
From storeable to solveable: how Bitroot recreates the AI data value layer
Bitroot, on the one hand, provides a high-performance environment along the performance chain through parallelization of EVM with Pipeline BFT, and, on the other hand, connects data, models, algorithms and Agent applications to a clearing network through distributed training, reasoning networks, credible enforcement and AI asset management. In this network, storage is not an isolated module, but rather an infrastructure that determines whether the data are accurate, whether the model is re-emergible, whether the calculus is closed and whether the contributor is able to sustain gains。

Source: Bitroot
Storage is not a cost centre, it's Bitroot AI Stack's value distribution system
Many of the teams realized that the layer of storage should have been chosen more carefully in the first half of the year. The data were not lost and the service was not stopped, but the problem emerged in another way: the training data in the archive were being retrieved slowly, the tails of the hot-spot vector search were shaking from milliseconds to seconds, and no one could tell which version of the training data the model was using when it had to be replayed. At this point, it is no longer an expansion, but three more difficult questions: who can prove that data are always available, who is responsible for the version and who pays for the long-term costs。
UNDERSTANDING STORAGE AS MOVING FILES FROM A CENTRAL CLOUD TO A NETWORK UNDER THE CHAIN WILL HOLD UP IN THE NFT METADATA AGE. ONCE THE OPERATION EXTENDS TO AI TRAINING LANGUAGE, MODEL WEIGHTS AND VECTOR INDICES, THIS APPROACH WILL QUICKLY FAIL。
MOST OF THE TEAMS HAVE SO FAR CONSIDERED STORAGE TO BE THE BEST LOGISTICAL COST, WHICH IS PRECISELY THE PLACE WHERE IT IS MOST UNDERVALUED AND THE EASIEST TO CHOOSE: IN THE AI CHAIN, IT IS ACTUALLY THE VALUE DISTRIBUTION LAYER THAT DETERMINES WHO HAS THE DATA AND WHO GETS THE PROCEEDS. THIS ARTICLE ANSWERS ONLY ONE QUESTION: IN THE CONTEXT OF AI INTEGRATION WITH THE PUBLIC CHAIN, HOW TO CONSTRUCT A VERIFIABLE, MANAGEABLE AND SUSTAINABLE DISTRIBUTED STORAGE PROGRAMME. THE CAPABILITY BOUNDARIES OF THE THREE DOMINANT PARADIGMS ARE BROKEN DOWN BELOW, AND THE PARTICULAR DIFFICULTY OF AI DATA IS EXPLAINED, AND FINALLY A FIVE-TIERED ARCHITECTURE AND A PHASED THRESHOLD FOR ENTRY. THE JUDGEMENT IS BASED PRIMARILY ON OFFICIAL PROTOCOL DOCUMENTS AND, TO THE EXTENT POSSIBLE, VERIFIABLE INFORMATION。
In the case of Bitroot, the more accurate location of the storage is the value distribution base of AI Stack. Bitroot, on the one hand, provides a high-performance environment along the performance chain through parallelization of EVM with Pipeline BFT, and, on the other hand, connects data, models, algorithms and Agent applications to a clearing network through distributed training, reasoning networks, credible enforcement and AI asset management. In this network, storage is not an isolated module, but rather an infrastructure that determines whether the data are accurate, whether the model is re-emergible, whether the calculus is closed and whether the contributor is able to sustain gains。

IT'S ALL CHAINED UP AND CENTERED. IT'S NOT WORKING IN AI
IN THE PAST FEW YEARS, STORAGE PROBLEMS HAVE OFTEN BEEN REDUCED TO ONE OR THE OTHER: FULL CHAIN OR CENTRALIZATION. BOTH ROADS ARE UNSUSTAINABLE IN THE AI SCENE。
Full chain pressure is specific. Training data, model weights, reasoning logs, vector indexes are generally high-volume and high-frequency updates, and even if they are sliced and chained, they crash into both the vomiting ceiling and the cost curve. Full centreization runs fast, but the trust base on which validation, traceability, data sovereignty and cross-subject collaboration depend is fragile and cannot be sustained once multiple accounts are divided and rights are involved。
MORE CRUCIALLY, AI CHANGED STORAGE FROM A COST ITEM TO A PRODUCTION FACTOR. THE MANAGEMENT OF THE DATA VERSION DETERMINES WHO WILL TAKE THE INITIATIVE FOR THE ITERATIVE MODEL; WHETHER IT CAN BE DEMONSTRATED THAT DATA ARE AVAILABLE AND HAVE A DIRECT IMPACT ON THE PRIORITY OF COMPUTING AND CLEARING; AND THE ABILITY TO AUTOMATE DATA IS A MATTER OF WHETHER A TEAM CAN CREATE LONG-TERM ECOLOGICAL INCENTIVES. THE RESERVOIR IS NO LONGER A LOGISTICS SYSTEM BUT A VALUE DISTRIBUTION SYSTEM。
So a qualified storage structure must answer four questions at once: Whether the data are real and desirable, whether the data are traceable to the version of the model, whether the competencies and benefits are manageable, and whether the system balances costs and performance over time。

Bitroot entry point: let AI data move from "storable" to "liquidable"
That's where Bitroot needs to be filled. As a high-performance Parrallel EVM public link for the AI scene, Bitroot’s storage narrative should not stop at “where the data are placed”, but rather answer “how the data are proven, how they are called, how they participate in the split”. Training materials, model weights, vector indexes and reasoning logs can be left in distributed storage layers more suitable for larger objects, but their Hashi commitments, version relationships, permission strategies, call records and revenue events require unified chain evidence on Bitroot。
From this point of view, Bitroot's high-input and low-deliberate events are not just service DeFi transactions, but service more nuanced and high-frequency governance events in AI Stack: The updating of the data sets will be anchored, the model version will be registered, AI Agent calls will be settled, search results will be arbitrated and storage node availability will be continuously challenged and rewarded. Only if the bottom chain is able to take over these events will AI data assets not be locked in a centralized database or turned into unaccountable black boxes under the chain。

Three dominant paradigms, none of which can penetrate the scene alone
The competition for distributed storage has never been the most advanced, but the most appropriate in your data structure。
THE CONTENT SEARCH NETWORK SOLVES WHETHER IT'S THAT DATA OR NOT, AND NOBODY GUARANTEES IT'S ONLINE. ACCORDING TO THE IPFS OFFICIAL DOCUMENT, THE CID IS BASED ON THE HASHI IDENTITY OF CONTENT AND DOES NOT DEPEND ON LOCATION: THE SAME CONTENT PRODUCES THE SAME CID UNDER THE SAME CODED SETTINGS, AND THE CID CHANGES AS LONG AS THE CONTENT CHANGES BYTE. THIS FEATURE MAKES IT NATURAL FOR COMPLETENESS VERIFICATION, WEIGHTING AND CROSS-SYSTEM REFERENCE, AND IS THE BOTTOM CAPACITY FOR DATA VALIDATION. BUT THE LOCATION OF THE CONTENT IS NOT EQUIVALENT TO BEING ECONOMICALLY SUSTAINABLE, AND CID ANSWERS IDENTITY QUESTIONS AND DOES NOT ANSWER WHO ENSURES THAT IT REMAINS ON LINE. THE FIRST PIT THAT MANY TEAMS STEP ON IS HERE: TECHNICALLY, CID, AND OPERATIONALLY, NO COMMITMENT TO USABILITY。
Storage of market networks is the use of economic mechanisms to buy the availability of time dimensions. According to Filecoin documentation, the network creates a mechanism for storage commitments plus continuous certification through Proof-of-Replication and Proof-of-Spacetime. PoRep proved that this unique copy was in fact in the initial envelope, and PoSt repeatedly proved that it was in the follow-up cycle. WindowsPost usually organizes the certificate cycle on a 24-hour basis, cutting into multiple 30-minute proof windows, and if the repository does not submit valid proof in the window, it triggers collateral forfeiture and reduction in storage capacity. In this system, usability is a continuous test, not a one-off commitment after a contract. This contractual, auditable model is suitable for medium- and long-term archiving, backup and data markets, but it is more like a proven long-term warehousing rather than a natural low-delayed online service that puts high-frequency online queries directly under pressure and experiences of tail delay。
The permanent storage network takes another route, with one-off payments for history. According to the Arweave Agreement and the Yellow Book information, a portion of the upload costs will go into the storage endowment pool to cover long-term storage incentives and place long-term sustainability in a billing model rather than relying on subsequent continuation practices. It is suitable for historical archives, key documents, copyrighted material, and non-removable records. Shortboards are also clear: permanency does not automatically amount to high and low delays, and in practice there is still a need to fold caches, gateways or near-line index layers to satisfy the real-time experience on the side of the user。
In addition to these three basic paradigms, two common combinations of engineering are worth weighing. One is a mixture of data availability layers plus object storage, and more standardized data dissemination and proof of availability at the cost of cross-synthesis and complex interface governance. The other is cloud-plus synergetic, low delays and better disaster tolerance, but cost governance and coherent management are more difficult to reach。
Either way, an agreement to eat all the scenes won't work. The effective method is to be grouped by data type: to remove the persistence, retrieval time and compliance, to match the capability layer separately, and to be organized in a uniform manner by chain anchoring and governance layer。
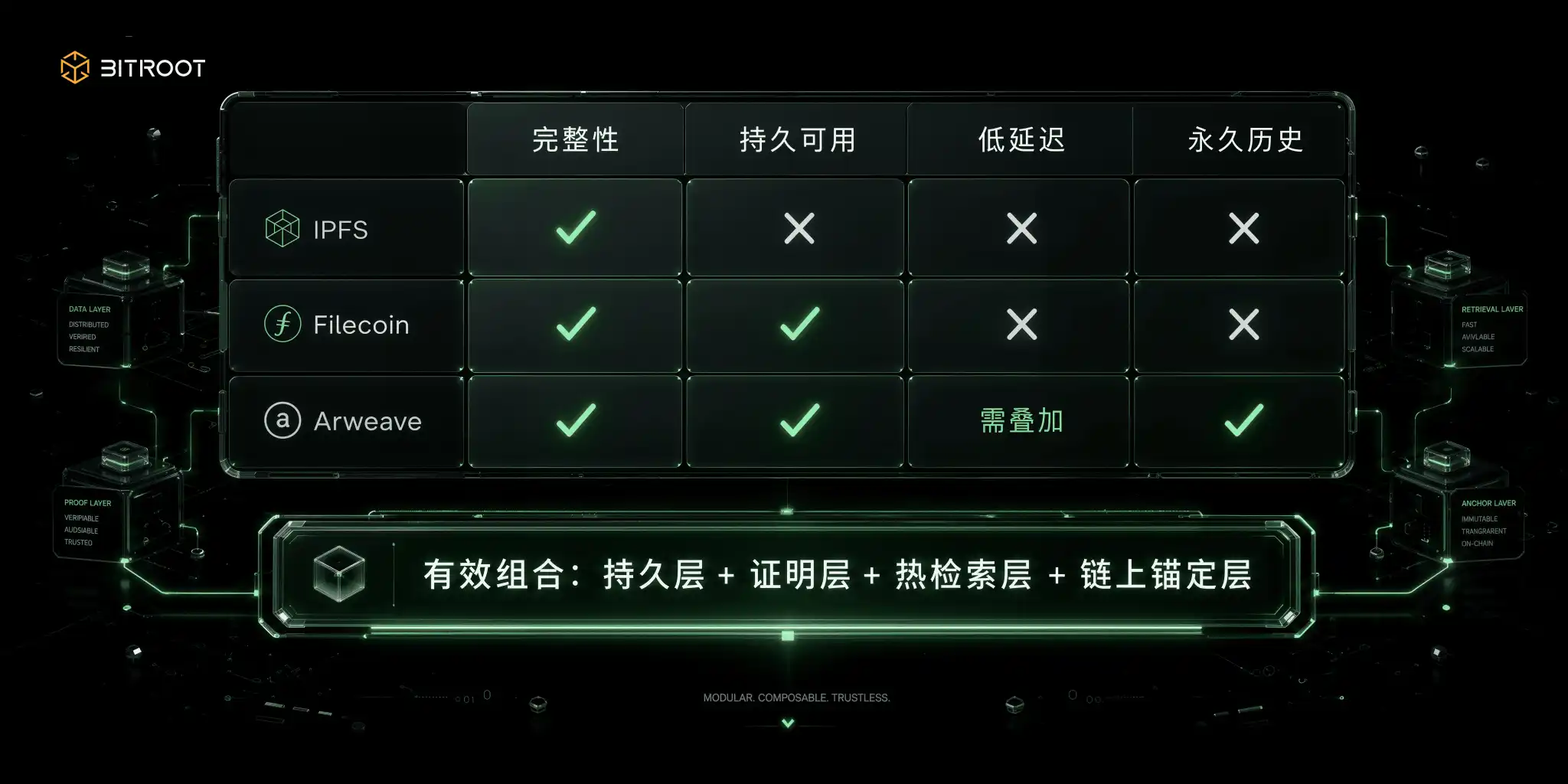
Bitroot ' s choice of space should also be based on this combination logic: rather than replacing each other with IPFS, Filecoin, Arweave or objects, it places them in different layers of responsibility. Content addresses are used for data identity and integrity, storage certificates are used for long-term availability, permanent layers are used for key history and documents, thermal search layers are used for AI application experience, and the upper Bitroot chain is used for uniform carrying version anchoring, authority policy, call settlement and dispute resolution. In other words, Bitroot does not need to be a physical repository of all data, but rather a reliable account of the AI data flow。
AI STORAGE DIFFICULTIES, NOT FILES, BUT RUNNING PRODUCTION LINKS
IN AI SETTINGS, STORAGE OBJECTS ARE DIVIDED INTO AT LEAST FOUR CATEGORIES: TRAINING DATA, MODEL WEIGHTS, VECTOR INDEXES, REASONING LOGS. THE LIFE CYCLE, MODE OF ACCESS AND VALUE DENSITY OF THE FOUR CATEGORIES OF SUBJECTS ARE COMPLETELY DIFFERENT, WITH A SET OF STRATEGIES TO MANAGE, SHORT-TERM SAVINGS, AND A LONG-TERM PERIOD OF UNCONTROLLABLE GOVERNANCE。
The problem with training data is not in capacity and drifts in the version. Many teams equate training data issues with TB-grade storage costs, and what is more problematic is drifting: as long as cleaning rules, sample selection thresholds or calibration changes, model behaviour changes, and without binding data and model versions, off-line assessment is difficult to verify. According to MLFlow ' s model and data tracking practice, the training operation and data version binding are prerequisites for the replication of the experiment. This principle remains valid on the chain: original data need not be chained in full, but release commitments, key summaries and source fingerprints must be chained. At least three markers will have to be attached to the project, the data version, the training operation, the model version, and, without one, the problem on the line will degenerate from evidence to guess。
the issue of model weights is often not whether they can be downloaded, but who will call the boundary. a model enters production, usually going through a few states of greyscale, primary use, rollback and decommissioning, without a standardized system of registration and authorization, and online calls are an unauditable black box. a mature model registration centre records bloodlines, version aliases, signature constraints and audit labels. for the chain system, the model version should not be just a document, hashi, but should be tied together with authority strategies, distribution of proceeds and liability boundaries。
The difficulty of vector indexing is concentrated in one place: consistency after the heat and cold layers. There's an inherent contradiction between vector search, low delay and low cost fighting each other: Thermosphere is dependent on memory or high performance index services to ensure an online response and cold layer is dependent on object storage to contain long-term costs. Without a unified metadata and synchronized strategy, the two layers are quickly split and the problem of the same query returning the semantic results at different nodes. So the vector system has to support two things, the index construction process can be tracked and the thermosphere index version can be reconciled with the cold master data, which is exactly what the lateral text can validate the search。
It is difficult to establish a log of reasoning in which privacy, auditing and compliance are established. It is both a security audit material and a source of privacy risk: full and explicit retention poses a compliance risk, completely unsustainable and loss of accident revolving capability. The feasible approach is three layers of superstition, dissensitized content storage, Hashi ' s commitment to go up chain and access is subject to audit authorization to achieve non-removable and revocable hierarchies。
In Bitroot 's AI Stack, these four categories can correspond to four types of governance actions: training data for anchoring and source registration, model weighting for asset registration and authorization to call, vector indexing for heat and cold stratification and consistency, reasoning logs for dissensitive storage and audit commitments. They do not need to be chained in the same way, but they need to form unified asset ID, version spectrum and call events on Bitroot. This makes it possible to form a reusable commercial closed circle between data assets, model assets and Agent applications。

But it's the bottom line. It's the bottom line
STORAGE COMMITMENTS WITHOUT PROOF OF USABILITY ARE ESSENTIALLY EQUIVALENT TO COMMITMENTS IN THE PRODUCTION ENVIRONMENT. DISTRIBUTIONAL STORAGE INVOLVES PRODUCTION IN AT LEAST THREE WAYS: INTEGRITY, USABILITY, CONDUCT, AUDITABILITY, AND, ONCE THE AI SEARCH SCENE IS IN PLACE, MORE DIFFICULT TO RETRIEVE TOGETHER。
Completeness is evidenced by content location plus Merkle commitment. Content location ensures that the data fingerprints are stable and Merkle promises to be partially verifiable. The point of the project is that you can prove a subset of the object in a fraction, without having to read it in full. For large model weights, large language and multimedia data, this directly determines the cost of validation。
Availability is evidenced by challenge mechanisms and sample validation. The Filecoin practice has shown that usability is not oral SLA, but is proof on the chain of periodic challenges that abstracted generic structures are a set of passive spot checks, active inspections, and failure penalties: node must respond to the challenge in the prescribed window, otherwise the penalty is triggered or the weight is reduced. The same thinking goes further in terms of data availability. According to Celesti ' s data availability sample design, the data is expanded from kxk to 2kx2k matrix, with light nodes accumulating through multiple-wheel random sampling and probability, without having to download the whole data to build high probability confidence in usability. This is an inspiration for the AI scenario to migrate: not all availability needs to be fully validated by downloading, and statistical confirmation is more realistic in a large system。
The conduct was subject to chain anchoring and incident marks. The hardest thing about storage systems is behavior: who uploads what, who changes strategy, who triggers migration, who uses sensitive models. If these acts do not converge into a single stream of events, they will revert to the point where there is a dispute. Rather than placing all the details in the chain, the governance is holding the smallest, definitive and verifiable collection of evidence at the time of the dispute。
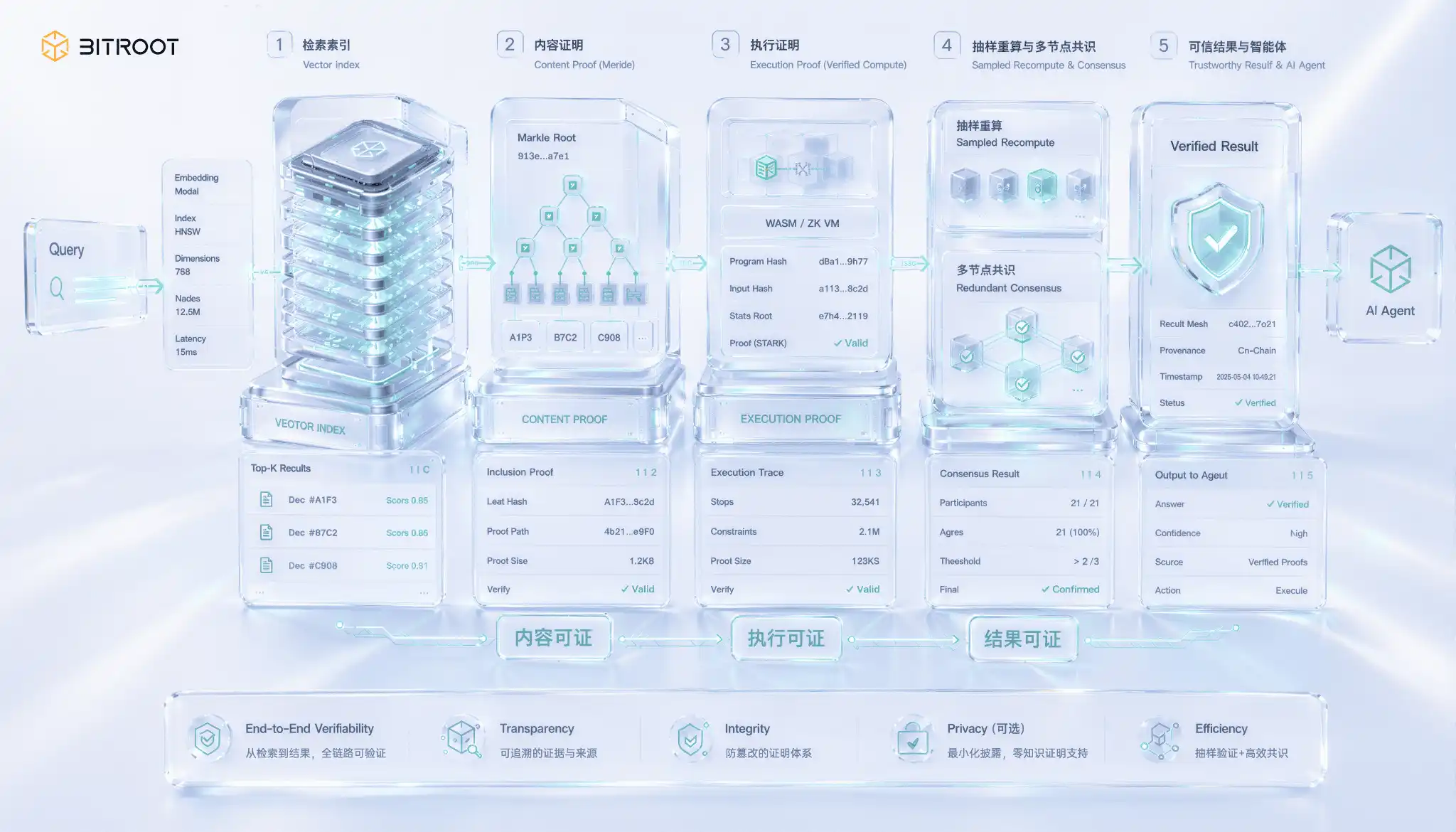
The search certificate is the unique and most difficult one of the AI scenes, and the problem arises in an easily ignored gap: returning the result is not the same as returning the right result. A vector search node is perfectly capable of taking an out-of-date index, or even skipping the real nearest neighbor, and going back to one of your seemingly reasonable top-k, and you can't see the value of the return alone. Semanticly retrieved outputs are not self-proven in themselves, and errors are not reported, but only quietly take back quality and model performance. When the results are to be used for settlement, authorization or chain decision-making, this gap escalates from quality to trust。
Dismantling the searchable is, in fact, a three-tiered guarantee of change. The first level is evidence that the vector of return does belong to a promised version of the index, by establishing a data structure for the index, by committing Merkle to chaining the index to its roots and returning the results with an encapsulation certificate to ensure that nodes are not fabricated or tampered with data. The second tier was the execution of a certificate that the query had indeed run on that promised version, rather than on a privately modified index, which required that the query process be included in a verifiable calculation. The third level is the most difficult to prove, with results, that the returned top-k is indeed the most recent at a given measure, rather than the missing of the nearest neighbour, which is essentially proof of the propriety of the recent neighbour search。
Strict results on the scale of production in terms of high-dimensional proximity to the nearest neighbour are still at the forefront of the issue, and while passwords such as zero proof of knowledge are advancing, the cost of high-dimensional vector computing is far from being proven for large-scale online use. Practical engineering solutions are bottom-up rather than step-by-step: first, to commit index versions and building parameters to chaining them to ensure traceability; then to recalculate a sample of queries, to rerun the search on a pro rata basis to a credible copy and compare the results with statistical confidence instead of article-by-article proof; to allow multiple independent nodes to overload, to reach consensus on the return result and to raise the cost of cheating a single point; and only when there is disagreement over or consensus will the full recalculation of the search be upgraded to a chain decision. The line goes hand in hand with the idea of prioritizing the sample in the certificate of usability: in large-scale systems, statistical confirmation and the escalation of disputes tend to be more readily available than is strictly demonstrated by article by article。
For Bitroot, a verifiable search is not an isolated storage function, but is part of a credible AIAgent execution. If you rely on the external knowledge base, model weight or vector index for decision-making, the system has to answer at least three things: It reads the version of the data, calls the version of the model and returns the result from the registered index version. Bitroot can compress this evidence into a chain of verifiable events, allowing Agent to move from "looks smart" to "retroactive, controversial, solvency"。

The real problem with the selection: not the choice, but the grouping
Many programme reviews failed because the issues were wrong. The correct formulation is not whether we want to use an agreement, but what our data mix is, what the target indicators are, and what the constraints are. It is recommended that four moves be followed。
Data asset counts first. At least distinguish between status data, object data, retrieval data, audit data and make the inventory template a fixed field, with a minimum of eight: data type, increasing volume, peak combined distribution, reading and writing ratio, retention cycle, compliance level, target time extension, cost cap. Once the fields are unified, cross-team selection communication is much faster。
REDEFINITION OF SERVICE LEVEL TARGETS. THE P95/P99 TIME EXTENSION, RECOVERY TIME RRO, RECOVERY POINT RPO, AVAILABILITY TARGET, SINGLE TB COST CAP IS WRITTEN TO DIE, OTHERWISE THERE ARE NO RULERS FOR ALL SUBSEQUENT DISCUSSIONS。
Then build a capability map. The categories of permanent storage, cyclical proof of usability, low delay in retrieval and access to governance are shown to different layers of technology rather than to a single layer。
FINALIZE MIGRATION THRESHOLDS. WHAT DATA ALLOWS FOR CENTRALIZATION OF THE TRANSITION, WHAT INDICATORS TRIGGER MIGRATION, AND WHEN THE DECENTRIZATION REPLACEMENT MUST BE COMPLETED. ONE PRACTICAL APPROACH IS TO SET A DOUBLE THRESHOLD: SINGLE TB COSTS OVER-BUDGET FOR TWO CONSECUTIVE STATISTICAL CYCLES, OR P95, TWO CONSECUTIVE WEEKS OVER-TARGET, AUTOMATICALLY TRIGGERING STRUCTURAL MIGRATION REVIEWS. THERE IS NO GOVERNANCE WITHOUT THRESHOLDS AND THE TRANSITION PERIOD BECOMES PERMANENT。
Landing programme: a five-tiered structure, with a living, desirable and manageable closure
The value of the architecture is not in the order of magnitude, but in the form of a verifiable loop. Based on the previous framework, the programme is condensed into five layers: chain anchoring layer, object storage layer, index search layer, serviceability certificate layer, key access layer. The objective is to turn verifiable into default capacity, high performance into configuration, and governance into an enforceable process。
In Bitroot, these five layers can be further understood as an AI Stack storage governance module: Parallel EVM provides high-frequency anchoring and clearing capability, Pipeline BFT provides low-delayed certainty, distributed storage network to large objects and historical data, index search layer service AI Agent and application call, availability certificate layer translates node service quality into credit and reward, and key access layer links user sovereignty, privacy protection and model commercialization authorization。
The chain anchor is kept in the smallest state of necessity: data commitment, version fingerprints, permission strategy summary, settlement event. The big object is not chained up to prove its existence and correct version. It preserves the probability of the chain and does not allow the stale to be dragged down by big documents。
In Bitroot’s framework, the chain anchor is not just a “record of Hashi”, but a common entry point for AI asset registration, authority governance, distribution of proceeds and dispute decisions. Data sets, model weights, vector indexes and reasoning logs can all be stored under the chain in the most appropriate manner, but their version commitment, authorized status, call records and attribution of proceeds need to enter the Bitroot chain. So, the chain storage is responsible for carrying the load, and Bitroot is responsible for carrying the trust。
The object storage layer carries real data, using a mixed strategy of decodering and copying: high-value, low-frequency-accessed objects are subject to error and medium-value, high-frequency-visited objects are subject to search efficiency. This strategy is not static configuration and is adjusted to visit heat and business class dynamics。
The index search layer incorporates metadata and vector indexes into the unified catalogue, thermosphere is connected to online search, and the cold layer is archived and reconstructed. All index versions are required to register source versions and build parameters, otherwise the index drift cannot be traced。
Quantification of node behaviour in the certificate of availability layer. The success rate in responding to the challenge, the response time frame and the rehabilitation success rate are all rated in terms of credibility, rating and incentive allocation tied to avoid rewarding capacity and availability。
Key access control and compliance. High-sensitivity data are classified with a key and time-barred authorization, reasoning logs are de-sensitive stored with audit releasing, and model calls are subject to revocation. The permission operation itself also leaves a mark to prevent configuration drift。
The five layers are closed at the implementation level, not a single-direction water line: After data access, slices are encoded into the object layer to create index after writing and anchor the chain; online query the thermosphere is detached, with less than a hit back to the cold layer; return the results while triggering completeness verification and authorization verification, and key behaviour enters settlement and audit. The real value of this chain is that four questions can be answered at any node or moment: Where the data came from, what the current version was, who was entitled to access and whether the system could prove its availability。
This is also the key reason why Bitroot is fit for AI storage governance. The calls for AI Agent, the switching of model versions, changes in data authorization, disputes over search results are not low-frequency backstage operations, but are chain events that continue with application growth. If the bottom chain fails to provide sufficiently low confirmation of delays and sufficiently high throughput, storage governance is eventually forced to return to the bottom of the chain and to manual reconciliation. Parallel EVM from Bitroot and Pipeline BFT are not just worth higher TPS, but allow these high frequency governance events to be anchored, settled and pursued in real time。

Who's gonna pay for it: let us use us, not the capacity, to determine the return
In order for storage to run in the long term, incentives must be readily available, not stacked capacity. Only the amount of capacity is rewarded, which is equivalent to a disguised incentive to pile hard drives and light services. This point has been amended by the Filecoin mechanism: it introduces the concept of quality-adjusted power, allowing the acceptance of real storage orders, particularly of valid and validated orders, i.e. the minimum measurement unit of storage space, to obtain higher weights in the measurement of power, thereby tilting the incentive towards the capacity to provide the real service, rather than the empty capacity of a mere envelope. This idea deserves any self-building incentive。
Puts it into an enforceable incentive function that counts at least four dimensions simultaneously and clarifies the respective weight logic. The capacity determines the base share and answers how much space you promised. Online rates and response times determine the service quality factor and answer whether this space is really desirable when needed, which should have a higher weight, otherwise usability becomes a slogan. The success rate of recovery of data determines the credibility of the disaster, and the ability to rebuild a copy of the response after the node has dropped directly relates to the survival of long-term data. Data value density determines demand side by side, with differential multipliers for high-value datasets and high-demand models, giving higher returns to scarce and frequently called data. Incentives should be given to a proven service rather than the declared capacity。
Positive incentives alone are not enough, binding pledges, penalties, arbitrations are in place at the same time, and a bottom-up variant is to be met: the expected benefits of cheating must be lower than the expected costs of being punished, otherwise any certification mechanism will be bypassed by economic rationality. The pledge node is the cost of a pledge of usability, the size of which should be proportional to the calculus and data value of the undertaking; in the design of Filecoin, the repository is required to pay the pre-mortgage with the promised calculus, triggers the failure fee once the wire is dropped in the demonstration window, and the permanent relinquishment of the sector triggers a heavier termination penalty, the meaning of which is to discriminate between short-term breakouts and malicious withdrawals. The arbitration is based on a chain of evidence-driven disputes: When users claim that data are not available and nodes claim normal service, challenge recording, sampling certificates and incident logs form a machine-readable basis for adjudication, compressing disputes requiring manual intervention into a verifiable chain determination。
THE AI SCENARIO ALSO HAS A MUCH MORE DIFFICULT GOVERNANCE LAYER ON IT: HOW CAN THE TRIPARTITE GAINS BE BROKEN? A MODEL THAT HAS BEEN REPEATEDLY USED, BACKED BY LANGUAGE FROM DATA CONTRIBUTORS, TRAINING OF MODEL CONTRIBUTORS, HOSTING OF STORAGE NODES, ALL OF WHICH CONTRIBUTE TO THE ULTIMATE CALL VALUE BUT ARE DIFFICULT TO OBSERVE DIRECTLY. IT IS FEASIBLE TO BASE VALUE ATTRIBUTION ON MEASURABLE CHAIN EVENTS: SUB-COUNTING AND AUTOMATIC SETTLEMENT OF DATA AND MODELS ARE TIED TO EACH CALL BY MEANS OF A VERSION OF FINGERPRINTS AND BLOOD LINKS, THEN AUTOMATICALLY SPLIT IN PROPORTION TO THE PRE-WRITTEN PROGRAMMABLE PORTION OF THE ACCOUNT TO AVOID EX POST FACTO RIPPLETION. THIS IS ACCOMPANIED BY A BLACKLIST AND FORFEITURE MECHANISM, WHICH SEIZES MORTGAGES AND FREEZES SUBSEQUENT PROCEEDS ONCE ARBITRATED AGAINST MALICIOUS DATA UPLOADING, COPYRIGHT INFRINGEMENT AND MODEL THEFT. OTHERWISE, THERE WILL BE A COUNTER-INTUITIVE RESULT: THE MORE SUCCESSFUL THE ASSETIZATION, THE MORE DISPUTES ARE DIVIDED AND VESTED, AND IT IS PRECISELY ECOLOGICAL TRUST ITSELF THAT ULTIMATELY COLLAPSES。
Compliance is not a patch, but a binding structure period: The security baseline is end-to-end encryption, layered key management and cycle rotation, superimproving Hashi and Merkle promise to ensure that downloads can be validated and multiple copies and decoded combined to cover failure recovery; privacy side-by-side minimal access controls based on data level, supporting the withdrawal of authorizations, one-time and time-barred authorizations, leaving a mark on critical access and operations as a whole link to facilitate audit backplay. Compliance is also the most vulnerable and costly link: Data localization and cross-domain transmission strategies need to be configured, with standard process interfaces for deletion, access, and audit requests; the most difficult is not to tamper with natural conflicts that can be removed, with the feasible solution being encrypted wiping and indexing invalids: destruction of the key renders the secret text unrecoverable, rendering the data unretrievable, and satisfying the deletion claim by keeping records on the chain. There are three stages of the threshold from pilot to production: first, a minimum credible closed loop is established, object storage, chain anchoring, completeness verification and basic controls are stabilized, acceptance is available, reading and writing success rate, anchoring is aligned with object version, failure recovery can be performed; then AI assetization and indexing governance is implemented, datasets and model asset management is introduced, version spectrum, vector indexing heat and cold layer, model authorization to call and training data sources is registered, receiving and inspection training is traceable, model rerollable audit, heat layer compliance, index reconstruction impact is controlled; lastly, retrieval and automated governance is validated, challenge certification is introduced, strategy migration and reward automation is introduced, available certificate coverage is checked, risk disposal is delayed, unit cost decreases, strategic changes are tracked back to roll. The indicator system is a strategic system and not a presentation report. The storage programme collapses into a purely cost centre if only technical items are written, without business results; recommendations are made in three tiers: the underlying technical indicators (availability, P95/P99 time delay, throughput, RTO/RPO, error rate) answer the health of the system, AI the specific indicators (training data traceability rate, model recoverability rate, reasoning validation coverage, index consistency) answer the quality of the model, the operational outcome indicators (data supply growth, reduced call costs, nodal activity, asset trading scale) answer the value of the system, and there is a mapping relationship between the three layers, the real use of the indicator being a strategically well-adjusted input rather than a presentation statement. The five most common failure points are largely circumvented in advance: storage without version governance, data are not representative of availability, availability or recurrence; capacity alone is not supported by proof of availability, and rewards are provided by volume to induce stack capacity light; heat and cold layers are done but no synchronous strategies are performed, and index versions are not closed; compliance strategies are followed by greater costs of privileges, logbooks, dissensitization, removal of late responses; transition structures do not exit and centralization is a reasonable path, but missing migration thresholds allow transitions to fix and depart from their original intent。
Full closed ring for Bitroot: from data, models to AI Agent
In this ring, Bitroot can turn every key act of the AI asset into a settlement event: Dataset registration, model release, vector index reconstruction, AI Agent call, log anchoring of reasoning, delegation of authority and revocation, dispute challenge and arbitration results. The chain does not need to contain all the data, but the smallest evidence of these acts. Only in this way will the value relationship between data, models, algorithms and applications go beyond verbal commitments to programmable sub-accounts and auditable governance。
To place this mechanism in the operational and ecological expansion of Bitroot, storage incentives should not be designed as separate hardware subsidies, but should be part of the AI Stack flow: Data contributors receive benefits from training or transfer of data, model contributors receive benefits from model services, storage and retrieval nodes receive benefits from continuous availability and low delays in service, certification and challenge nodes are rewarded for discovering non-availability, indexing drift or permission anomalies. In this way, Bitroot’s economic system rewards not by uploading, but by “continuously proving useful”。
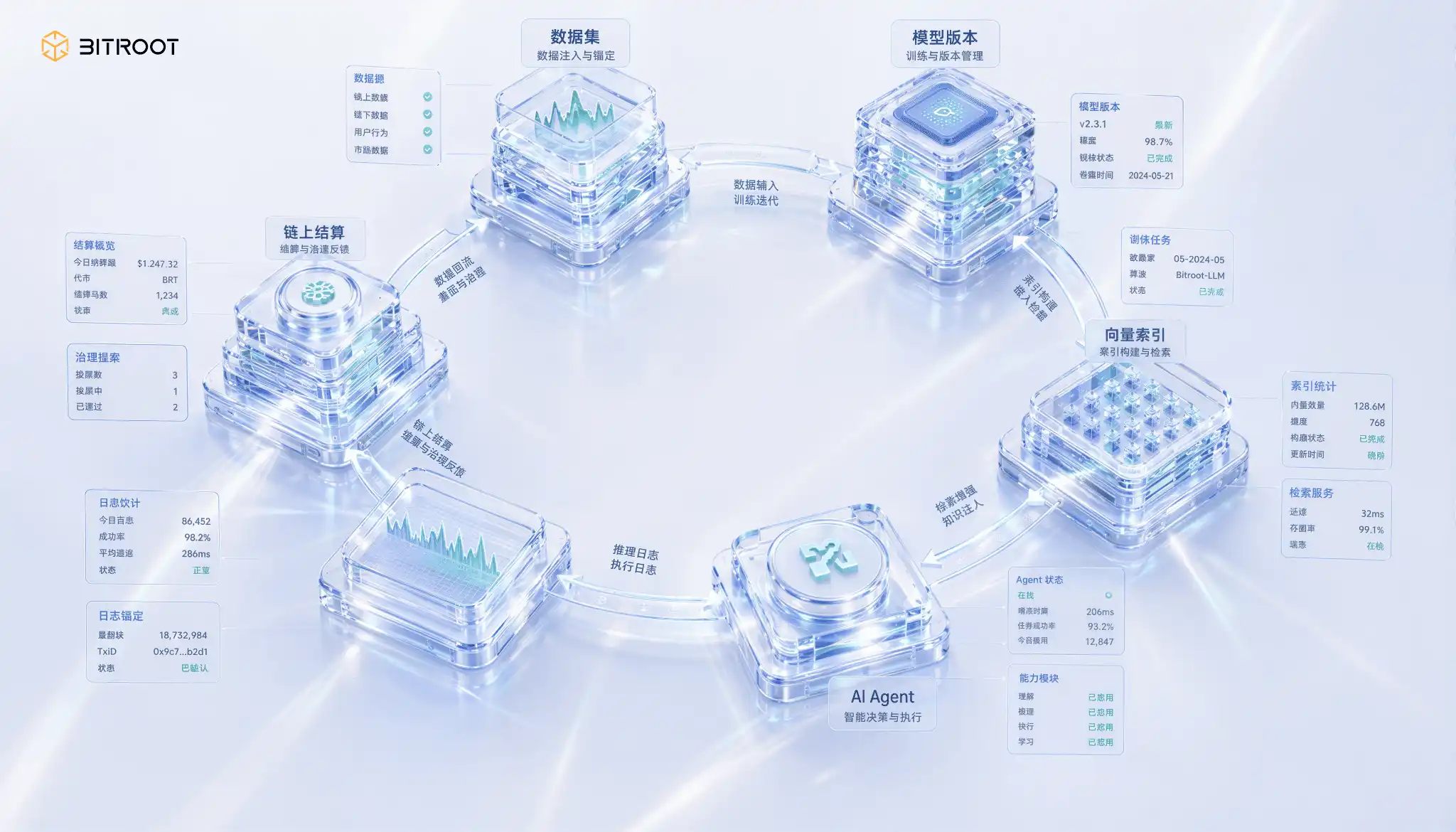
Storage is not a cost centre, but a trust and value distribution system
DISTRIBUTIONAL STORAGE IN THE AI ERA ADDRESSES NOT THE REPLACEMENT OF AN OBJECT'S STORAGE PRODUCT, NOR THE PURSUIT OF A DECENTRIZED NARRATIVE, BUT FOUR MORE HARD THINGS: CREDIBLE EVIDENCE AVAILABLE OVER TIME, AN ORDER OF GOVERNANCE THAT WORKS ACROSS SUBJECTS, A CHAIN OF RESPONSIBILITY FOR DATA AND MODELS, AND SUSTAINABLE ECONOMIC INCENTIVES。
THE SINGLE-AGREEMENT SINGLE-LAYER STRUCTURE DOES NOT COVER THESE OBJECTIVES. A MORE REALISTIC PATH IS A MODULAR STRUCTURE: CONTENT SITE INTEGRITY, STORAGE EVIDENCE OF THE AVAILABILITY OF THE SECURITY TIME DIMENSION, PERMANENT LAYERS OF CRITICAL HISTORY, THERMOSPHERE ON-LINE EXPERIENCE, CHAIN ANCHORING TO SECURE GOVERNANCE AND CLEARANCE. IT'S NOT COMPROMISE, IT'S ENGINEERING REASON. THE FOCUS OF LANDING IS ALSO NOT THE MOST FUNCTIONAL, BUT IT IS FIRST ESTABLISHED IN THE CLOSED CIRCLE, WITH THE SMALLEST CREDIBLE CLOSED CIRCLE RUNNING FIRST, FOLLOWED BY THE ASSETIZATION OF AI, VERIFIABLE RETRIEVAL AND AUTOMATED GOVERNANCE SUPERIMPOSED。
IT'S A THREE-STEP OPERATION. THE FIRST DAY COMPLETES AN EIGHT-FIELD DATA INVENTORY, THE THIRD DAY RUNS A MINIMUM LINK FROM ACCESS, STORAGE, RETRIEVAL TO VALIDATION IN A REAL BUSINESS AREA, AND THE SEVENTH DAY RUNS A MIGRATION THRESHOLD ROUNDUP AT P95 TIME AND UNIT COST. BY DOING SO, THE TEAM MOVED FROM CONCEPTUAL TO ENGINEERING CONSENSUS。
There is also a realistic boundary to be recognized: regardless of the combination of agreements, there is a trade-off between cost, duration and durability, and there is no single answer that is optimal for all operations. A truly sustainable programme comes from a continuous iterative pattern under clear borders, rather than a long-term static configuration after a board。
THE FUTURE PHASE-OUT OF A PROJECT IS OFTEN NOT TOO HIGH FOR TPS, BUT THE DATA LIABILITY CHAIN IS UNCLEAR; IN THE AI ERA, STORAGE IS NOT ABOUT PUTTING DATA IN, BUT RATHER ALLOWING DATA TO BE PROVEN AT ALL TIMES。
Concluding remarks
The real AI-chain competition does not end up in comparison with TPS, Gas or confirmation time. Performance is the entrance, but not the end. Upon entering the AI appliance age, the chain system is intended to carry not only transactions, but also data versions, model calls, algorithms, reasoning records, Agent behaviour and multiple distribution of proceeds。
It's also Bitroot's judgement of the reservoir: storage is not an ancillary module, but the closest layer of AI Stack to the source of value. Whether the data can be proved, whether the model can be reproduced, whether the call can be audited, whether the proceeds can be automatically distributed, or whether a decentrized AI network is truly viable in the long term。
Bitroot is not going to build a chain that only pursues faster implementation, but an infrastructure that allows AI assets to be identified, called, cleared and governed. Parallel EVM and Pipeline BFT address the carrying capacity of high frequency chain events, distributed storage and verifiable mechanisms address the trust base of AI data and models, while programmable sub-accounts and chain governance translate contributions into sustained economic incentives。
When AI Agent begins to act on behalf of the user, when models and data begin to become negotiable assets, storage is no longer a question of "where to place the file " when computing, storage and reasoning services enter the same value network。
IT WILL BE THE TRUST BASE OF THE AI PUBLIC CHAIN AND THE VALUE DISTRIBUTION SYSTEM OF THE NEXT GENERATION OF INTELLIGENT NETWORKS。
In Bitroot, it seems that the real importance of the future is not who has the most data, but who can make it proven, accessible, accountable at any given time and ultimately participate in value settlement。
About Bitroot
Bitroot is a focus parallel to the Layer 1 public chain project with the AI original structure. Bitroot uses the EVM-compatible technology route and explores a high-performance, low-cost implementation environment for AI Agent, DeFi and Web3 applications through parallel implementation mechanisms, consensus optimization and AI interface design。
This paper is from a contribution and does not represent the point of view of the Black Beats。
