
Dari disimpan ke dapat diselesaikan: bagaimana Bitroot menciptakan kembali lapisan nilai data AI
Di satu sisi, Bitroot menyediakan lingkungan performance tinggi sepanjang rantai kinerja melalui paralelisasi EVM dengan Pipeline BFT, dan, di sisi lain, menghubungkan data, model, algoritma dan aplikasi Agen ke jaringan kliring melalui pelatihan terdistribusi, jaringan penalaran, penegakan kredibel dan manajemen aset AI. Di dalam jaringan ini, penyimpanan bukanlah modul yang terisolasi, tetapi lebih kepada infrastruktur yang menentukan apakah data akurat, apakah model tersebut adalah re-emergible, apakah kalkulus ditutup dan apakah kontributor tersebut mampu mempertahankan keuntungan。

Sumber: Bitroot
Penyimpanan bukan pusat biaya, itu sistem distribusi nilai Bitroot AI Stack
Banyak tim yang menyadari bahwa lapisan penyimpanan seharusnya dipilih dengan lebih cermat pada paruh pertama tahun. Data-data yang tidak hilang dan layanan tidak dihentikan, tetapi masalah muncul dengan cara lain: data pelatihan dalam arsip sedang diambil secara perlahan, ekor pencarian vektor hot-spot gemetar dari milidetik ke detik, dan tidak ada yang bisa memberitahu versi mana dari data pelatihan model yang digunakan ketika harus diputar ulang. Pada titik ini, itu bukan lagi ekspansi, tetapi tiga pertanyaan yang lebih sulit lagi: siapa yang dapat membuktikan bahwa data selalu tersedia, siapa yang bertanggung jawab untuk versi dan siapa yang membayar biaya jangka panjang。
INFEKSI PENYIMPANAN SEBAGAI MEMINDAHKAN FILE DARI AWAN PUSAT KE JARINGAN DI BAWAH RANTAI AKAN BERTAHAN DI USIA METADATA NFT. SETELAH OPERASI MELUAS KE BAHASA PELATIHAN AI, BOBOT MODEL DAN INDEKS VEKTOR, PENDEKATAN INI AKAN DENGAN CEPAT GAGAL。
SEBAGIAN BESAR TIM TELAH SEJAUH INI MENGANGGAP PENYIMPANAN SEBAGAI BIAYA LOGISTIK TERBAIK, YANG TEPATNYA ADALAH TEMPAT DI MANA YANG PALING DINILAI PALING RENDAH DAN PALING MUDAH UNTUK DIPILIH: DALAM RANTAI AI, SEBENARNYA ADALAH LAPISAN DISTRIBUSI NILAI YANG MENENTUKAN SIAPA YANG MEMILIKI DATA DAN SIAPA YANG MENDAPATKAN HASIL. ARTIKEL INI HANYA MENJAWAB SATU PERTANYAAN: DALAM KONTEKS INTEGRASI AI DENGAN RANTAI PUBLIK, BAGAIMANA MEMBANGUN PROGRAM PENYIMPANAN YANG DAPAT DIVERIFIKASI, DIKELOLA DAN DIDISTRIBUSIKAN SECARA BERKELANJUTAN. BATAS-BATAS KAPABILITAS DARI TIGA PARADIGMA DOMINAN DIPECAH DI BAWAH, DAN KESULITAN TERTENTU DARI DATA AI DIJELASKAN, DAN AKHIRNYA ARSITEKTUR LIMA-TIER DAN AMBANG FASAD UNTUK MASUK. PENILAIAN INI DIDASARKAN TERUTAMA PADA DOKUMEN PROTOKOL RESMI DAN, SEJAUH MUNGKIN, INFORMASI YANG DAPAT DIVERIFIKASI。
Pada kasus Bitroot, lokasi penyimpanan yang lebih akurat adalah basis distribusi nilai dari AI Stack. Di satu sisi, Bitroot menyediakan lingkungan performance tinggi sepanjang rantai kinerja melalui paralelisasi EVM dengan Pipeline BFT, dan, di sisi lain, menghubungkan data, model, algoritma dan aplikasi Agen ke jaringan kliring melalui pelatihan terdistribusi, jaringan penalaran, penegakan kredibel dan manajemen aset AI. Di dalam jaringan ini, penyimpanan bukanlah modul yang terisolasi, tetapi lebih kepada infrastruktur yang menentukan apakah data akurat, apakah model tersebut adalah re-emergible, apakah kalkulus ditutup dan apakah kontributor tersebut mampu mempertahankan keuntungan。

INI SEMUA DIRANTAI DAN BERPUSAT. INI TIDAK BEKERJA DI AI
PADA BEBERAPA TAHUN TERAKHIR, MASALAH PENYIMPANAN SERING KALI DIKURANGI MENJADI SATU ATAU LAINNYA: RANTAI PENUH ATAU SENTRALISASI. KEDUA JALAN TIDAK DAPAT DILALUI DI LOKASI AI。
Tekanan rantai penuh spesifik. Data pelatihan, bobot model, log log log log log, indeks vektor umumnya adalah update tinggi volume dan frekuensi tinggi, dan bahkan jika mereka diiris dan dirantai, mereka menabrak langit-langit muntah maupun kurva biaya. Kepusatan penuh finedisasi berjalan cepat, tetapi dasar kepercayaan di mana validasi, traceability, kedaulatan data dan kolaborasi cross-subject tergantung rapuh dan tidak dapat dipertahankan setelah multiple account dibagi dan hak terlibat。
LEBIH PENTING LAGI, AI MENGUBAH PENYIMPANAN DARI ITEM BIAYA KE FAKTOR PRODUKSI. KEPENGURUSAN VERSI DATA MENENTUKAN SIAPA YANG AKAN MENGAMBIL INISIATIF UNTUK MODEL ITERATIF; APAKAH DAPAT DITUNJUKKAN BAHWA DATA TERSEDIA DAN BERDAMPAK LANGSUNG PADA PRIORITAS KOMPUTASI DAN KLIRING; DAN KEMAMPUAN UNTUK MENGOTOMATISKAN DATA ADALAH MASALAH APAKAH SEBUAH TIM DAPAT MENCIPTAKAN INSENTIF EKOLOGI JANGKA PANJANG. WADUK INI BUKAN LAGI SISTEM LOGISTIK MELAINKAN SISTEM DISTRIBUSI NILAI。
Jadi struktur penyimpanan kualifikasi harus menjawab empat pertanyaan sekaligus: Apakah data yang nyata dan diinginkan, apakah data dapat dilacak ke versi model, apakah kompetensi dan manfaat dapat dikelola, dan apakah sistem saldo biaya dan kinerja dari waktu ke waktu。

Titik masukan bitroot Bitroot: biarkan data AI bergerak dari "storable" ke "liquidable"
Di situlah Bitroot harus diisi. Sebagai penghubung publik Parralleel EVM untuk adegan AI, narasi penyimpanan Bitroot tidak boleh berhenti di \"di mana data ditempatkan\", tetapi lebih menjawab \"bagaimana data terbukti, bagaimana mereka disebut, bagaimana mereka berpartisipasi dalam split\". Bahan pelatihan nutfah, bobot model, indeks vektor dan log penalaran dapat dibiarkan dalam lapisan penyimpanan yang didistribusikan lebih cocok untuk objek yang lebih besar, tetapi komitmen Hashi mereka, hubungan versi, strategi izin, catatan panggilan dan acara pendapatan membutuhkan bukti rantai terpadu di Bitroot。
Dari sudut pandang ini, Bitroot's high-input dan rendah-kemerdekaan acara tidak hanya layanan transaksi DeFi, tetapi layanan lebih nuansa dan frekuensi tinggi mengatur acara di AI Stack: Pemutakhiran set data akan berlabuh, versi model akan didaftarkan, panggilan AI Agen akan diselesaikan, hasil pencarian akan arbitrated dan ketersediaan node penyimpanan akan terus ditantang dan diberi hadiah. Hanya jika rantai bawah mampu mengambil alih peristiwa-peristiwa ini akan AI aset data tidak terkunci dalam basis data terpusat atau berubah menjadi kotak hitam yang tidak dapat dihitung di bawah rantai。

Tiga paradigma dominan, tidak ada yang bisa menembus adegan saja
Kompetisi untuk penyimpanan didistribusikan tidak pernah paling maju, tetapi yang paling tepat dalam struktur data Anda。
KONTEN JARINGAN PENCARIAN KONTEN MENYELESAIKAN APAKAH ITU DATA ATAU TIDAK, DAN TIDAK ADA YANG MENJAMIN ITU ONLINE. MENURUT DOKUMEN RESMI IPFS, CID DIDASARKAN PADA IDENTITAS HASHI DARI KONTEN DAN TIDAK BERGANTUNG PADA LOKASI: KONTEN YANG SAMA MENGHASILKAN CID YANG SAMA DI BAWAH PENGATURAN KODE YANG SAMA, DAN PERUBAHAN CID SELAMA KONTEN BERUBAH BYTE. FITUR INI MEMBUATNYA ALAMI UNTUK VERIFIKASI KELENGKAPAN, PEMBERATAN DAN REFERENSI SISTEM SILANG, DAN MERUPAKAN KAPASITAS BAWAH UNTUK VALIDASI DATA. NAMUN, LOKASI KONTEN TIDAK SETARA DENGAN EKONOMI BERKELANJUTAN, DAN CID MENJAWAB PERTANYAAN IDENTITAS DAN TIDAK MENJAWAB SIAPA YANG MEMASTIKAN BAHWA KONTEN TERSEBUT TETAP ON LINE. PIT PERTAMA YANG BANYAK TIM MELANGKAH DI SINI: SECARA TEKNIS, CID, DAN OPERASIONAL, TIDAK ADA KOMITMEN UNTUK USABILITY。
Penyimpanan jaringan pasar adalah penggunaan mekanisme ekonomi untuk membeli ketersediaan dimensi waktu. Menurut dokumentasi Filecoin, jaringan menciptakan mekanisme untuk komitmen penyimpanan ditambah sertifikasi berkelanjutan melalui Proof-of-Replikasi dan Proof-of-of-Spacetime. Zodica PoRep membuktikan bahwa salinan unik ini pada kenyataannya ada pada amplop awal, dan PoSt berulang kali membuktikan bahwa itu dalam siklus susulan. WindowsPost biasanya mengatur siklus sertifikat pada dasar 24 jam, memotong ke beberapa jendela bukti 30 menit, dan jika repositori tidak menyerahkan bukti yang valid di jendela, itu memicu pengurangan jaminan dan pengurangan kapasitas penyimpanan. Dalam sistem ini, kegunaan adalah tes terus menerus, bukan komitmen satu-off setelah kontrak. Ini kontraktual, model yang dapat diaudit ini cocok untuk pengarsipan jangka menengah dan panjang, backup dan pasar data, tetapi lebih seperti warehousing jangka panjang yang terbukti daripada layanan online yang didelay rendah alami yang menempatkan kueri online frekuensi tinggi langsung di bawah tekanan dan pengalaman penundaan ekor。
Jaringan penyimpanan permanen mengambil rute lain, dengan pembayaran satu-off untuk sejarah. Menurut Perjanjian Arweave dan informasi Buku Kuning, sebagian biaya unggahan akan masuk ke kolam penyimpanan untuk menutupi insentif penyimpanan jangka panjang dan menempatkan keberlanjutan jangka panjang dalam model penagihan daripada mengandalkan praktik kelanjutan selanjutnya. Ini cocok untuk arsip sejarah, dokumen kunci, bahan hak cipta, dan catatan tak dapat dilepas. Papan Pendek juga jelas: permanensi tidak secara otomatis berjumlah penundaan tinggi dan rendah, dan pada praktiknya masih ada kebutuhan untuk melipat cache, gateway atau lapisan indeks garis dekat untuk memenuhi pengalaman waktu-nyata di sisi pengguna。
Selain tiga paradigma dasar ini, dua kombinasi umum teknik yang bernilai berat. Salah satunya adalah campuran dari lapisan ketersediaan data ditambah penyimpanan objek, dan lebih standardisasi data disseminasi dan bukti ketersediaan dengan biaya cross-synthesis dan pemerintahan antarmuka yang kompleks. Yang lainnya adalah sinergetik cloud-plus, penundaan rendah dan toleransi bencana yang lebih baik, tetapi governance biaya dan manajemen koheren lebih sulit dicapai。
Bagaimanapun, kesepakatan untuk makan semua adegan tidak akan berhasil. Metode yang efektif adalah dikelompokkan berdasarkan jenis data: untuk menghilangkan kegigihan, waktu penerimaan dan kepatuhan, untuk mencocokkan lapisan kapabilitas secara terpisah, dan diorganisir secara seragam dengan merantai dan mengatur lapisan。
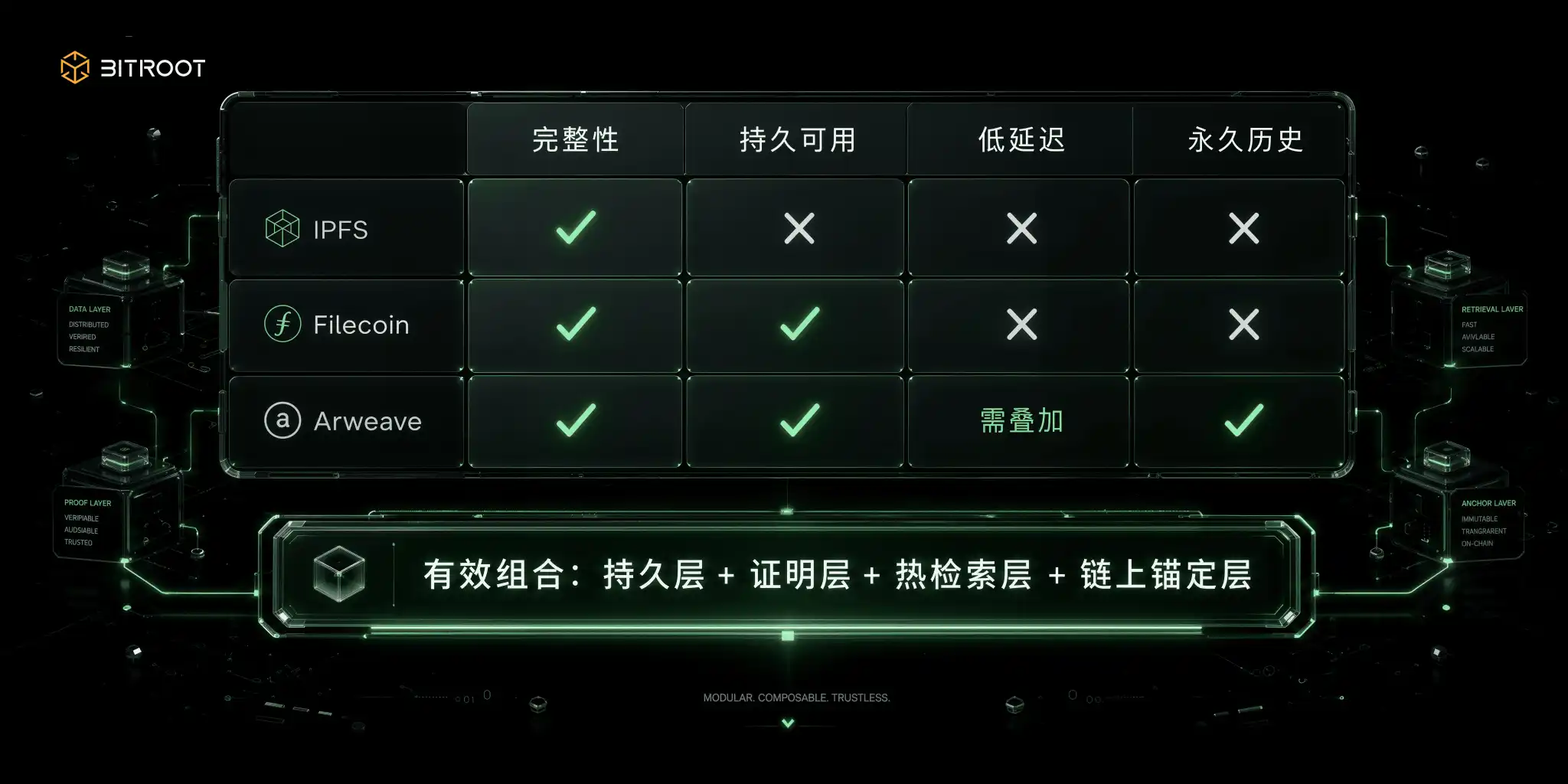
Pilihan ruang yang s Bitroot ' s juga harus didasarkan pada logika kombinasi ini: daripada mengganti satu sama lain dengan IPFS, Filecoin, Arweave atau objek, itu menempatkan mereka dalam lapisan tanggung jawab yang berbeda. Alamat-alamat konten-konten yang digunakan untuk identitas data dan integritas, sertifikat penyimpanan digunakan untuk ketersediaan jangka panjang, lapisan permanen digunakan untuk sejarah kunci dan dokumen, lapisan pencarian termal digunakan untuk pengalaman aplikasi AI. Rantai Bitroot atas digunakan untuk penambat versi, kebijakan otoritas, penyelesaian panggilan dan resolusi sengketa. Dengan kata lain, Bitroot tidak perlu menjadi repositori fisik dari semua data, tetapi lebih merupakan akun andal dari aliran data AI。
KESULITAN PENYIMPANAN AI AI, BUKAN BERKAS, TETAPI MENJALANKAN LINK PRODUKSI
DALAM PENGATURAN AI, OBJEK PENYIMPANAN DIBAGI MENJADI SETIDAKNYA EMPAT KATEGORI: DATA PELATIHAN, BOBOT MODEL, INDEKS VEKTOR, LOG PENALARAN. SIKLUS HIDUP, MODE AKSES DAN NILAI KEPADATAN EMPAT KATEGORI SUBJEK BENAR-BENAR BERBEDA, DENGAN SET STRATEGI UNTUK MENGELOLA, TABUNGAN JANGKA PENDEK, DAN JANGKA PANJANG PERIODE PEMERINTAHAN YANG TIDAK TERKENDALI。
Masalah untuk melatih data tidak dalam kapasitas dan drifts dalam versi. Banyak tim yang menyamakan masalah pelatihan data dengan biaya penyimpanan TB-grade, dan yang lebih bermasalah adalah hanyut: selama aturan pembersihan, ambang seleksi sampel atau perubahan kalibrasi, perubahan perilaku model, dan tanpa pengikatan data dan versi model, penilaian off-line sulit untuk verifikasi. Menurut model MLFlow ' s dan praktik pelacakan data, operasi pelatihan dan pengikatan versi data adalah prasyarat untuk replikasi percobaan. Prinsip ini tetap berlaku pada rantai: data asli tidak perlu dirantai penuh, tetapi melepaskan komitmen, jumlah kunci dan sumber sidik jari harus dirantai. Setidaknya tiga penanda harus dipasang pada proyek, versi data, operasi pelatihan, versi model, dan, tanpa satu, masalah pada baris akan merosot dari bukti ke tebak。
masalah bobot model sering kali tidak apakah mereka dapat diunduh, tetapi siapa yang akan menyebut batas. sebuah model memasuki produksi, biasanya melalui beberapa negara bagian skala kelabu, penggunaan utama, rollback dan decommissioning, tanpa sistem standardisasi pendaftaran dan otorisasi, dan panggilan online adalah kotak hitam yang tidak terdengar. sebuah model yang matang pendaftaran pusat catatan garis keturunan, versi alias, tanda tangan dan label audit. untuk sistem rantai, model versi tidak boleh hanya sebuah dokumen, hashi, tetapi harus diikat dengan strategi otoritas, distribusi hasil dan batas liabilitas。
Kesulitan indeks vektor terkonsentrasi dalam satu tempat: konsistensi setelah panas dan lapisan dingin. Ada kontradiksi inheren antara pencarian vektor, penundaan rendah dan biaya rendah pertempuran satu sama lain: Thermosphere bergantung pada memori atau layanan indeks kinerja tinggi untuk menjamin respon online dan lapisan dingin tergantung pada penyimpanan objek untuk mengandung biaya jangka panjang. Tanpa metadata terpadu dan strategi tersinkronisasi, kedua lapisan dipisahkan dengan cepat dan masalah pertanyaan yang sama mengembalikan hasil semantik pada node yang berbeda. Jadi sistem vektor harus mendukung dua hal, proses konstruksi indeks dapat dilacak dan versi indeks termosfer dapat didamaikan dengan data master dingin, yang persis apa teks lateral dapat memvalidasi pencarian。
Kesulitan untuk menetapkan log penalaran di mana privasi, auditing dan kepatuhan didirikan. Ini adalah baik material audit keamanan dan sumber risiko privasi: retensi penuh dan eksplisit menimbulkan risiko kepatuhan, benar-benar tidak berkelanjutan dan kehilangan kecelakaan revolving kapability. Pendekatan yang layak dilakukan adalah tiga lapisan takhayul, penyimpanan konten dissensi, komitmen Hashi ' s untuk naik rantai dan akses adalah subjek untuk audit otorisasi untuk mencapai hirarki yang tidak dapat dilepas dan dapat dibatalkan。
Dalam A AI Stack karya-AB Bitroot, keempat kategori ini dapat mengacu pada empat jenis tindakan pemerintahan: pelatihan data untuk penambat dan pendaftaran sumber, model pemberatan untuk pendaftaran aset dan otorisasi untuk panggilan, indeks vektor untuk panas dan stratifikasi dingin dan konsistensi, log penalaran untuk penyimpanan tidak sensitif dan komitmen audit. Mereka tidak perlu dirantai dengan cara yang sama, tetapi mereka perlu membentuk ID aset terpadu, spektrum versi dan panggilan peristiwa di Bitroot. Ini memungkinkan membentuk lingkaran tertutup komersial yang dapat digunakan kembali antara aset data, aset model dan aplikasi Agen。

Tapi itu intinya. Itu intinya
KOMITMEN PENYIMPAN TANPA BUKTI KEBERGUNAAN PADA DASARNYA SETARA DENGAN KOMITMEN DALAM LINGKUNGAN PRODUKSI. PENYIMPANAN AGIHAN AGIHAN MELIBATKAN PRODUKSI SETIDAKNYA DALAM TIGA CARA: INTEGRITAS, KEHANDALAN, TINGKAH LAKU, AUDITABILITAS, DAN, SEKALI ADEGAN PENCARIAN AI BERADA DI TEMPAT, LEBIH SULIT UNTUK KEMBALI BERSAMA。
Kelengkapan Akomodasi dibuktikan oleh lokasi konten ditambah komitmen Merkle. Lokasi isi key memastikan bahwa sidik jari data stabil dan Merkle berjanji untuk dapat diverifikasi sebagian. Inti dari proyek ini adalah bahwa Anda dapat membuktikan subset objek dalam pecahan, tanpa harus membacanya secara penuh. Untuk bobot model besar, bahasa besar dan data multimedia, ini secara langsung menentukan biaya validasi。
Ketersediaan Ketersediaan dibuktikan oleh mekanisme tantangan dan validasi sampel. Praktik Filecoin telah menunjukkan bahwa usabilitas bukanlah SLA oral, tetapi merupakan bukti pada rantai tantangan periodik yang abstrak struktur generik adalah seperangkat pemeriksaan titik pasif, pemeriksaan aktif, dan pidana gagal: node harus merespon tantangan di jendela yang ditentukan, jika tidak, penalti dipicu atau beratnya dikurangi. Pemikiran yang sama berjalan lebih jauh dalam hal ketersediaan data. Menurut desain sampel ketersediaan data Celesti ' s, data diperluas dari kxk ke matriks 2kx2k, dengan nodus cahaya akumulasi melalui multiple-wheel random sampling dan probabilitas, tanpa harus mengunduh seluruh data untuk membangun keyakinan probabilitas tinggi dalam usability. Ini adalah inspirasi untuk skenario AI untuk bermigrasi: tidak semua ketersediaan perlu sepenuhnya divalidasi dengan mengunduh, dan konfirmasi statistik lebih realistis dalam sistem besar。
Perbuatan itu tunduk pada rantai jangkar dan tanda insiden. Hal tersulit dari sistem penyimpanan adalah perilaku: yang mengunggah apa, yang mengubah strategi, yang memicu migrasi, yang menggunakan model sensitif. Jika tindakan ini tidak bergabung ke dalam satu aliran peristiwa, mereka akan kembali ke titik di mana ada perselisihan. Ketimbang menempatkan semua rincian dalam rantai, pemerintahan memegang koleksi bukti yang paling kecil, definitif dan dapat diverifikasi pada saat sengketa。
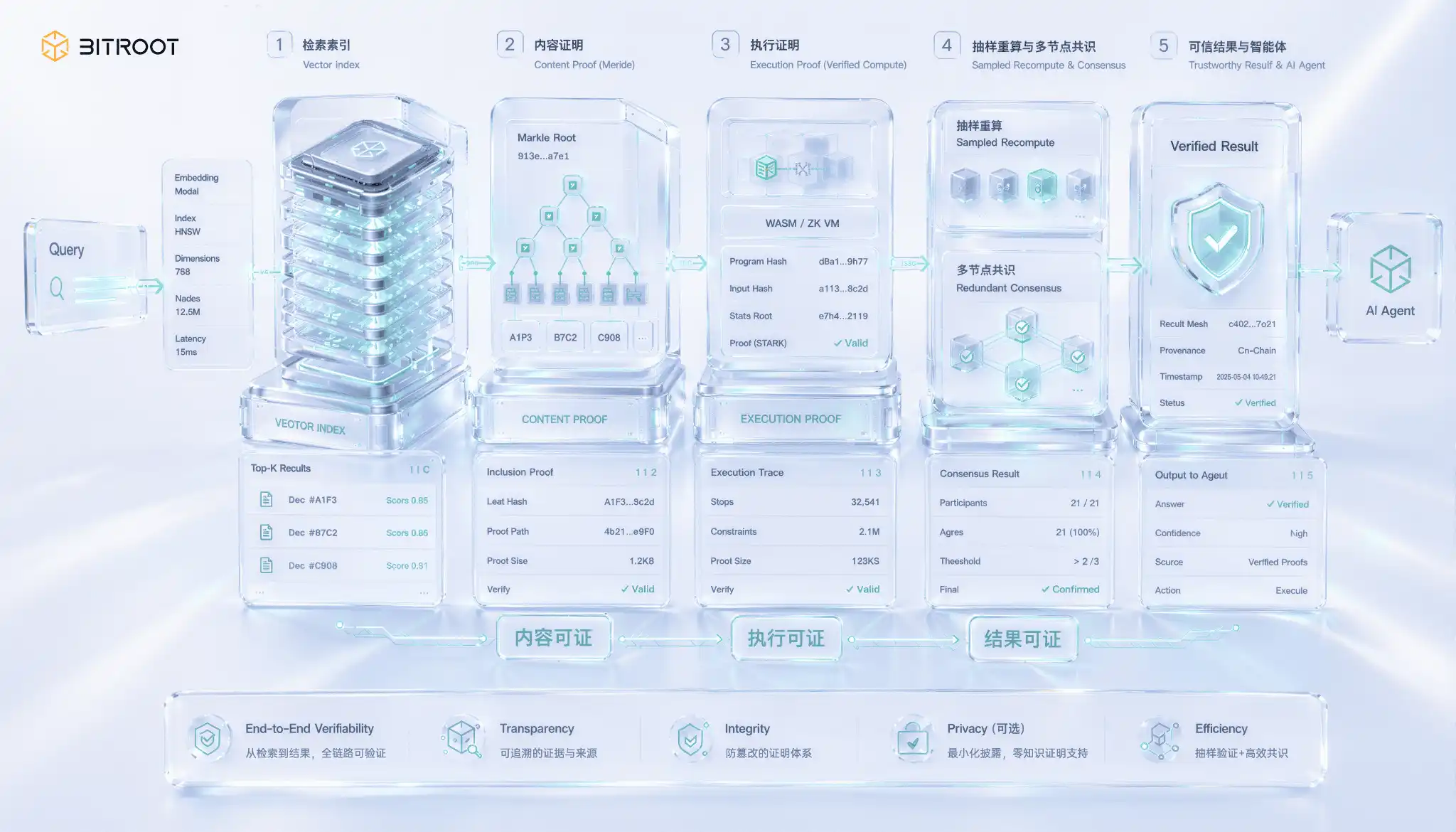
Sertifikat pencarian adalah yang unik dan paling sulit salah satu adegan AI, dan masalah muncul dalam celah yang mudah diabaikan: mengembalikan hasilnya tidak sama dengan mengembalikan hasil yang tepat. Node pencarian vektor sempurna mampu mengambil indeks out-of-date, atau bahkan melewatkan tetangga terdekat yang sebenarnya, dan kembali ke salah satu yang tampaknya masuk akal Anda atas-k, dan Anda tidak dapat melihat nilai dari kembali saja. Secara semanistik retrieved output tidak dibuktikan sendiri, dan kesalahan tidak dilaporkan, tetapi hanya diam-diam mengambil kembali kualitas dan kinerja model. Ketika hasil yang akan digunakan untuk penyelesaian, otorisasi atau pengambilan keputusan berantai, kesenjangan ini meningkat dari kualitas ke kepercayaan。
Membongkar pencarian adalah, sebenarnya, jaminan tiga tingkat perubahan. Level pertama adalah bukti bahwa vektor pengembalian memang tergolong ke dalam versi indeks yang dijanjikan, dengan menetapkan struktur data untuk indeks, dengan melakukan Merkle untuk merantai indeks ke akarnya dan mengembalikan hasil dengan sertifikat enkapsulasi untuk memastikan bahwa node tidak dibuat atau dirusak data. Tier kedua adalah pelaksanaan sertifikat yang memang telah dijalankan pertanyaan pada versi yang dijanjikan tersebut, daripada pada indeks yang dimodifikasi secara privat, yang mengharuskan proses pertanyaan dimasukkan ke dalam perhitungan yang dapat diverifikasi. Tingkat ketiga adalah yang paling sulit untuk dibuktikan, dengan hasil, bahwa top-k yang dikembalikan memang yang paling baru pada ukuran yang diberikan, daripada yang hilang dari tetangga terdekat, yang pada dasarnya bukti kelayakan pencarian tetangga baru-baru ini。
Hasil Sitract pada skala produksi dalam hal kedekatan dimensi tinggi dengan tetangga terdekat masih berada di garis depan isu, dan sementara kata sandi seperti nol bukti pengetahuan semakin maju, biaya komputasi vektor berdimensi tinggi jauh dari dibuktikan untuk penggunaan online skala besar. Solusi teknik praktikal bahasan adalah bottom-up daripada step-by-step: pertama, untuk melakukan versi indeks dan membangun parameter untuk merantai mereka untuk memastikan pelacakan; kemudian untuk menghitung ulang sampel pertanyaan, untuk menjalankan kembali pencarian atas dasar pro rata untuk salinan kredibel dan membandingkan hasil dengan keyakinan statistik alih-alih artikel-by-artikel pembuktian; untuk memungkinkan multiple node independen untuk overload, untuk mencapai konsensus pada hasil kembali dan untuk menaikkan biaya kecurangan satu titik; dan hanya ketika ada perselisihan atas konsensus akan rekalulasi penuh dari keputusan pencarian untuk diupgrade. Garis ini berjalan seiring dengan gagasan memprioritaskan sampel dalam sertifikat kebolehgunaan: dalam sistem skala besar, konfirmasi statistik dan eskalasi sengketa cenderung lebih mudah tersedia daripada yang ditunjukkan secara ketat oleh artikel melalui artikel。
Bagi Bitroot, pencarian yang dapat diverifikasi bukanlah fungsi penyimpanan yang terisolasi, tetapi merupakan bagian dari eksekusi AIAgent yang kredibel. Jika Anda bergantung pada dasar pengetahuan eksternal, berat model atau indeks vektor untuk pengambilan keputusan, sistem harus menjawab setidaknya tiga hal: Ia membaca versi data, memanggil versi model dan mengembalikan hasil dari versi indeks terdaftar. Bitroot dapat memampatkan bukti ini ke dalam rantai peristiwa yang dapat diverifikasi, memungkinkan Agen untuk pindah dari "terlihat cerdas" ke "retroaktif, kontroversial, penyelesaian"。

Masalah nyata dengan pemilihan: bukan pilihan, tapi pengelompokan
Banyak ulasan programme yang gagal karena isu-isu yang salah. Formulasi yang benar bukanlah apakah kita ingin menggunakan kesepakatan, tetapi apa campuran data kita, apa indikator target, dan apa batasannya. Disarankan agar empat gerakan diikuti。
Aset data aset pertama. Sekurang-kurangnya membedakan antara data status, data objek, data pengambilan kembali, data audit dan membuat venture template medan tetap, dengan minimum delapan: tipe data, peningkatan volume, puncak gabungan distribusi, pembacaan dan penulisan rasio, siklus retensi, tingkat kepatuhan, ekstensi waktu target, tutup biaya. Setelah ladang bersatu, komunikasi seleksi lintas tim jauh lebih cepat。
PENEBUSAN TARGET TINGKAT PELAYANAN. EKSTENSI WAKTU P95/P99, WAKTU PEMULIHAN RRO, TITIK PEMULIHAN RPO, TARGET KETERSEDIAAN, KAP BIAYA TB TUNGGAL DITULIS UNTUK MATI, JIKA TIDAK TIDAK TIDAK ADA PENGUASA UNTUK SEMUA DISKUSI SELANJUTNYA。
Kemudian membangun peta kemampuan. Kategori-kategori penyimpanan permanen, bukti usabilitas secara siklik, penundaan rendah dalam pengambilan dan akses untuk pemerintahan ditunjukkan ke berbagai lapisan teknologi daripada ke lapisan tunggal。
PENGAKHIRAN AMBANG MIGRASI. DATA APA YANG MEMUNGKINKAN UNTUK SENTRALISASI TRANSISI, INDIKATOR APA YANG MEMICU MIGRASI, DAN KETIKA PENGGANTIAN LAYAKISASI HARUS DISELESAIKAN. SALAH SATU PENDEKATAN PRAKTIS ADALAH UNTUK MENETAPKAN AMBANG BATAS GANDA: BIAYA TB TUNGGAL OVER-BUDGET UNTUK DUA SIKLUS STATISTIK BERTURUT-TURUT, ATAU P95, DUA MINGGU BERTURUT-TURUT OVER-TARGET, SECARA OTOMATIS MEMICU TINJAUAN MIGRASI STRUKTURAL. TAK ADA PEMERINTAHAN TANPA AMBANG BATAS DAN MASA TRANSISI MENJADI PERMANEN。
Program Landing Landing: struktur lima-tired, dengan hidup, diinginkan dan dikelola penutupan
Nilai arsitektur tidak dalam urutan magnitudo, tetapi dalam bentuk loop yang dapat diverifikasi. Berdasarkan kerangka kerja sebelumnya, programme dikondensasi menjadi lima lapisan: lapisan penambat rantai, lapisan penyimpanan objek, lapisan pencarian indeks, lapisan sertifikat serviceability, lapisan akses kunci. Tujuan tujuannya adalah mengubah diverifikasi menjadi kapasitas baku, kinerja tinggi menjadi konfigurasi, dan mengatur menjadi proses yang dapat ditegakkan。
Di Bitroot, kelima lapisan ini dapat dipahami lebih lanjut sebagai modul pengaturan penyimpanan AI Stack: Paralel EVM menyediakan jangkar frekuensi tinggi dan kapabilitas kliring, Pipeline BFT menyediakan kepastian berdelay rendah, jaringan penyimpanan terdistribusi ke objek besar dan data historis, layanan lapisan pencarian indeks AI Agen dan panggilan aplikasi, ketersediaan lapisan sertifikat menerjemahkan kualitas layanan node ke dalam kredit dan imbalan, dan lapisan akses kunci menghubungkan kedaulatan pengguna, perlindungan privasi dan modelisasi otorisasi komersialisasi。
Kapal pembawa berita berantai disimpan dalam keadaan terkecil kebutuhan: komitmen data, sidik jari versi, ringkasan strategi izin, peristiwa penyelesaian. Objek besar tidak dirantai untuk membuktikan keberadaannya dan versi yang benar. Ini mempertahankan kemungkinan rantai dan tidak memungkinkan basi untuk diseret ke bawah oleh dokumen besar。
Dalam kerangka kerja Beitroot, jangkar rantai bukan sekadar \"rekaman Hashi\", melainkan titik masuk umum untuk pendaftaran aset AI, pemerintahan otoritas, distribusi hasil dan keputusan sengketa. Data set, model bobot, indeks vektor dan log penalaran semua dapat disimpan di bawah rantai dengan cara yang paling sesuai, tetapi komitmen versi mereka, status yang berwenang, catatan panggilan dan atribusi dari hasil perlu masuk ke rantai Bitroot. Jadi, penyimpanan rantai bertanggung jawab untuk membawa beban, dan Bitroot bertanggung jawab untuk membawa kepercayaan。
Lapisan penyimpanan objek membawa data riil, menggunakan strategi campuran decodering dan penyalinan: nilai-tinggi, objek-objek yang dapat diakses frekuensi-rendah tunduk pada kesalahan dan nilai-sedang, objek-objek yang divisi frekuensi tinggi menjadi subjek efisiensi pencarian. Strategi ini bukan konfigurasi statis dan disesuaikan untuk mengunjungi panas dan dinamika kelas bisnis。
Lapisan pencarian indeks index memasukkan data meta dan indeks vektor ke dalam katalog terpadu, termosfer terhubung ke pencarian daring, dan lapisan dingin diarsipkan dan direkonstruksi. Semua versi indeks index diperlukan untuk mendaftarkan versi sumber dan parameter binaan, jika tidak indeks drift tidak dapat dilacak。
Kuantifikasi dari perilaku node dalam sertifikat lapisan ketersediaan. Tingkat keberhasilan dalam menanggapi tantangan, frame waktu respon dan tingkat keberhasilan rehabilitasi semua dinilai dalam hal kredibilitas, peringkat dan alokasi insentif terikat untuk menghindari kapasitas dan ketersediaan yang memuaskan。
Kontrol akses kunci dan kepatuhan. Data bersensitivitas tinggi ency diklasifikasikan dengan otorisasi kunci dan time-barred, log penalaran adalah de-sensitif disimpan dengan pelepasan audit, dan panggilan model tunduk pada pembatalan. Operasi izin itu sendiri juga meninggalkan tanda untuk mencegah drift konfigurasi。
Kelima lapisan ini ditutup pada tingkat implementasi, bukan garis air satu arah: Setelah akses data, irisan dikodekan ke dalam lapisan objek untuk membuat indeks setelah menulis dan sauh rantai; pertanyaan online thermosfer terlepas, dengan kurang dari hit kembali ke lapisan dingin; mengembalikan hasil saat memicu verifikasi kelengkapan dan verifikasi otorisasi, dan perilaku kunci memasuki penyelesaian dan audit. Nilai nyata dari rantai ini adalah empat pertanyaan dapat dijawab di setiap titik atau saat: Dari mana asal data tersebut, versi yang ada saat itu, yang berhak mengakses dan apakah sistem dapat membuktikan ketersediaannya。
Ini juga alasan utama mengapa Bitroot cocok untuk pemerintahan penyimpanan AI. Panggilan untuk AI Agent, switching dari versi model, perubahan dalam otorisasi data, sengketa atas hasil pencarian bukan operasi frekuensi rendah di belakang panggung, tetapi merupakan peristiwa berantai yang berlanjut dengan pertumbuhan aplikasi. Jika rantai bawah gagal memberikan cukup rendah konfirmasi penundaan dan cukup tinggi throughput, pemerintahan penyimpanan akhirnya terpaksa kembali ke bagian bawah rantai dan untuk rekonsiliasi manual. EVM paralel dari Bitroot dan Pipeline BFT tidak hanya bernilai lebih tinggi dari TPS, tetapi memungkinkan peristiwa-peristiwa pemerintahan frekuensi tinggi ini berlabuh, diselesaikan dan dikejar secara real time。

Siapa yang akan membayar untuk itu: mari kita gunakan kita, bukan kapasitas, untuk menentukan kembali
Agar penyimpanan dapat dijalankan dalam jangka panjang, insentif harus tersedia, bukan kapasitas bertumpuk. Hanya jumlah kapasitas yang dihargai, yang setara dengan insentif menyamar untuk menumpuk hard drive dan layanan ringan. Titik ini telah diperkuat oleh mekanisme Filecoin: ini memperkenalkan konsep kekuatan yang disesuaikan kualitas, memungkinkan penerimaan perintah penyimpanan nyata, khususnya perintah valid dan validasi, misalnya unit pengukuran minimum ruang penyimpanan, untuk mendapatkan bobot yang lebih tinggi dalam pengukuran daya, sehingga memiringkan insentif ke arah kapasitas untuk menyediakan layanan yang sebenarnya, daripada kapasitas kosong dari amplop belaka. Ide ini layak mendapat insentif membangun diri。
Ia dimasukkan ke dalam fungsi insentif yang dapat ditegakkan yang menghitung setidaknya empat dimensi secara bersamaan dan mengklarifikasi logika berat masing-masing. Kapasitasnya menentukan dasar berbagi dan menjawab berapa banyak ruang yang kau janjikan. Tarif dan respon daring waktu menentukan faktor kualitas layanan dan menjawab apakah ruang ini benar-benar diinginkan ketika dibutuhkan, yang seharusnya memiliki berat badan yang lebih tinggi, jika tidak, kemampuan kita menjadi slogan. Kejayaan tingkat pemulihan data menentukan kredibilitas bencana, dan kemampuan untuk membangun kembali salinan respon setelah node telah turun secara langsung berkaitan dengan kelangsungan data jangka panjang. Kepadatan nilai data demand menentukan permintaan berdampingan, dengan pengganda diferensial untuk dataset bernilai tinggi dan model demand tinggi, memberikan pengembalian yang lebih tinggi ke langka dan sering disebut data. Para Insentif harus diberikan kepada dinas yang terbukti daripada kapasitas yang dinyatakan。
Dorongan positif lentur sendiri tidak cukup, mengikat janji, pidana, arbitrase berada di tempat pada saat yang sama, dan varian bottom-up adalah untuk dipenuhi: manfaat yang diharapkan dari kecurangan harus lebih rendah dari biaya yang diharapkan untuk dihukum, jika tidak mekanisme sertifikasi apapun akan dilewati oleh rasionalitas ekonomi. Node dekrar adalah biaya dari sebuah jaminan dari usability, ukuran yang harus proporsional dengan kalkulus dan nilai data dari undercoin; dalam desain Filecoin, repositori diperlukan untuk membayar pre-mortgage dengan kalkulus yang dijanjikan, memicu biaya kegagalan setelah kawat dijatuhkan dalam jendela demonstrasi, dan pembebasan permanen dari sektor memicu penalti penghentian yang lebih berat, yang berarti mendiskriminasi antara istirahat jangka pendek dan penarikan niat jahat. Arbitrase didasarkan pada rantai sengketa bukti-didorong: Ketika pengguna-pengguna Indianapolis mengklaim bahwa data tidak tersedia dan node mengklaim layanan normal, perekaman tantangan, pensampelan sertifikat dan log insiden membentuk dasar yang dapat dibaca mesin untuk adjudikasi, mengkompresi perselisihan yang mewajibkan intervensi manual ke dalam penentuan rantai yang dapat diverifikasi。
SKENARIO AI INI JUGA MEMILIKI LAPISAN PEMERINTAHAN YANG JAUH LEBIH SULIT DI ATASNYA: BAGAIMANA KEUNTUNGAN TRIPARTIT DAPAT DIPATAHKAN? MODEL YANG TELAH BERULANG KALI DIGUNAKAN, DIDUKUNG OLEH BAHASA DARI KONTRIBUTOR DATA, PELATIHAN PENYUMBANG MODEL, HOSTING NODE PENYIMPANAN, YANG SEMUANYA BERKONTRIBUSI PADA NILAI PANGGILAN AKHIR TETAPI SULIT DIAMATI SECARA LANGSUNG. HAL INI LAYAK UNTUK ATRIBUSI NILAI DASAR PADA ACARA RANTAI TERUKUR: SUB-COUNTING DAN PENYELESAIAN OTOMATIS DATA DAN MODEL TERIKAT PADA SETIAP PANGGILAN MELALUI VERSI SIDIK JARI DAN LINK DARAH, KEMUDIAN SECARA OTOMATIS TERPECAH DALAM PROPORSI DENGAN BAGIAN YANG DAPAT DIPROGRAM PRA-DITULIS DARI AKUN UNTUK MENGHINDARI EX POST FACTO RIPPLETION. HAL INI DISERTAI DENGAN MEKANISME DAFTAR HITAM DAN KEHILANGAN, YANG MERAMPAS HIPOTEK DAN MEMBEKUKAN HASIL BERIKUTNYA SEKALI ARBITRATED TERHADAP PENGUNGGAHAN DATA BERBAHAYA, PELANGGARAN HAK CIPTA DAN PENCURIAN MODEL. JIKA TIDAK, AKAN ADA HASIL KONTRA-INTUITIF: SEMAKIN SUKSES ASETISASI, SEMAKIN BANYAK PERSELISIHAN YANG DIBAGI DAN DIBERIKAN, DAN TEPAT SEKALI KEPERCAYAAN EKOLOGIS ITU SENDIRI YANG AKHIRNYA RUNTUH。
Kepatuhan bukan sebuah patch, tetapi sebuah periode struktur pengikat: Garis dasar keamanannya adalah enkripsi end-to-end, manajemen kunci berlapis dan rotasi siklus, superimproving Hashi dan Merkle berjanji untuk memastikan bahwa download dapat divalidasi dan multiple copy dan didekode digabungkan untuk menutupi pemulihan kegagalan; privasi side-by-side minimal access control berdasarkan tingkat data, mendukung penarikan otorisasi, otorisasi one-time dan time-barred, meninggalkan tanda pada akses kritis dan operasi sebagai link keseluruhan untuk memfasilitasi audit backplay. Compliance juga merupakan link yang paling rentan dan mahal: Lokalisasi data dan strategi transmisi cross-domain perlu dikonfigurasi, dengan antarmuka proses standar untuk penghapusan, akses, dan permintaan audit; yang paling sulit adalah untuk tidak merusak konflik alami yang dapat dihapus, dengan solusi feasible yang dienkripsi mengelap dan mengindeks tidak valid: penghancuran kunci membuat teks rahasia tidak dapat dipulihkan, merender data yang tidak dapat diperbaiki, dan memuaskan klaim penghapusan dengan tetap mencatat catatan pada rantai. Ada tiga tahap dari ambang batas dari pilot ke produksi: pertama, loop tertutup kredibel minimum ditetapkan, penyimpanan objek, jangkar rantai, verifikasi kelengkapan dan kontrol dasar distabilkan, penerimaan tersedia, tingkat keberhasilan membaca dan menulis, penambatan dijajarkan dengan versi objek, pemulihan gagal dapat dilakukan; kemudian asetasi AI dan pengawasan indexing diimplementasikan, dataset dan manajemen aset model diperkenalkan, spektrum versi, pengindeksan vektor panas dan lapisan dingin, otorisasi model untuk memanggil dan melatih data terdaftar, menerima pelatihan inspeksi adalah traceable, model rerollable, pelapisan panas, audit complansi, rekonstruksi terkontrol; terakhir, rerietvalance dan otomatis diatur, sertifikasi yang valid, dan sertifikasi yang diperkenalkan secara otomatis, dan recovery revalance, dan recovery recovery recovery erroration, recovery recomplement, recomplement, recomplement recomplent recompleteable forgement, recomoption, recomplete cooption, recomoption, recomoption, recomplete cost recomoption, recomoption, recomoption, recom Sistem penunjukan kata adalah sistem strategis dan bukan laporan presentasi. Program penyimpanan telah runtuh menjadi pusat biaya murni jika hanya barang-barang teknis yang ditulis, tanpa hasil bisnis; rekomendasi dibuat dalam tiga tiers: indikator teknis yang mendasari (availability, P95/P99 time delay, throughput, RTO/RPO, error rate) menjawab kesehatan sistem, AI indikator spesifik (training data tracability rate, model recoverability rate, penalaran validation coverage, indeks konsistensi) menjawab kualitas model, indikator hasil operasional (peningkatan, pengurangan biaya panggilan, nodal activity, trading activity) jawaban sistem, dan ada pemetaan antara lapisan, penggunaan indikator nyata menjadi sebuah pernyataan masukan yang strategis. Lima titik kegagalan yang paling umum sebagian besar circuvented maju: penyimpanan tanpa pemerintahan versi, data bukan perwakilan ketersediaan, ketersediaan atau pengulangan; kapasitas saja tidak didukung oleh bukti ketersediaan, dan imbalan disediakan oleh volume untuk menginduksi cahaya kapasitas stack; panas dan lapisan dingin dilakukan tetapi tidak ada strategi sinkron dilakukan, dan versi indeks tidak ditutup; strategi compliance diikuti oleh biaya yang lebih besar dari hak istimewa, buku log, dissenitisasi, penghapusan respon akhir; struktur transisi tidak keluar dan sentralisasi adalah jalur yang masuk akal, tetapi migrasi memungkinkan transisi untuk berangkat dan tujuan mereka。
Cincin tertutup penuh untuk Bitroot: dari data, model ke AI Agen
Dalam cincin ini, Bitroot dapat mengubah setiap tindakan kunci aset AI menjadi suatu peristiwa penyelesaian: Pendaftaran Dataset, rilis model, rekonstruksi indeks vektor, panggilan AI Agen, penambatan log penalaran, delegasi otoritas dan pembatalan, tantangan sengketa dan hasil arbitrase. rantai tidak perlu berisi semua data, tetapi bukti terkecil dari tindakan ini. Hanya dengan cara ini, hubungan nilai antara data, model, algoritma dan aplikasi akan melampaui komitmen verbal untuk memprogram sub-akuntabel dan mengatur audit。
Untuk menempatkan mekanisme ini dalam ekspansi operasional dan ekologi Bitroot, insentif penyimpanan tidak harus dirancang sebagai subsidi perangkat keras terpisah, tetapi harus menjadi bagian dari aliran AI Stack: Kontributor data menerima manfaat dari pelatihan atau transfer data, kontributor model menerima manfaat dari layanan model, penyimpanan dan node penerimaan manfaat dari ketersediaan berkelanjutan dan penundaan rendah dalam layanan, sertifikasi dan node tantangan dihargai untuk menemukan non-availability, indeks drift atau anomali izin. Dengan cara ini, sistem ekonomi Bitroot memberikan imbalan bukan dengan mengunggah, melainkan dengan \"terus terbukti berguna\"。
Penyimpanan bukan pusat biaya, tetapi sistem distribusi kepercayaan dan nilai
PENYIMPANAN AGIHAN AI DI ERA AI ALAMAT BUKAN PENGGANTIAN PRODUK PENYIMPANAN OBJEK, MAUPUN PENGEJARAN NARASI YANG LAYAK, TETAPI EMPAT HAL YANG LEBIH KERAS: BUKTI KREDIBEL YANG TERSEDIA DARI WAKTU KE WAKTU, SUSUNAN PEMERINTAHAN YANG BEKERJA DI SELURUH SUBJEK, RANTAI TANGGUNG JAWAB UNTUK DATA DAN MODEL, DAN INSENTIF EKONOMI BERKELANJUTAN。
STRUKTUR SINGLE-AGREMEN TUNGGAL LAPISAN TIDAK MELIPUTI TUJUAN INI. JALUR YANG LEBIH REALISTIS ADALAH STRUKTUR MODULAR: INTEGRITAS SITUS KONTEN, BUKTI PENYIMPANAN KETERSEDIAAN DIMENSI WAKTU KEAMANAN, LAPISAN PERMANEN SEJARAH KRITIS, TERMOSFER ON-LINE PENGALAMAN, RANTAI JANGKAR UNTUK MENGAMANKAN PEMERINTAHAN DAN IZIN. INI BUKAN KOMPROMI, ITU ALASAN TEKNIK. FOKUS PENDARATAN JUGA BUKAN YANG PALING FUNGSIONAL, TETAPI PERTAMA KALI DIDIRIKAN DI LINGKARAN TERTUTUP, DENGAN LINGKARAN TERTUTUP KREDIBEL TERKECIL BERJALAN PERTAMA, DIIKUTI DENGAN ASETISASI AI, RETRIVAL TERVERIFIKASI DAN PEMERINTAHAN OTOMATIS SUPERIMPOSED。
INI OPERASI TIGA LANGKAH. HARI PERTAMA MELENGKAPKAN INVENTARIS DATA DELAPAN LAPANGAN, HARI KETIGA MENJALANKAN LINK MINIMUM DARI AKSES, PENYIMPANAN, PENGAMBILAN KEMBALI KE VALIDASI DI AREA BISNIS NYATA, DAN HARI KETUJUH MENJALANKAN PUTARAN AMBANG MIGRASI PADA P95 WAKTU DAN BIAYA UNIT. DENGAN MELAKUKANNYA, TIM PINDAH DARI KONSEPTUAL KE KONSENSUS TEKNIK。
Ada juga batas realistis untuk diakui: terlepas dari kombinasi perjanjian, ada perdagangan-off antara biaya, durasi dan keawetan, dan tidak ada jawaban tunggal yang optimal untuk semua operasi. Programme yang benar-benar berkelanjutan berasal dari pola iteratif berkelanjutan di bawah perbatasan yang jelas, daripada konfigurasi statik jangka panjang setelah sebuah papan。
FASE-OUT PROYEK YANG AKAN DATANG SERING KALI TIDAK TERLALU TINGGI UNTUK TPS, TETAPI RANTAI LIABILITAS DATA TIDAK JELAS; DI ERA AI, PENYIMPANAN BUKAN TENTANG MENEMPATKAN DATA DALAM, TETAPI LEBIH MEMUNGKINKAN DATA UNTUK DIBUKTIKAN SETIAP SAAT。
Kata-kata palsu
Kompetisi AI-chain nyata tidak berakhir dibandingkan dengan TPS, Gas atau waktu konfirmasi. Prestasi adalah pintu masuk, tapi bukan akhir. Setelah memasuki usia peralatan AI, sistem rantai dimaksudkan untuk tidak hanya membawa transaksi, tetapi juga versi data, panggilan model, algoritme, catatan penalaran, perilaku Agen dan multiple distribusi hasil。
Ini juga penilaian Bitroot dari waduk: penyimpanan bukan modul ansilarium, tetapi lapisan terdekat AI Stack ke sumber nilai. Apakah data dapat dibuktikan, apakah model dapat direproduksi, apakah panggilan dapat diaudit, apakah hasil dapat didistribusikan secara otomatis, atau apakah jaringan AI layak benar-benar layak dalam jangka panjang。
Bitroot tidak akan membangun rantai yang hanya mengejar implementasi lebih cepat, tetapi infrastruktur yang memungkinkan aset AI diidentifikasi, disebut, dibersihkan dan diatur. Alamat EVM Paralel EVM dan Pipeline BFT yang membawa kapasitas acara rantai frekuensi tinggi, mendistribusikan penyimpanan dan mekanisme yang dapat diverifikasi alamat basis kepercayaan data AI dan model, sementara sub-akun yang dapat diprogram dan aturan rantai menerjemahkan kontribusi ke dalam insentif ekonomi berkelanjutan。
Saat AI Agent mulai bertindak atas nama pengguna, ketika model dan data mulai menjadi aset yang dapat dinegosiasikan, penyimpanan tidak lagi menjadi pertanyaan oftempat untuk menempatkan berkas " ketika komputasi, layanan penyimpanan dan penalaran memasuki jaringan nilai yang sama。
INI AKAN MENJADI BASIS KEPERCAYAAN DARI RANTAI PUBLIK AI DAN SISTEM DISTRIBUSI NILAI DARI GENERASI BERIKUTNYA JARINGAN CERDAS。
Di Bitroot, tampaknya pentingnya masa depan bukanlah yang memiliki data terbanyak, tetapi siapa yang dapat membuatnya terbukti, dapat diakses, dapat dipertanggungjawabkan pada waktu tertentu dan akhirnya berpartisipasi dalam penyelesaian nilai。
Perihal Bitroot
AI asli struktur. Bitroot berbiaya rendah menggunakan rute teknologi yang kompatibel EVM dan menjelajahi lingkungan implementasi berperforman tinggi, berbiaya rendah untuk aplikasi AI Agent, DeFi dan Web3 melalui mekanisme implementasi paralel, optimasi konsensus dan desain antarmuka AI。
Kertas ini berasal dari sumbangan dan tidak mewakili sudut pandang Black Beats。
