
Talkie:剥离现代知识,重新审视 AI 的基础能力

最近,一个名为 Talkie 的复古语言模型在 AI 圈引发了讨论。它的核心特征在于训练数据的极度受限。这个拥有 13B 参数、基于 2600 亿 token 训练的模型,阅读的主要是 1931 年之前的英文文本,包括旧书、报纸、期刊、科学论文、专利和百科全书。官方将其定义为 Vintage Language Model。

在追求更大上下文、更广知识覆盖和实时更新的时代,Talkie 的设定显得反常。
现代大模型通常在现代互联网语料中训练。它们熟悉 Python 代码,熟悉 GitHub issue,熟悉今天的社交媒体语境。而 Talkie 像是一个被关在 1930 年知识边界里的研究对象。它没有见过二战后的世界,也没有真正接触互联网、加密货币或现代软件工程。这种对现代知识的剥离,让它成为一个观察模型基础能力的实验样本。
知识与基础能力的拆解
通过 Talkie,研究者可以观察到一个本质问题:如果一个模型没见过现代世界,它还能从语言结构和上下文示例中学到多少能力?
在现代模型的评估中,逻辑推理往往与资料记忆混在一起。当一个模型答对 Python 代码或现代政治题时,我们很难分清它是真的具备基础能力,还是仅仅因为训练数据里刚好包含了相关的测试题。Talkie 将这两者区分开了:
- 时代错位(Anachronism): 如果它不知道“联合国什么时候成立”,这并不代表其语言理解能力差,因为 1930 年之前并没有联合国的概念。这属于知识缺失,而非能力缺失。
- 模式泛化: 研究者发现,尽管 Talkie 完全没见过 Python,但通过几个 few-shot 示例,它能通过语言结构推导出极简单的代码逻辑。这证明了 Transformer 架构本身具备基础的泛化能力,而不仅是靠记忆。

“双胞胎”对照实验
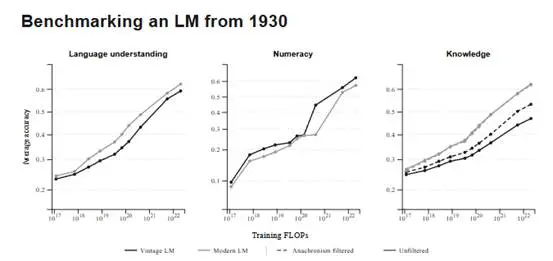
为了验证数据分布的影响,研究团队造了一个架构完全相同的 Modern Twin,区别仅在于后者读的是现代网页数据 FineWeb。
起初,Talkie 在标准测试中全面落后,但这对于一个缺乏 1930 年后知识的模型来说并不公平。有趣的是,当研究者过滤掉那些从 1930 年视角看属于“未来”的问题后,Talkie 与现代模型之间的表现差距缩小了大约一半。
这表明,语言理解的基础能力并不完全依赖现代互联网。高质量的旧报纸、科学期刊和法律文书中,已经蕴含了人类积累的常识模式、逻辑因果和论证规则。模型从这些文本中学到的,是概念如何连接、证据如何支持判断,这些底层逻辑在不同时代具有高度的稳定性。
对设计原则的启发
对于关注可溯源性、验证和推理路径的 AI 系统,Talkie 指出了一个有用的设计原则:模型本体没有必要把每一个新事实都压进参数里。
更稳健的路径应该是:基础模型专注于稳定的语言能力、推理结构和通用模式。这些能力可以从高质量、高密度的历史文本中习得。而最新的事实、技术规范和实时信息,则交给检索系统、知识库和工具调用。
让模型负责理解与拆解,让外部系统负责更新与执行。这比单纯追求更大的预训练语料、让模型成为一个依赖记忆的“背题家”要更接近生产环境的实际需求。
结语
Talkie 的价值在于它划定了一个清晰的实验边界。它提醒行业:不要将“新资料”直接等同于“新能力”,也不要将“知识覆盖面”直接等同于“基础能力”。
AI 的进化逻辑正在发生位移:比起无止境地堆砌网页数据,那些能在精选语料中沉淀出逻辑框架,并擅长调用外部知识库去解决实战问题的系统,更贴近下一阶段的竞争核心。
