
a16z:AI的失憶症
當模型被部署與訓練時。

原文:為什麼我們需要定期穿梭
原文由Malika Aubakirova
原文:深潮科技花
在克里斯托弗·諾蘭的"梅門托"中,主角倫納德·谢尔比生活在一個破碎的瞬間. 腦部的損失使他受到拖延和失去新的記憶。 每幾分鐘,他的世界就被重置,困在永恆的"此刻"中——記住剛才發生了什麼,想知道會發生什麼. 為了生存,他寫作并拍攝了自己的身體,以取代大腦不能履行的記憶功能。
大語言模型生活在相似的永恆時代. 在訓練之後, 知識的質量在參數中被冻结, 為了填補這個空間, 我們把它放在腳手架上:聊天歷史作為短期手印, 检索系統作為外部筆記, 但模型本身 從來沒有真正內化這項新信息。
越来越多的研究者認為這不足。 如果答案(或答案的片段)已經存在, 因為那些需要實際發現的問題(例如新的數學憑證)、對峙的假想(例如安全預防措施), 或對於語言上言語上太微妙的知識。
環境學是暫時的。 真正的學習需要压缩 。 除非我們讓模型繼續壓縮 它可能困在永存的記憶碎片中 如果我們能訓練模型學習自己的記憶體結構。
此字段叫做繼續學習(繼續學習) 我們認為這是目前AI领域最重要的研究方向之一。 建模能力在過去兩到三年的爆炸性增長, 這篇文章的用意是分享我們從该领域的頂尖研究者所學到的東西。
注: 這篇文章的造型得益于與一群优秀研究者、博士生和企業家的密切交流, 從理論基礎到部署後學習的工程現實, 謝謝你的時間和想法
從上下文開始吧
在辯護參數關卡學習( 即學習更新模型權重) 之前, 有必要承認上下文學習是有效的 。 也有人強烈說它會繼續贏。
轉換器的精髓是根據序列條件的下一個指示預測器. 給它正確的序列, 你得到了惊人的豐富行為, 而且你不需要觸摸重量。 因此,上下文管理、提示、指示的微調和少數樣本都非常有力。 智能封裝在靜態參數中, 當你向視窗輸入時, 顯示它的能力會大變化。
Cursor最近关于自主編程智能縮放的深度文章就是個很好的例子:模型權重是固定的,真正讓系統运行的是上下文的精细布局——在自主操作的幾小時內,該如何放入,什麼時候概括,如何保持一致性。
OpenClaw 是另一個好例子。 它不會因為特殊的模擬特權而爆炸(這些特權在底部都可供所有人使用), 而是因為它把上下文和工具轉換成非常高效的工作条件:追蹤你正在做的事, 結構中间件, 決定何时重新嵌入, OpenClaw將智慧的「貝殼設計」提升為獨立的学科。
許多研究者懷疑「單獨發表廣告」可能會是一個適當的介面。 看起來像個J 然而,它是轉變器架构的原始產品,不需要再培训,隨著模型進步而自动升級. 模型越來越強大 暗示越來越強大 “ 簡單但原始的” 介面常常會贏, 因為它會直接連結到底部系統, 而不是它 。 目前 LLM的軌道正是如此。
州域空间模型: 上下文的整體版本
當主流工作流程從原始的LLM轉至智慧流通時, 在過去, 這通常會發生在 LLM 要執行一長串离散的工作, 而應用層可以更直接地剪切和压缩聊天歷史時 。
但對於一個有智慧的身體來說 任務可能會吞噬大部份的環境 智慧周期的每一步都取决于第一個序列傳承的背景. 他們通常會在20到100步後失敗, 因為線被打破: 上下文被填充, 一致性被降低。
因此,主要AI實驗室現在投入大量資源(即大型訓練操作)來研發超長背景視窗的模型. 這是一條自然的路,因为它以已有效的方法(在上下文中學習)为基础,也符合本行业转向推理的一般倾向。 最常见的結構是固定的記憶層,即一般注意之間插入的状态空间模型(SSM)和線性注意變體(以下统稱SSM). SSM在上下文中提供一個基本更好的縮放曲線 。
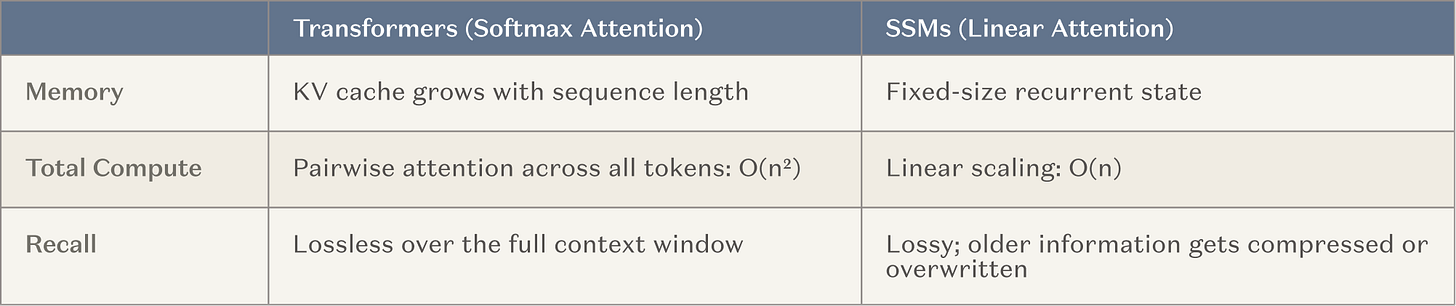
相對於傳統的關注机制
目的是幫助智者把持續步數提升到幾項命令, 如果成功,這對長期智慧來說是一大突破。
你甚至可以把這看成是一種 繼續學習: 雖然模型權重沒有更新, 但引入了一個不需要取代的外部記憶層 。
所以這些非參數方法是真實而有力的. 任何對繼續學習的評估必須從這裡開始 問題不是今天的上下文系統是否有效, 我們看到天花板了嗎。
在上下文中缺少什么
"AGI和前期訓練過的事物,在某种程度上,他們压倒了... 人類不是AGI. 是的,人是有技能的 但他們缺乏很多的知識。 我們靠繼續學習。
如果我做個超聰明的15歲男孩 他什么都不知道 是個好學生 渴望學習 你可以說 做個程序師 去做個醫生 部署本身涉及某種學習、測試和錯誤。 這是一個流程,不是把成品扔出去。 伊利亞·薩茨克維
想像一下這個系統有無限制的儲存空間 世界上最大的文件柜都有很好的索引和无障碍。 它什么都能找到 學到了嗎
沒什麼 它從未被迫做壓縮。
這是我們辯論的核心, 其中引用了伊利亞·薩特斯克維(Ilya Sutskever)先前的一點: LLM本质上是一種壓縮算法. 在訓練中,他們將網路压缩成參數. 壓抑有損害性 是這種損害讓它變得堅強 壓縮迫使模型尋找可以穿過上下文的結構、概括和建構標誌。 所有訓練的硬背樣本的模型不是底部模式的模型. 壓抑在自我學習。
實際上, LLM 在訓練期間如此強大(將原始資料压缩成緊密的、可轉移的表象)的機制正是我們在部署後拒絕讓它們繼續的。 我們在那一刻停止了壓縮 用外部記憶體取代它。
當然,大多數聰明的身體外壳 都以某种方式压缩上下文 但模特兒自己是不是應該學會 直接和大规模地壓縮
尤善分享了這場爭議的例子:數學。 看看費馬定理 許多年來,沒有數學家證明了這一點, 不是因為他們缺乏正確的文學, 數學的知識和最後的答案 相距太遠了。
安德魯·威爾斯在1990年代終于接納了它, 他的憑證依靠成功橋接到兩個不同的數學分支:椭圆曲線和模型形式. Ken Ribet先前證明了這個連結可以自動解開Fermatian定理, 格里高利·佩雷爾曼(英语:Grigori Perelman)可以以庞加萊猜想的證據做同樣的事情。
核心问题是:這些例子是否證明LLM缺乏什麼, 或者說這個故事證明了事實的反面, 所有人類的知識都是可以訓練和重组的數據
問題是實驗性的 答案是不确定的 但我們知道, 有很多類別的問題, 例如:

圖示: 背景學習失敗, 參數學習可能存在的問題類別
更重要的是,上下文學只能用語言表達什麼,而重量可以編碼不能用言語表達的概念。 有些模型太高、太隱形、太深, 例如,在醫療掃瞄中,能分辨良性假瘤和肿瘤的視覺性質的視覺紋理,或者能定義說話人独特節奏的音效微弱波动,都不容易分解成精準的词汇。
語言只能跟他們相似 任何暗示都無法傳達這些事物; 他們活在學習標語的空間 不是言語 不管上下文視窗的增長, 有些知識總是無法在文字中描述, 只能用參數來傳承 。
這可能解釋為什麼顯然的「機器人記起你」功能(如ChatGPT的記憶)常常讓使用者感到不舒服而不是驚訝。 使用者真正想要的不是"記住"而是"力量". 一個將你的行為模式內化的模型可以移植到一個新的場景;一個只記得你歷史的模型不能移植. 「這是你上次回覆這封電子郵件時所寫的」與「我理解你的思考方式。
繼續学习的引言
繼續學習有很多途徑 分界线不是「沒有記憶」壓縮在哪裡發生的這些路徑分布在一個光谱上, 從不壓縮( 纯搜尋、 重量冻结) 到完全內部壓縮( 體重學習、 模型變聰明)。
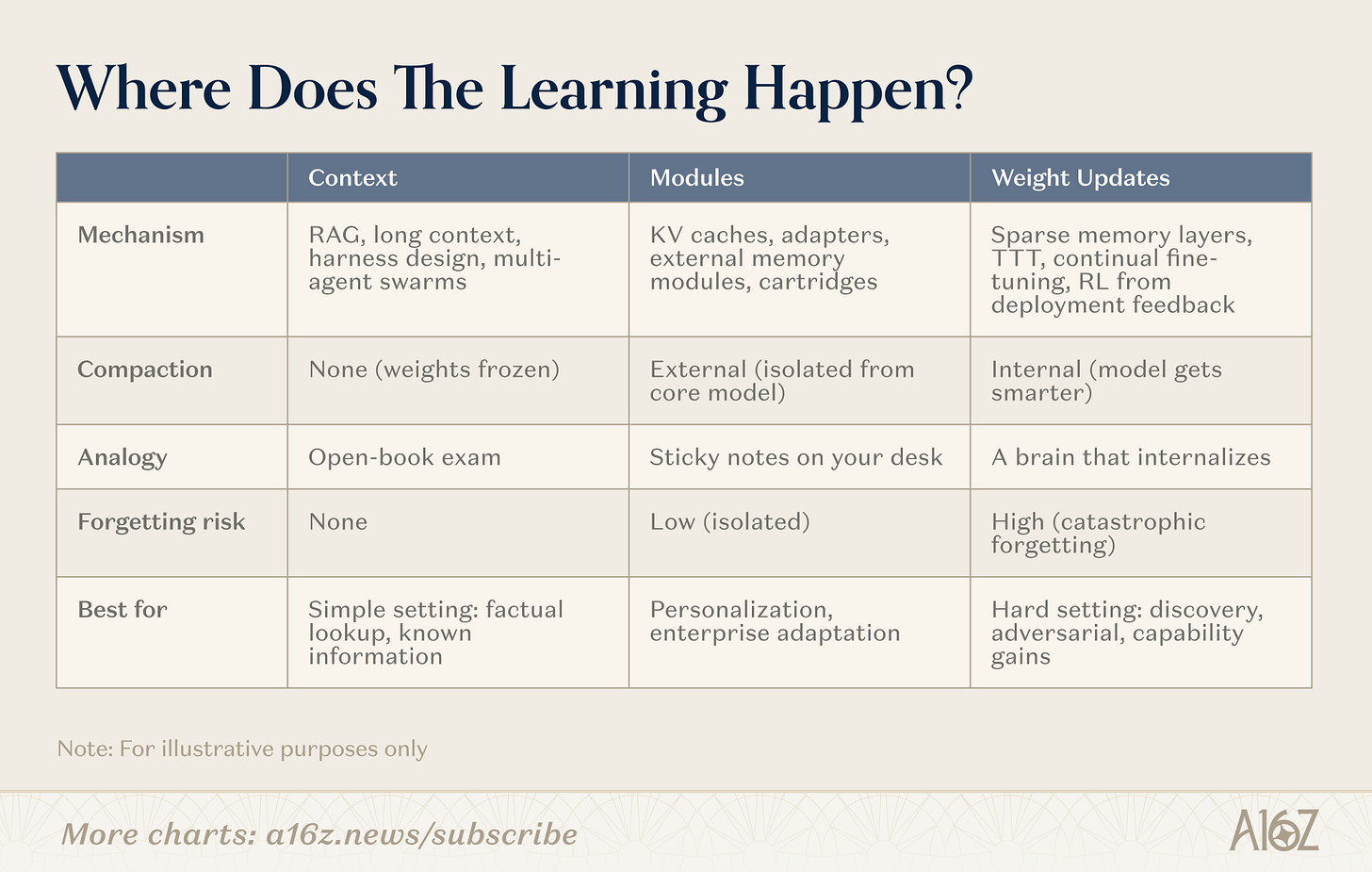
圖示: 繼續學習的三條路徑 - 上下文、模組、權重
背景
在背景的這一端,團隊建造了更多的智能搜索管,智能的身體外壳和提示組織. 這是最成熟的類別: 基礎已被驗證, 限制是深度:上下文的长度。
一個值得注意的新方向:多智能架构, 如果一個單一模型被限制在128K符號視窗內, 一套相协调的智慧體體—— 每個體體都有自己的背景, 每個聰明的體體都在自己的視窗內做上下文學習;系統聚合. Karpath的自動研究計畫與Cursor的網頁瀏覽器, 這是一個完全非參數的方法( 不是變更的權重), 但是它大大提升了上下文系統可以达到的上限 。
模組
在模組化的空間中, 團隊建立嵌入式的知識模組( 壓縮的 KV 缓存、 适配器層、 外部內存儲存) , 以將通用模型專業化, 而不需要再培训 。 8B型號配有適當的模組, 它的吸引力在于它與现存的變形器基礎相容。
重量
研究者們在重點更新末端寻求真正的參數階級學習:只更新相關參數區段的薄記憶層,优化模型的增強學習周期從回馈,以及在推理背景下的壓縮重力測試訓. 這些是最深、最難部署的。
更新參數有許多特定机制。 一些研究方向是:
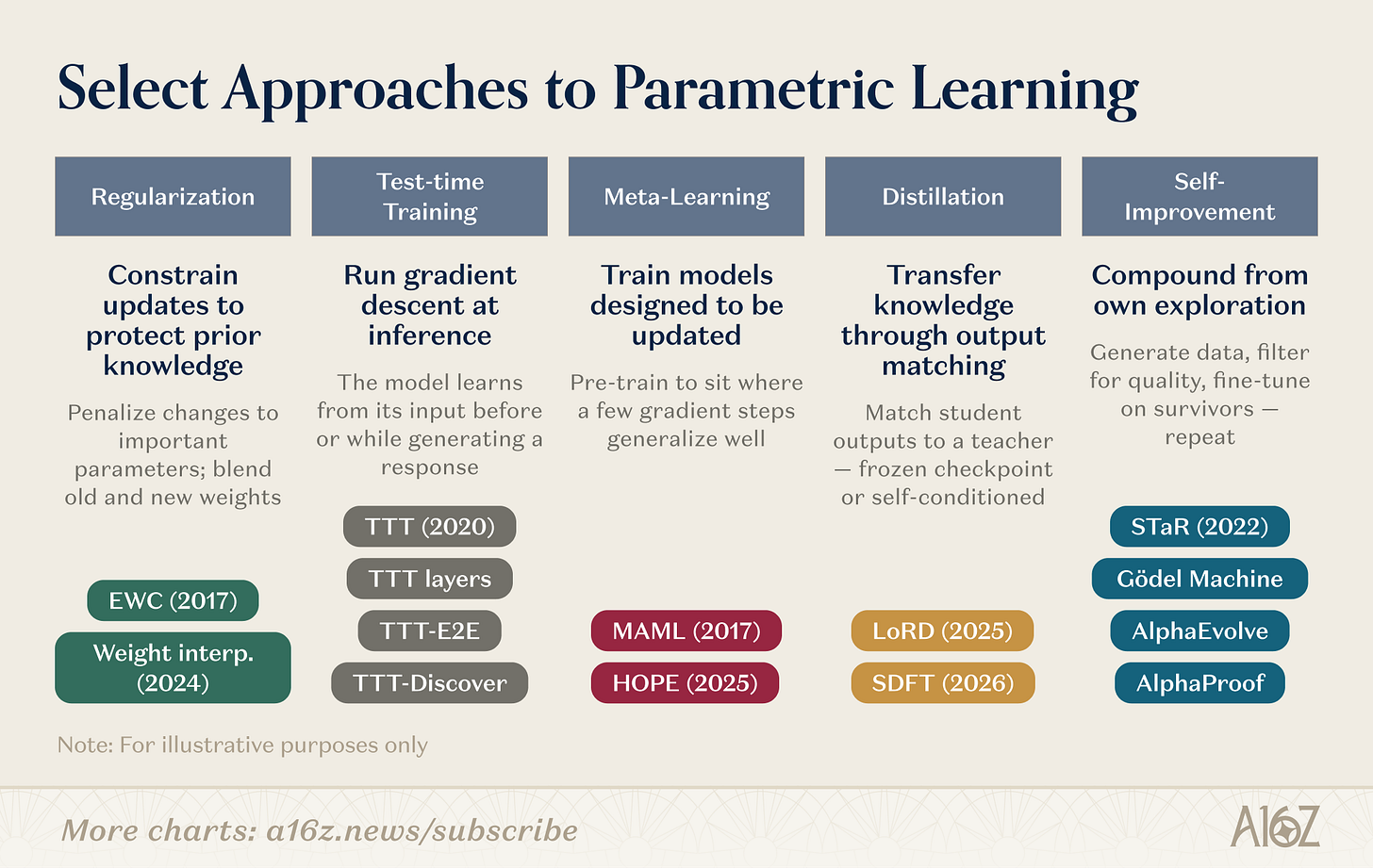
研究方向概述
重心研究包括若干平行的路線。正常化和加权空间方法最古老的:EWC(Kirkpatrick 等人,2017年)根据參數對以前工作的重要性來懲罰參數的變更;重量干涉(Kozal 等人,2024年)在參數空間混合了新老的重量配置,但兩者在大尺度上都很脆弱。
測試中的訓練由 Sun et al. (2020) 建立, 後來發展成建築的原始語言( TTT 層, TTT- E2E, TTT- Discover) , 想法不同: 在測試資料上降低梯度, 并在需要時將新資訊压缩成參數 。
袁學我們能訓練模特學習嗎? 從MAML的數個樣本友好參數的初始化(Finn等人,2017年)到Behrouz等人的嵌入式學習(Nested Learning,2025年),把模型結構成層面优化問題,在生物記憶整合的啟動下,在不同時間尺度上运行快速適應和慢化的模組。
沉淀校對:Soup LORD(Liu 等人, 2025年)讓蒸馏能有效運作, SDFT、Shenfeld等人, 2026年)翻轉了來源, 在專家資訊下使用模型本身的輸出。
遞迴自我改善它在相似的線上運作:STAR(Zelikman 等人,2022年)從自我產生的推理鏈指引推理;AlphaEvolve(DeepMind,2025年)發現數十年來沒有改进過的算法优化;Silver和Sutton的"經驗時代"(2025年)將智慧體的學習定义为永不停歇的經驗流。
這些研究方向正在聚集 TTT-Discover有集成的測試訓練和RL驱动的探索. HOPE將一個慢速的學習周期嵌入到一個單一的结构中. SDFT把蒸馏變成自我改善的基本操作. 列之間的邊界模糊 。 下一代的繼續學習系統可能會將策略结合起来, 許多新創企業都投注在這個科技倉庫的不同層面。
繼續學習
光谱的非參數端最為人所知. 貝殼公司(Letta, mem0 and Subnector)建立層面及腳手架, 外部儲存和RAG基礎( 如 Pinecone, xmemory) 提供搜尋主干. 數據已存在, 許多新創辦公司也開始開始運作。
參數更早 美元更多 公司正在試圖將新的資訊內化, 路徑可以大致分為几种不同的賭注。
部分壓縮: 您可以不用再培训就能學習 。有些團隊正在建立嵌入式知識模組(壓縮的 KV 缓存, 适配器層, 外部內存儲存), 以不移動核心權重而將通用模型专业化 。 通常的論點是,你可以得到有意义的壓縮(不只是取回), 同时把穩定-塑性平衡控制在可控的限度內, 因為學習是隔離的, 而不是分散在參數內。 8B型號配有適當的模組,以配合目標任務中更大型號的性能. 其優點是可移植性:模組可以插入现有的變形器结构。
RL和回應周期:從信號學習。也有人認為部署後學習的訊號已存在於部署周期本身, 其核心想法是,模型應該把每次互動都當做潜在的訓練信號,而不只是要求推理。 這與人類在工作上進展的方式高度相似:工作、得到回應、內化可行。 工程的挑戰是把薄薄的、吵鬧的、有時的對應性的回應 化為穩定的重力更新, 但一個真正從部署中學到的模型 可以產生复合價值。
專注於數據:從正確的訊號中學習。一個相關但與眾不同的賭注是, 以繼續更新: 以更小的梯度, 這與回應環路公司自然相關, 但上游問題是:模型能否學習。
新架构:從底部學習能力。最根本的賭注是變形體架构本身就是個瓶颈, 這裡的辯論是结构性的:如果你想要一個繼續學習的系統,你應該把學習机制嵌入底部的基礎。

图:
所有主要的實驗室也在這些類別中活動。 有些正在探索更好的上下文管理及思考鏈式推理, 有些正在實驗外部記憶模組或睡眠時空計算管, 這個區域已經很早。
為什麼簡單的更新會失敗
更新製作環境中的模型參數可能會引發一系列失敗的模型。

圖示 : 簡單的重量更新模式失敗
工程問題有很多文件 災難的忘卻意味著那些敏感到可以從新數據中學習的模型, 時間分解表示同一套權重被常數規則和變數狀態壓縮,一個更新會損壞另一個. 理論整合失敗, 因為更新事實並沒有傳達到它的推測, 改變只局限于符號序列, 仍無法學習:沒有微小的操作。
第二类问题受到的关注较少。 目前的訓練和部署不僅是工程設施, 打開這個邊界,很多事情會同時出錯。 安全調整可能會不可预测地降低:即使是微調良性資料。
持續更新已造成數據中毒, 可審查性崩溃, 因為一個持續更新的模型是無法用于版本控制、 回归測試或一次性認證的移动目標 。 當使用者互動成參數時, 隱私風險增加, 敏感資訊正在烘焙成形。
這些是開放的問題 不是根本不可能 解決這些問題。
從記憶片段到真正的記憶
Leonard在記憶分裂中的悲劇 并不是他不能運作 他在任何情況下都很聰明 他的悲劇是他永遠無法恢復 每一次經驗都留在外面, 他可以搜索,但不能压缩新知。
當Leonard走過這個自建的迷宮 真相和信念之間的界限開始模糊 他的病不只是對記憶的否定這迫使他重建他的意思讓他既做偵探 又不可靠地說出自己的故事。
今天的AI受到相同的限制。 我們建造了非常強大的检索系統: 更長的上下文視窗, 更聰明的外殼, 协调的多智能群組, 而且它們是有效的。 然而,搜索并不等于學習。 一個能揭開任何事實的系統 不會被迫尋找建築物 它并非被迫普遍化。 讓如此多的訓練 如此嚴重的壓縮 - 把原始資料轉換成可轉換的代表机制 - 正是我們部署時關掉的。
前面的道路可能不是一次突破,而是分层次的系統。 環境學習將繼續是第一道防線, 模块化机制可以解决领域个性化和專業化的中间點。
我們可能需要讓模型在訓練後繼續將經驗压缩成參數。 這意味著在薄薄的建築、元學習目標和自我改进周期方面的進步。 可能也要求重新定义模型的意義:不是一套固定的權重,而是一個包括它的記憶體,更新的算法,以及它從自己的經驗中抽象的能力的演化系統。
檔案柜在增加 但更大的柜子是存檔柜 當模型被部署與訓練時, 從失憶模型到經驗豐富的模型, 否則我們會被困在記憶碎片裡。
原始链接
