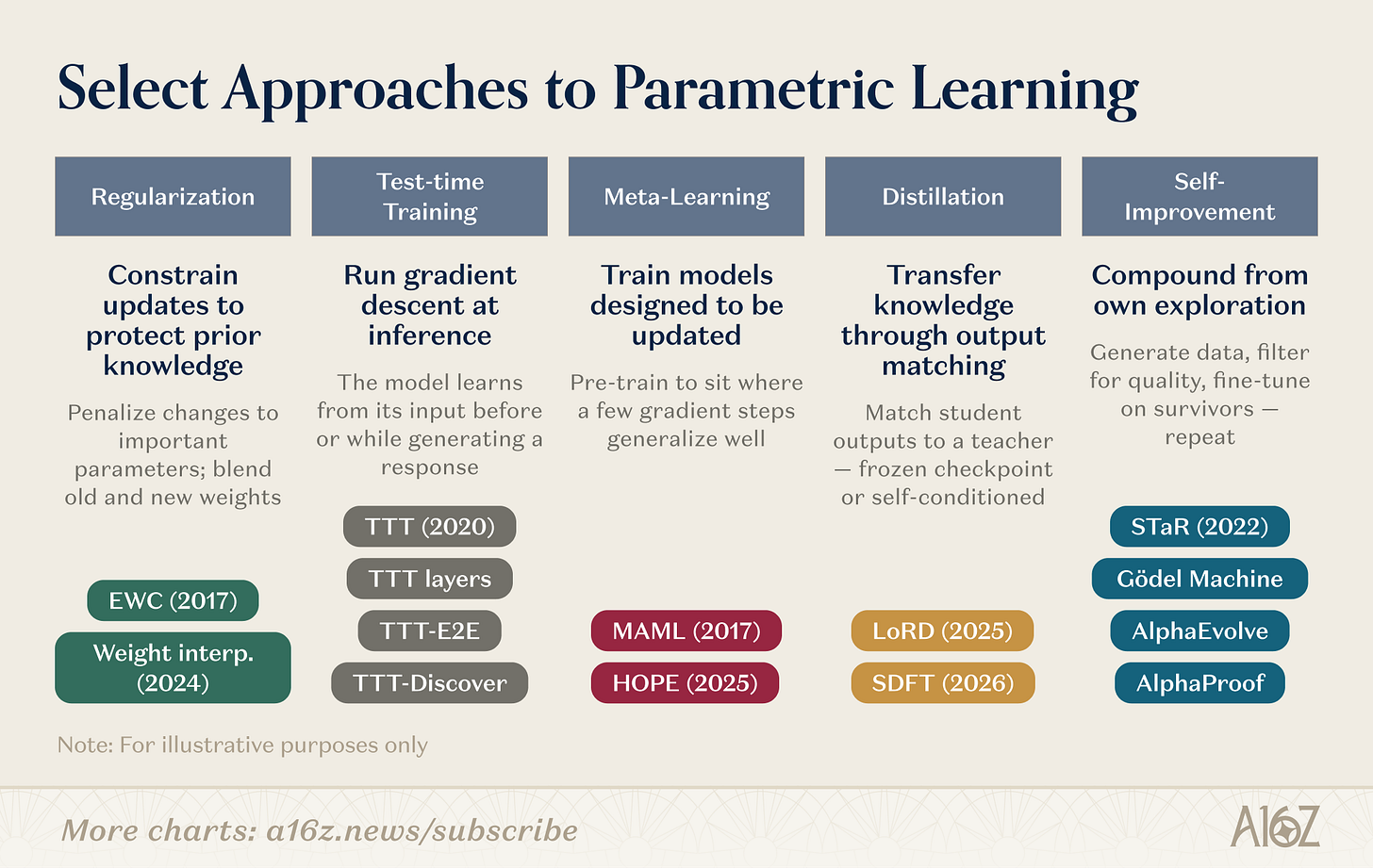
図:重み学習のための研究の方向の概要
重み付けの研究は、いくつかの並列ルートをカバーしています。正規化と重みのある空間アプローチ最古の: EWC (Kirkpatrick et al., 2017) は、以前のタスクへのパラメータの重要性に基づくパラメータの変更を罰します。重量の異動(Kozal et al., 2024)は、パラメータ空間の古いおよび新しい重量構成をブレンドしますが、両方とも大規模に脆弱です。
試験中のトレーニングSun et al. (2020) によって作成され、アーキテクチャ(TTT レイヤー、TTT-E2E、TTT-Discover)の元の言語に開発され、アイデアは異なります。テストデータにグラデーションを下げ、必要な瞬間に新しい情報をパラメーターに圧縮する。
ユアン・ラーニング質問は: 学習方法を学ぶためにモデルを訓練できますか? MAML(Finn et al., 2017)のいくつかのサンプルフレンドリーなパラメータの初期化から、Bohrouz et al.(Nested Learning, 2025)の組み込み学習まで、モデルをレイヤーの最適化問題に構造化し、異なる時間スケールで高速適応および低速モジュールを実行し、生物学的メモリの統合に触発しました。
免責事項以前のタスクの知識は、冷凍教師チェックポイントで学生モデルをマッチングすることで維持されます。 LoRD (Liu et al., 2025) は、モデルを切断し、バッファゾーンを同時に再生することにより、持続可能になる点に、蒸留を効率的に動作させることができます。 自己蒸留(SDFT、Shenfeld et al。、2026)は、モデルの ' s 独自の出力を使用して、トレーニングシグナルとして、シーケンスの微調整の宇宙飛行メモリを迂回します。
再帰的自己改善同様のラインで動作します: STAR (Zelikman et al., 2022) 推論の自己生成されたチェーンから推論ガイド; AlphaEvolve (DeepMind, 2025) は、数十年にわたって改善されていないアルゴリズム最適化を発見しました。シルバーとストンの「経験の素晴らしさ」 (2025) は、決して止まらない経験の継続的なフローとして、インテリジェントな身体の学習を定義します。
これらの研究の方向は集まります。 TTT-Discover はテスト トレーニングと RL 駆動探査を統合しました。 HOPEは、単一の構造で遅い学習サイクルを埋め込む. SDFTは自己改善のための基本的な操作に蒸留を回します。 列間の境界は膨らむ。 次世代の連続学習システムは、戦略を組み合わせる可能性があります。安定化、メタ学習を加速し、化合物の利益に対する自己啓発。 この技術倉庫のさまざまなレベルにスタートアップが増えています。
継続的な学習起業家精神
スペクトルの非パラメータ端は最もよく知られています。 シェル会社(Letta、mem0、Sub意識)は、レイヤーと足場をビルドし、コンテキストウィンドウのコンテンツを管理します。 外部ストレージとRAGインフラストラクチャ(例:Pinecone、xmemory)は、検索バックボーンを提供します。 データは存在し、チャレンジは、モデルの正面に適切なスライスを適切なタイミングで置くことです。 コンテキストウィンドウが拡大するにつれて、これらの企業の設計スペースは、特に外側の地殻で行われています。新しいスタートアップの波は、ますます複雑なコンテキスト戦略を管理するために新興しています。
パラメータは、より早く、より多くのドルです。 ここには、重みに新しい情報を統合するための「分解圧縮」のバージョンを試しています。 パスは、公開された後にどのモデルを学ぶべきかについて、大まかにいくつかの異なる賭けに分けることができます。
部分的な圧縮:再訓練なしで学ぶことができます。一部のチームは、埋め込まれた知識モジュール(圧縮されたKVキャッシュ、アダプタレイヤー、外部メモリストレージ)を構築し、コア重量を移動することなく、汎用モデルをプロファイブしています。 一般的な引数は、学習が分離され、パラメータを渡って分散されていないため、管理可能な限界内の安定性可塑性のバランスを維持しながら、有意義な圧縮(検索だけでなく)を得ることができます。 8Bモデルは、ターゲットミッションの大きなモデルの性能に合わせて適切なモジュールを装備しています。 利点は可搬性です:モジュールは独立した交換または更新することができる既存の変圧器の構造と差し込むことができ、実験の費用は集中的な訓練の費用より大いにより低いです。
RLおよびフィードバック周期:信号から学ぶこと。他は、既に展開サイクル自体に存在するポスト・ドプロメント・ラーニングの最も豊富な信号が、実際の世界的結果から、ユーザーの補正、ミッションの成功、障害に対する報酬の信号であることに賭けています。 コアのアイデアは、モデルが潜在的なトレーニング信号として各相互作用を扱うべきであるということです, 理由の要求だけでなく、. これは、仕事で人間が進行する方法に非常に似ています: 作業, フィードバックを得ます, どのような作品を統合. エンジニアリングの課題は、壊滅的な緩和なしに、体重の安定した更新に薄く、騒々しい、時には対立的なフィードバックを変換することです。 しかし、本当に展開から学ぶモデルは、以下のシステムができない方法で化合物価値をもたらすことができます。
データの焦点:正しい信号から学ぶこと。関連するが、差別化された賭けは、ボトルネックがアルゴリズムを学習していないことですが、データと周辺システムを訓練します。 これらのチームは、継続的な更新を駆動するために正しいデータをフィルタリング、生成、または合成することに焦点を当てています。 高品質な学習信号と整形学習信号のモデルが、より小さなグラデーションで有意に改善できることを前提としています。 これはフィードバックループ企業との自然な関係ですが、上流の質問は強調されています。モデルが1つのことであるかどうか、彼らが学ぶべきこと、そしてどのような程度にするか。
新しいアーキテクチャ:底から能力を学習します。最も根本的な賭けは、トランスアーキテクチャ自体がボトルネックであり、その継続的学習は根本的に異なる計算条件条件条件を必要とします。時間の動と組み込みのメモリメカニズムの連続構造。 ここでの引数は構造的です: 連続的な学習のシステムが必要な場合は、学習メカニズムを下部のインフラに埋め込む必要があります。

図: 継続的な学習のためのビジネススタートアップ
これらのカテゴリに主要な研究所も活動しています。 一部の人々は、より良いコンテキスト管理と思考チェーンの推論を探求しています。いくつかの外部メモリモジュールやスリープタイムコンピューティングチューブで実験されており、いくつかの目に見えない企業が新しい構造を追求しています。 このエリアは、メソッドが勝てず、ケースのパントを与えて、単一の勝者がないことを確認するのに十分です。
なぜ簡単な更新が失敗しますか
生産環境のモデルパラメータを更新すると、現在大規模に解決されていない一連の失敗したモデルをトリガーできます。

図: 単純重量更新の失敗モード
エンジニアリングの問題はよく文書化されています。 catastrophe の oblivion は、新しいデータから学ぶのに十分な敏感なモデルは、安定性と可塑性の既存の症状を破壊することを意味します。 時間の分解は、重量の同じセットが一定の規則と変数状態によって圧縮され、その1つの更新が他を傷つけることを意味します。 事実の更新がトークンのシーケンスに限られた変更が、意味的な概念ではなく、その推論に普及しなかったため、論理的な統合は失敗しました。 未学習はまだ不可能です:デミニミス操作はありませんので、偽りや有毒な知識のための正確な外科的除去プログラムはありません。
問題の第二のカテゴリは、あまり注目を受けていません。 現在のトレーニングと展開の分離は単なるエンジニアリング施設ではありません。セキュリティ、監査、ガバナンスの枠組みです。 この境界線を開き、多くのことが同時に間違っています。 セキュリティアライメントは予測不可能に劣化する可能性があります。ベニグデータの微調整が狭い場合でも、広範な障害につながる可能性があります。
継続的な更新は、データの中毒の攻撃的な顔を作成しました。これは、ヒントの遅い、永続的な注入ですが、それは重量に住んでいます。 継続的に更新されたモデルがバージョン管理、回帰テスト、ワンオフ認証に使用できないモバイルターゲットであるため、可聴性が崩壊します。 ユーザーがパラメータに相互作用する場合、プライバシーリスクの増加と機密情報はフォームに焼くことで、コンテキスト内の情報を取得するよりもフィルタリングが難しくなります。
これらは、基本的な不可能ではなく、オープンネスの問題です。 コアアーキテクチャの課題に取り組むような、それらに対処することは、進行中の学習研究アジェンダの一部です。
メモリフラグメントから実際のメモリまで
メモリフラグメントのレオナードの悲劇は、彼が動作できないことではありません - 彼はあらゆるシナリオでリソースフルで華麗です。 彼の悲劇は、彼は決して回復しないということです. それぞれの経験は、外に滞在しています。それは、入れ墨、他人の手書きです。 彼が検索することができますが、新しい知識を圧縮することはできません。
レオナルドがこの自作の迷路を歩き回った時、真実と信念の線が鈍いようになりました。 彼の病気は、彼の記憶の否定的ではありません彼の意味を再構築するために彼を強制的に彼自身が自分の物語の探偵と信頼できない記者になるようにしましょう。
今日のAIは、同じ制約で実行されます。 私たちは、より長いコンテキスト・ウィンドウ、よりインテリジェントなケーシング、調整されたマルチ・インテレグエンス・クラスター、そして、彼らは機能します。 しかし、検索は学習量が少ない。 事実を明らかにできるシステムが構造物を見ることは余儀なくされていません。 一般化されていない。 非常に多くのトレーニングが非常に有害な圧縮されるようにしましょう - 生データを転送可能な表現メカニズムに変える - - 具体的には、展開の瞬間にオフにしました。
パスフォワードは、単一のブレークスルーではなく、むしろレイヤードシステムではない可能性があります。 コンテキスト学習は、引き続き防衛の最初の行になります。それは元の検証され、常に改善されます。 モジュラー機構は、分野におけるパーソナライゼーションと専門化の中間地に対処できます。
しかし、本当に困難である人のために — 発見、適応、言葉で表現できない隠された知識 — 私たちは、モデルがトレーニング後にパラメータに経験を圧縮し続けるようにする必要があるかもしれません。 これは、薄いアーキテクチャ、メタ学習目標、自己改善サイクルの進行を意味します。 また、固定重量のセットではなく、メモリ、更新されたアルゴリズム、および独自の経験から抽象的な能力を含む進化型システムなど、モデルが何を意味するのかを再定義する必要があります。
ファイリングキャビネットは成長しています。 しかし、より大きなキャビネットは、アーカイブキャビネットです。 ブレークスルーは、モデルをデプロイして訓練するときに強いものにすることです: 圧縮, 抽象化, 学習. 記憶喪失モデルから、経験の光をモデルに転換点に立っています。 それ以外の場合は、メモリデブリに固執します。
オリジナルリンク
